Noticias
Agentes de motor de búsqueda multimodal alimentados por Blip-2 y Gemini

Esta publicación fue coautora de Rafael Groedes.
Introducción
Los modelos tradicionales solo pueden procesar un solo tipo de datos, como texto, imágenes o datos tabulares. La multimodalidad es un concepto de tendencia en la comunidad de investigación de IA, que se refiere a la capacidad de un modelo para aprender de múltiples tipos de datos simultáneamente. Esta nueva tecnología (no es realmente nueva, pero mejoró significativamente en los últimos meses) tiene numerosas aplicaciones potenciales que transformarán la experiencia del usuario de muchos productos.
Un buen ejemplo sería la nueva forma en que los motores de búsqueda funcionarán en el futuro, donde los usuarios pueden ingresar consultas utilizando una combinación de modalidades, como texto, imágenes, audio, etc. Otro ejemplo podría ser mejorar los sistemas de atención al cliente con AI para la voz. e entradas de texto. En el comercio electrónico, están mejorando el descubrimiento de productos al permitir a los usuarios buscar usando imágenes y texto. Usaremos este último como nuestro estudio de caso en este artículo.
Los laboratorios de investigación de IA Frontier están enviando varios modelos que admiten múltiples modalidades cada mes. Clip y Dall-E por OpenAI y Blip-2 por Salesforce Combine Image and Text. ImageBind por meta expandió el concepto de modalidad múltiple a seis modalidades (texto, audio, profundidad, térmica, imagen y unidades de medición inerciales).
En este artículo, exploraremos Blip-2 explicando su arquitectura, la forma en que funciona su función de pérdida y su proceso de capacitación. También presentamos un caso de uso práctico que combina Blip-2 y Gemini para crear un agente de búsqueda de moda multimodal que pueda ayudar a los clientes a encontrar el mejor atuendo basado en texto o mensajes de texto e indicaciones de imagen.


Como siempre, el código está disponible en nuestro GitHub.
Blip-2: un modelo multimodal
Blip-2 (pre-entrenamiento de imagen de lenguaje de arranque) [1] es un modelo de lenguaje de visión diseñado para resolver tareas como la respuesta de las preguntas visuales o el razonamiento multimodal basado en entradas de ambas modalidades: imagen y texto. Como veremos a continuación, este modelo se desarrolló para abordar dos desafíos principales en el dominio del idioma de la visión:
- Reducir el costo computacional Utilizando codificadores visuales pre-entrenados congelados y LLM, reduciendo drásticamente los recursos de capacitación necesarios en comparación con una capacitación conjunta de redes de visión e idiomas.
- Mejora de la alineación del idioma visual Al introducir Q-former. Q-Former acerca los incrustaciones visuales y textuales, lo que lleva a un mejor rendimiento de la tarea de razonamiento y la capacidad de realizar una recuperación multimodal.
Arquitectura
La arquitectura de Blip-2 sigue un diseño modular que integra tres módulos:
- Visual Codificador es un modelo visual congelado, como VIT, que extrae incrustaciones visuales de las imágenes de entrada (que luego se usan en tareas aguas abajo).
- Consulta Transformador (Q-Former) es la clave de esta arquitectura. Consiste en un transformador ligero entrenable que actúa como una capa intermedia entre los modelos visuales y de lenguaje. Es responsable de generar consultas contextualizadas a partir de los incrustaciones visuales para que el modelo de lenguaje pueda procesarlos de manera efectiva.
- LLM es un LLM pre-capacitado congelado que procesa incrustaciones visuales refinadas para generar descripciones o respuestas textuales.

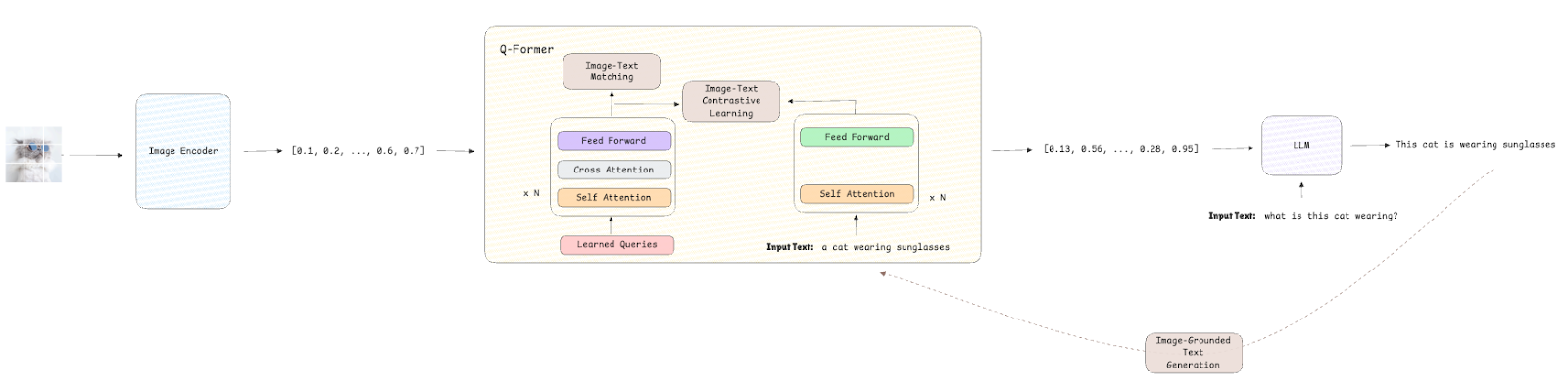
Funciones de pérdida
Blip-2 tiene tres funciones de pérdida para entrenar el Q-formador módulo:
- Pérdida de texto de texto [2] Haga cumplir la alineación entre los incrustaciones visuales y de texto maximizando la similitud de las representaciones emparejadas de texto de imagen mientras se separa pares diferentes.
- Pérdida de coincidencia de texto de imagen [3] es una pérdida de clasificación binaria que tiene como objetivo hacer que el modelo aprenda alineaciones de grano fino predecir si una descripción de texto coincide con la imagen (positivo, es decir, objetivo = 1) o no (negativo, es decir, objetivo = 0).
- Pérdida de generación de texto con conexión a imagen [4] es una pérdida de entropía cruzada utilizada en LLM para predecir la probabilidad del siguiente token en la secuencia. La arquitectura Q-former no permite interacciones entre los incrustaciones de la imagen y los tokens de texto; Por lo tanto, el texto debe generarse basándose únicamente en la información visual, lo que obliga al modelo a extraer características visuales relevantes.
Para ambosPérdida de contraste de texto mago y Pérdida de coincidencia de texto de imagenlos autores utilizaron un muestreo negativo en lotes, lo que significa que si tenemos un tamaño por lotes de 512, cada par de texto de imagen tiene una muestra positiva y 511 muestras negativas. Este enfoque aumenta la eficiencia ya que las muestras negativas se toman del lote, y no hay necesidad de buscar todo el conjunto de datos. También proporciona un conjunto más diverso de comparaciones, lo que lleva a una mejor estimación de gradiente y una convergencia más rápida.

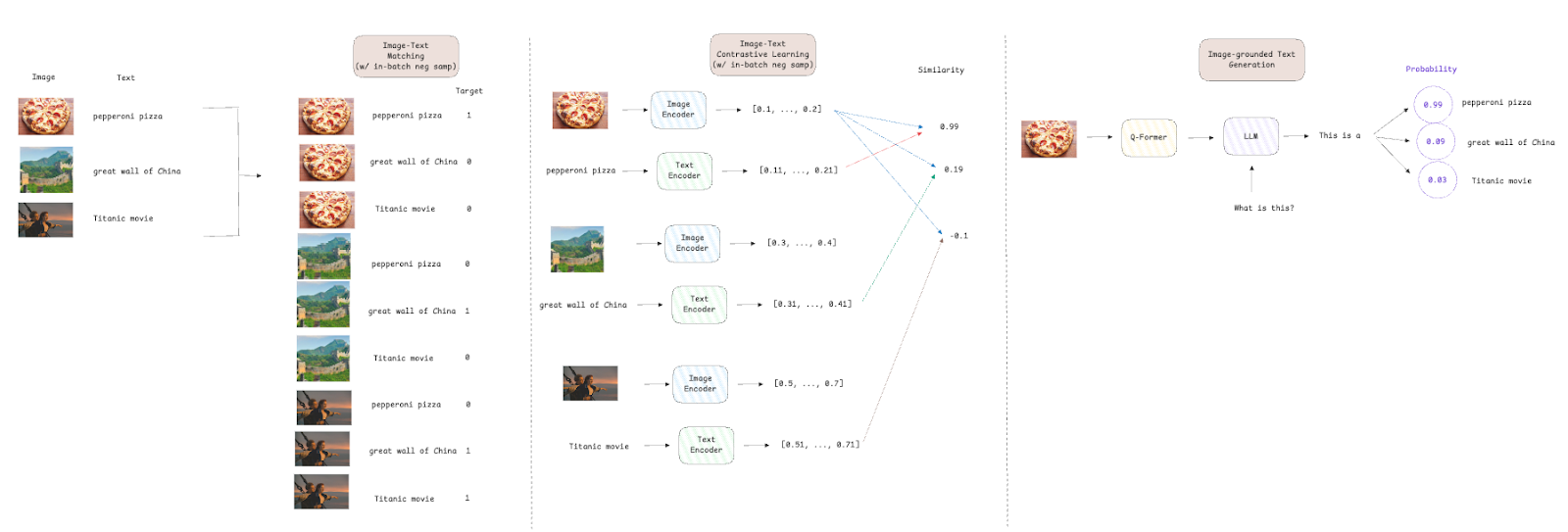
Proceso de capacitación
El entrenamiento de Blip-2 consta de dos etapas:
Etapa 1-Bootstrapping Representación visual en idioma:
- El modelo recibe imágenes como entrada que se convierten en una incrustación utilizando el codificador visual congelado.
- Junto con estas imágenes, el modelo recibe sus descripciones de texto, que también se convierten en incrustaciones.
- El Q-former está entrenado usando pérdida de texto de textoasegurando que las integridades visuales se alineen estrechamente con sus incrustaciones textuales correspondientes y se aleje más de las descripciones de texto que no coinciden. Al mismo tiempo, el Pérdida de coincidencia de texto de imagen Ayuda al modelo a desarrollar representaciones de grano fino aprendiendo a clasificar si un texto determinado describe correctamente la imagen o no.

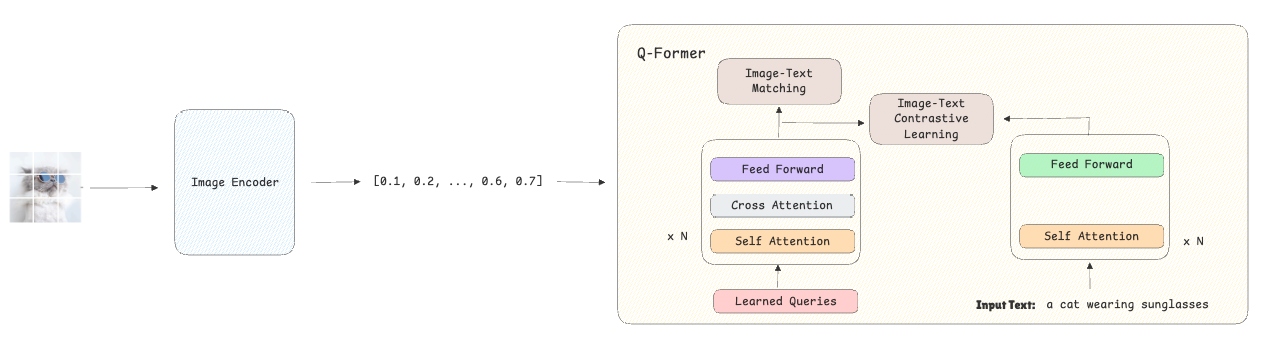
Etapa 2-Bootstrapping Vision-to Language Generation:
- El modelo de lenguaje previamente capacitado está integrado en la arquitectura para generar texto basado en las representaciones previamente aprendidas.
- El enfoque cambia de la alineación a la generación de texto mediante el uso de la pérdida de generación de texto con conexión a imagen que mejora las capacidades del modelo de razonamiento y generación de texto.

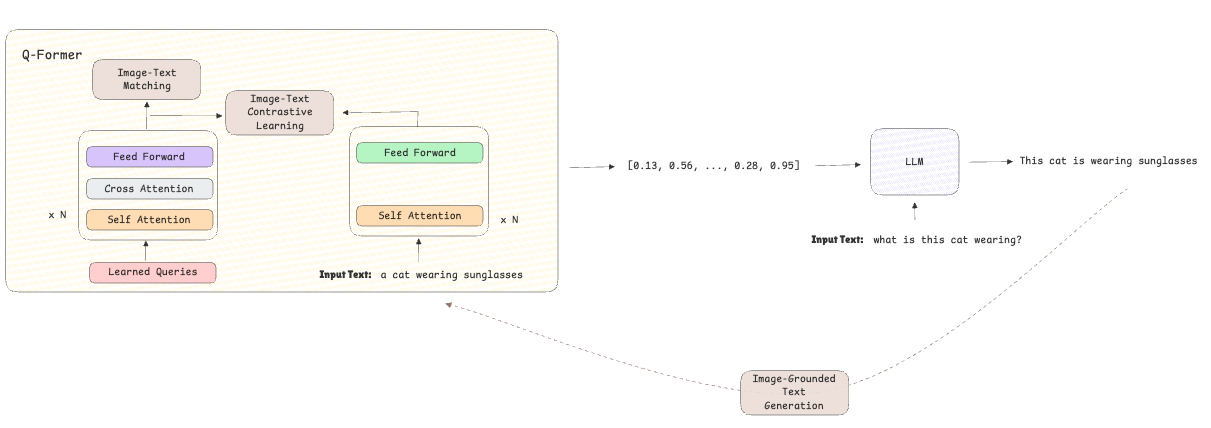
Creación de un agente de búsqueda de moda multimodal usando Blip-2 y Gemini
En esta sección, aprovecharemos las capacidades multimodales de Blip-2 para construir un agente de búsqueda de asistente de moda que pueda recibir texto de entrada y/o imágenes y recomendaciones de devolver. Para las capacidades de conversación del agente, utilizaremos Gemini 1.5 Pro alojado en Vertex AI, y para la interfaz, construiremos una aplicación de transmisión.
El conjunto de datos de moda utilizado en este caso de uso tiene licencia bajo la licencia MIT y se puede acceder a través del siguiente enlace: conjunto de datos de imágenes de productos de moda. Consiste en más de 44k imágenes de productos de moda.
El primer paso para hacer esto posible es configurar un Vector DB. Esto permite al agente realizar una búsqueda vectorizada basada en los incrustaciones de la imagen de los elementos disponibles en la tienda y los incrustaciones de texto o imagen de la entrada. Utilizamos Docker y Docker-Compose para ayudarnos a establecer el medio ambiente:
- Compuesto de acopolador con Postgres (la base de datos) y la extensión PGVector que permite la búsqueda vectorizada.
services:
postgres:
container_name: container-pg
image: ankane/pgvector
hostname: localhost
ports:
- "5432:5432"
env_file:
- ./env/postgres.env
volumes:
- postgres-data:/var/lib/postgresql/data
restart: unless-stopped
pgadmin:
container_name: container-pgadmin
image: dpage/pgadmin4
depends_on:
- postgres
ports:
- "5050:80"
env_file:
- ./env/pgadmin.env
restart: unless-stopped
volumes:
postgres-data:- Archivo env enviado con las variables para iniciar sesión en la base de datos.
POSTGRES_DB=postgres
POSTGRES_USER=admin
POSTGRES_PASSWORD=root- Archivo env envado con las variables para iniciar sesión en la interfaz de usuario para consultar manual la base de datos (opcional).
[email protected]
PGADMIN_DEFAULT_PASSWORD=root- Archivo ENV de conexión con todos los componentes para usar para conectarse a PGVector usando Langchain.
DRIVER=psycopg
HOST=localhost
PORT=5432
DATABASE=postgres
USERNAME=admin
PASSWORD=rootUna vez que el Vector DB está configurado (Docker -Compose Up -D), es hora de crear los agentes y herramientas para realizar una búsqueda multimodal. Construimos dos agentes para resolver este caso de uso: uno para comprender lo que el usuario solicita y otro para proporcionar la recomendación:
- El clasificador es responsable de recibir el mensaje de entrada del cliente y extraer qué categoría de ropa está buscando, por ejemplo, camisetas, pantalones, zapatos, camisetas o camisas. También devolverá la cantidad de artículos que el cliente desea para que podamos recuperar el número exacto del Vector DB.
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_google_vertexai import ChatVertexAI
from pydantic import BaseModel, Field
class ClassifierOutput(BaseModel):
"""
Data structure for the model's output.
"""
category: list = Field(
description="A list of clothes category to search for ('t-shirt', 'pants', 'shoes', 'jersey', 'shirt')."
)
number_of_items: int = Field(description="The number of items we should retrieve.")
class Classifier:
"""
Classifier class for classification of input text.
"""
def __init__(self, model: ChatVertexAI) -> None:
"""
Initialize the Chain class by creating the chain.
Args:
model (ChatVertexAI): The LLM model.
"""
super().__init__()
parser = PydanticOutputParser(pydantic_object=ClassifierOutput)
text_prompt = """
You are a fashion assistant expert on understanding what a customer needs and on extracting the category or categories of clothes a customer wants from the given text.
Text:
text
Instructions:
1. Read carefully the text.
2. Extract the category or categories of clothes the customer is looking for, it can be:
- t-shirt if the custimer is looking for a t-shirt.
- pants if the customer is looking for pants.
- jacket if the customer is looking for a jacket.
- shoes if the customer is looking for shoes.
- jersey if the customer is looking for a jersey.
- shirt if the customer is looking for a shirt.
3. If the customer is looking for multiple items of the same category, return the number of items we should retrieve. If not specfied but the user asked for more than 1, return 2.
4. If the customer is looking for multiple category, the number of items should be 1.
5. Return a valid JSON with the categories found, the key must be 'category' and the value must be a list with the categories found and 'number_of_items' with the number of items we should retrieve.
Provide the output as a valid JSON object without any additional formatting, such as backticks or extra text. Ensure the JSON is correctly structured according to the schema provided below.
format_instructions
Answer:
"""
prompt = PromptTemplate.from_template(
text_prompt, partial_variables="format_instructions": parser.get_format_instructions()
)
self.chain = prompt | model | parser
def classify(self, text: str) -> ClassifierOutput:
"""
Get the category from the model based on the text context.
Args:
text (str): user message.
Returns:
ClassifierOutput: The model's answer.
"""
try:
return self.chain.invoke("text": text)
except Exception as e:
raise RuntimeError(f"Error invoking the chain: e")
- El asistente es responsable de responder con una recomendación personalizada recuperada del Vector DB. En este caso, también estamos aprovechando las capacidades multimodales de Gemini para analizar las imágenes recuperadas y producir una mejor respuesta.
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_google_vertexai import ChatVertexAI
from pydantic import BaseModel, Field
class AssistantOutput(BaseModel):
"""
Data structure for the model's output.
"""
answer: str = Field(description="A string with the fashion advice for the customer.")
class Assistant:
"""
Assitant class for providing fashion advice.
"""
def __init__(self, model: ChatVertexAI) -> None:
"""
Initialize the Chain class by creating the chain.
Args:
model (ChatVertexAI): The LLM model.
"""
super().__init__()
parser = PydanticOutputParser(pydantic_object=AssistantOutput)
text_prompt = """
You work for a fashion store and you are a fashion assistant expert on understanding what a customer needs.
Based on the items that are available in the store and the customer message below, provide a fashion advice for the customer.
Number of items: number_of_items
Images of items:
items
Customer message:
customer_message
Instructions:
1. Check carefully the images provided.
2. Read carefully the customer needs.
3. Provide a fashion advice for the customer based on the items and customer message.
4. Return a valid JSON with the advice, the key must be 'answer' and the value must be a string with your advice.
Provide the output as a valid JSON object without any additional formatting, such as backticks or extra text. Ensure the JSON is correctly structured according to the schema provided below.
format_instructions
Answer:
"""
prompt = PromptTemplate.from_template(
text_prompt, partial_variables="format_instructions": parser.get_format_instructions()
)
self.chain = prompt | model | parser
def get_advice(self, text: str, items: list, number_of_items: int) -> AssistantOutput:
"""
Get advice from the model based on the text and items context.
Args:
text (str): user message.
items (list): items found for the customer.
number_of_items (int): number of items to be retrieved.
Returns:
AssistantOutput: The model's answer.
"""
try:
return self.chain.invoke("customer_message": text, "items": items, "number_of_items": number_of_items)
except Exception as e:
raise RuntimeError(f"Error invoking the chain: e")
En términos de herramientas, definimos uno basado en Blip-2. Consiste en una función que recibe un texto o imagen como entrada y devuelve incrustaciones normalizadas. Dependiendo de la entrada, los incrustaciones se producen utilizando el modelo de incrustación de texto o el modelo de incrustación de imagen de Blip-2.
from typing import Optional
import numpy as np
import torch
import torch.nn.functional as F
from PIL import Image
from PIL.JpegImagePlugin import JpegImageFile
from transformers import AutoProcessor, Blip2TextModelWithProjection, Blip2VisionModelWithProjection
PROCESSOR = AutoProcessor.from_pretrained("Salesforce/blip2-itm-vit-g")
TEXT_MODEL = Blip2TextModelWithProjection.from_pretrained("Salesforce/blip2-itm-vit-g", torch_dtype=torch.float32).to(
"cpu"
)
IMAGE_MODEL = Blip2VisionModelWithProjection.from_pretrained(
"Salesforce/blip2-itm-vit-g", torch_dtype=torch.float32
).to("cpu")
def generate_embeddings(text: Optional[str] = None, image: Optional[JpegImageFile] = None) -> np.ndarray:
"""
Generate embeddings from text or image using the Blip2 model.
Args:
text (Optional[str]): customer input text
image (Optional[Image]): customer input image
Returns:
np.ndarray: embedding vector
"""
if text:
inputs = PROCESSOR(text=text, return_tensors="pt").to("cpu")
outputs = TEXT_MODEL(**inputs)
embedding = F.normalize(outputs.text_embeds, p=2, dim=1)[:, 0, :].detach().numpy().flatten()
else:
inputs = PROCESSOR(images=image, return_tensors="pt").to("cpu", torch.float16)
outputs = IMAGE_MODEL(**inputs)
embedding = F.normalize(outputs.image_embeds, p=2, dim=1).mean(dim=1).detach().numpy().flatten()
return embedding
Tenga en cuenta que creamos la conexión a PGVector con un modelo de incrustación diferente porque es obligatorio, aunque no se utilizará ya que almacenaremos los incrustaciones producidos por Blip-2 directamente.
En el ciclo a continuación, iteramos sobre todas las categorías de ropa, cargamos las imágenes y creamos y agreguamos las incrustaciones que se almacenarán en el Vector DB en una lista. Además, almacenamos la ruta a la imagen como texto para que podamos representarla en nuestra aplicación de transmisión. Finalmente, almacenamos la categoría para filtrar los resultados en función de la categoría predicha por el agente del clasificador.
import glob
import os
from dotenv import load_dotenv
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from langchain_postgres.vectorstores import PGVector
from PIL import Image
from blip2 import generate_embeddings
load_dotenv("env/connection.env")
CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.getenv("DRIVER"),
host=os.getenv("HOST"),
port=os.getenv("PORT"),
database=os.getenv("DATABASE"),
user=os.getenv("USERNAME"),
password=os.getenv("PASSWORD"),
)
vector_db = PGVector(
embeddings=HuggingFaceEmbeddings(model_name="nomic-ai/modernbert-embed-base"), # does not matter for our use case
collection_name="fashion",
connection=CONNECTION_STRING,
use_jsonb=True,
)
if __name__ == "__main__":
# generate image embeddings
# save path to image in text
# save category in metadata
texts = []
embeddings = []
metadatas = []
for category in glob.glob("images/*"):
cat = category.split("/")[-1]
for img in glob.glob(f"category/*"):
texts.append(img)
embeddings.append(generate_embeddings(image=Image.open(img)).tolist())
metadatas.append("category": cat)
vector_db.add_embeddings(texts, embeddings, metadatas)Ahora podemos construir nuestra aplicación aerodinámica para chatear con nuestro asistente y pedir recomendaciones. El chat comienza con el agente preguntando cómo puede ayudar y proporcionar un cuadro para que el cliente escriba un mensaje y/o cargue un archivo.
Una vez que el cliente responde, el flujo de trabajo es el siguiente:
- El agente del clasificador identifica qué categorías de ropa está buscando el cliente y cuántas unidades desean.
- Si el cliente carga un archivo, este archivo se convertirá en una incrustación, y buscaremos elementos similares en el Vector DB, condicionado por la categoría de ropa que el cliente desea y la cantidad de unidades.
- Los elementos recuperados y el mensaje de entrada del cliente se envían al agente asistente para producir el mensaje de recomendación que se transforma junto con las imágenes recuperadas.
- Si el cliente no cargó un archivo, el proceso es el mismo, pero en lugar de generar insertos de imagen para la recuperación, creamos incrustaciones de texto.
import os
import streamlit as st
from dotenv import load_dotenv
from langchain_google_vertexai import ChatVertexAI
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from langchain_postgres.vectorstores import PGVector
from PIL import Image
import utils
from assistant import Assistant
from blip2 import generate_embeddings
from classifier import Classifier
load_dotenv("env/connection.env")
load_dotenv("env/llm.env")
CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.getenv("DRIVER"),
host=os.getenv("HOST"),
port=os.getenv("PORT"),
database=os.getenv("DATABASE"),
user=os.getenv("USERNAME"),
password=os.getenv("PASSWORD"),
)
vector_db = PGVector(
embeddings=HuggingFaceEmbeddings(model_name="nomic-ai/modernbert-embed-base"), # does not matter for our use case
collection_name="fashion",
connection=CONNECTION_STRING,
use_jsonb=True,
)
model = ChatVertexAI(model_name=os.getenv("MODEL_NAME"), project=os.getenv("PROJECT_ID"), temperarture=0.0)
classifier = Classifier(model)
assistant = Assistant(model)
st.title("Welcome to ZAAI's Fashion Assistant")
user_input = st.text_input("Hi, I'm ZAAI's Fashion Assistant. How can I help you today?")
uploaded_file = st.file_uploader("Upload an image", type=["jpg", "jpeg", "png"])
if st.button("Submit"):
# understand what the user is asking for
classification = classifier.classify(user_input)
if uploaded_file:
image = Image.open(uploaded_file)
image.save("input_image.jpg")
embedding = generate_embeddings(image=image)
else:
# create text embeddings in case the user does not upload an image
embedding = generate_embeddings(text=user_input)
# create a list of items to be retrieved and the path
retrieved_items = []
retrieved_items_path = []
for item in classification.category:
clothes = vector_db.similarity_search_by_vector(
embedding, k=classification.number_of_items, filter="category": "$in": [item]
)
for clothe in clothes:
retrieved_items.append("bytesBase64Encoded": utils.encode_image_to_base64(clothe.page_content))
retrieved_items_path.append(clothe.page_content)
# get assistant's recommendation
assistant_output = assistant.get_advice(user_input, retrieved_items, len(retrieved_items))
st.write(assistant_output.answer)
cols = st.columns(len(retrieved_items)+1)
for col, retrieved_item in zip(cols, ["input_image.jpg"]+retrieved_items_path):
col.image(retrieved_item)
user_input = st.text_input("")
else:
st.warning("Please provide text.")Ambos ejemplos se pueden ver a continuación:
La Figura 6 muestra un ejemplo en el que el cliente cargó una imagen de una camiseta roja y le pidió al agente que completara el atuendo.

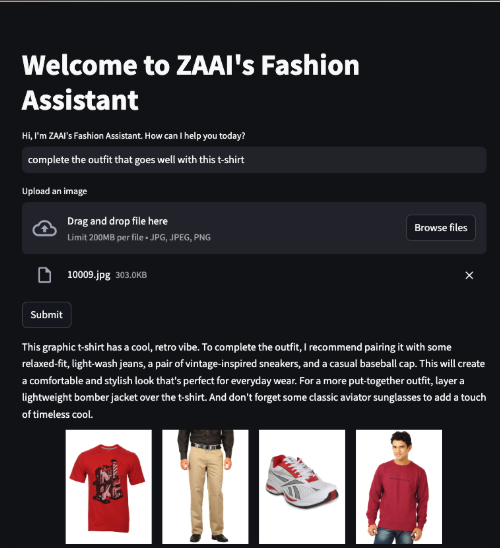
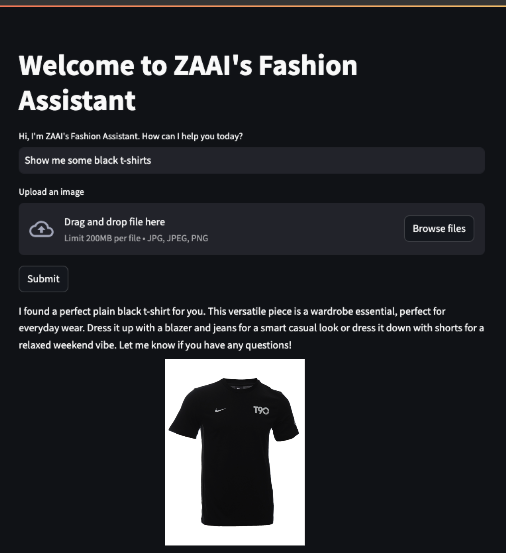
La Figura 7 muestra un ejemplo más directo en el que el cliente le pidió al agente que les mostrara camisetas negras.

Conclusión
La IA multimodal ya no es solo un tema de investigación. Se está utilizando en la industria para remodelar la forma en que los clientes interactúan con los catálogos de la empresa. En este artículo, exploramos cómo se pueden combinar modelos multimodales como Blip-2 y Gemini para abordar los problemas del mundo real y proporcionar una experiencia más personalizada a los clientes de una manera escalable.
Exploramos la arquitectura de Blip-2 en profundidad, demostrando cómo une la brecha entre las modalidades de texto y imagen. Para extender sus capacidades, desarrollamos un sistema de agentes, cada uno especializado en diferentes tareas. Este sistema integra un LLM (Gemini) y una base de datos vectorial, lo que permite la recuperación del catálogo de productos utilizando incrustaciones de texto e imágenes. También aprovechamos el razonamiento multimodal de Géminis para mejorar las respuestas del agente de ventas para ser más humanos.
Con herramientas como Blip-2, Gemini y PG Vector, el futuro de la búsqueda y recuperación multimodal ya está sucediendo, y los motores de búsqueda del futuro se verán muy diferentes de los que usamos hoy.
Acerca de mí
Empresario en serie y líder en el espacio de IA. Desarrollo productos de IA para empresas e invierto en nuevas empresas centradas en la IA.
Fundador @ Zaai | LinkedIn | X/Twitter
Referencias
[1] Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi. 2023. BLIP-2: Bootstrapping Language-Image Training con codificadores de imágenes congeladas y modelos de idiomas grandes. ARXIV: 2301.12597
[2] Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, CE Liu, Dilip Krishnan. 2020. Aprendizaje contrastante supervisado. ARXIV: 2004.11362
[3] Junnan Li, Rampasaath R. Selvaraju, Akhilesh Deepak Gotmare, Shafiq Joty, Caiming Xiong, Steven Hoi. 2021. Alinee antes del fusible: el aprendizaje de la representación del lenguaje y la visión con la destilación de impulso. ARXIV: 2107.07651
[4] Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, Hsiao-Wuen Hon. 2019. Modelo de lenguaje unificado Precrendimiento para la comprensión del lenguaje natural y la generación. ARXIV: 1905.03197