Noticias
API de Meta Oleleshes Llama que se ejecuta 18 veces más rápido que OpenAI: Cerebras Partnership ofrece 2.600 tokens por segundo
Únase a nuestros boletines diarios y semanales para obtener las últimas actualizaciones y contenido exclusivo sobre la cobertura de IA líder de la industria. Obtenga más información
Meta anunció hoy una asociación con Cerebras Systems para alimentar su nueva API de LLAMA, ofreciendo a los desarrolladores acceso a velocidades de inferencia hasta 18 veces más rápido que las soluciones tradicionales basadas en GPU.
El anuncio, realizado en la Conferencia inaugural de desarrolladores de Llamacon de Meta en Menlo Park, posiciona a la compañía para competir directamente con Operai, Anthrope y Google en el mercado de servicios de inferencia de IA en rápido crecimiento, donde los desarrolladores compran tokens por miles de millones para impulsar sus aplicaciones.
“Meta ha seleccionado a Cerebras para colaborar para ofrecer la inferencia ultra rápida que necesitan para servir a los desarrolladores a través de su nueva API de LLAMA”, dijo Julie Shin Choi, directora de marketing de Cerebras, durante una sesión de prensa. “En Cerebras estamos muy, muy emocionados de anunciar nuestra primera asociación HyperScaler CSP para ofrecer una inferencia ultra rápida a todos los desarrolladores”.
La asociación marca la entrada formal de Meta en el negocio de la venta de AI Computation, transformando sus populares modelos de llama de código abierto en un servicio comercial. Si bien los modelos de LLAMA de Meta se han acumulado en mil millones de descargas, hasta ahora la compañía no había ofrecido una infraestructura en la nube de primera parte para que los desarrolladores creen aplicaciones con ellos.
“Esto es muy emocionante, incluso sin hablar sobre cerebras específicamente”, dijo James Wang, un ejecutivo senior de Cerebras. “Openai, Anthrope, Google: han construido un nuevo negocio de IA completamente nuevo desde cero, que es el negocio de inferencia de IA. Los desarrolladores que están construyendo aplicaciones de IA comprarán tokens por millones, a veces por miles de millones. Y estas son como las nuevas instrucciones de cómputo que las personas necesitan para construir aplicaciones AI”.

Breaking the Speed Barrier: Cómo modelos de Llama de Cerebras Supercharges
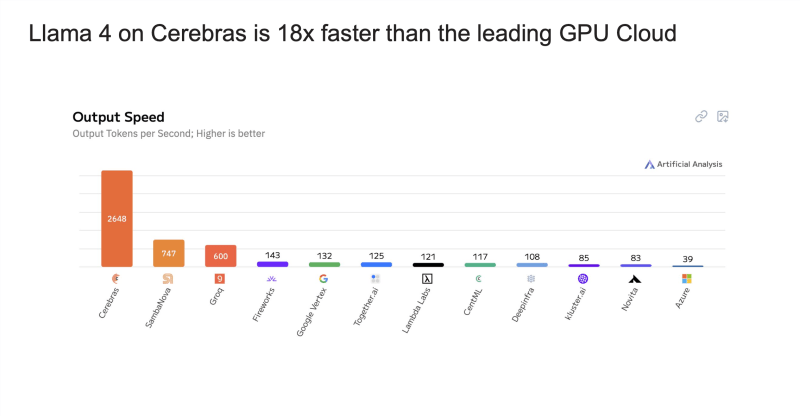
Lo que distingue a la oferta de Meta es el aumento de la velocidad dramática proporcionado por los chips de IA especializados de Cerebras. El sistema de cerebras ofrece más de 2.600 fichas por segundo para Llama 4 Scout, en comparación con aproximadamente 130 tokens por segundo para ChatGPT y alrededor de 25 tokens por segundo para Deepseek, según puntos de referencia del análisis artificial.
“Si solo se compara con API a API, Gemini y GPT, todos son grandes modelos, pero todos se ejecutan a velocidades de GPU, que son aproximadamente 100 tokens por segundo”, explicó Wang. “Y 100 tokens por segundo están bien para el chat, pero es muy lento para el razonamiento. Es muy lento para los agentes. Y la gente está luchando con eso hoy”.
Esta ventaja de velocidad permite categorías completamente nuevas de aplicaciones que antes no eran prácticas, incluidos los agentes en tiempo real, los sistemas de voz de baja latencia conversacional, la generación de código interactivo y el razonamiento instantáneo de múltiples pasos, todos los cuales requieren encadenamiento de múltiples llamadas de modelo de lenguaje grandes que ahora se pueden completar en segundos en lugar de minutos.
La API de LLAMA representa un cambio significativo en la estrategia de IA de Meta, en la transición de ser un proveedor de modelos a convertirse en una compañía de infraestructura de IA de servicio completo. Al ofrecer un servicio API, Meta está creando un flujo de ingresos a partir de sus inversiones de IA mientras mantiene su compromiso de abrir modelos.
“Meta ahora está en el negocio de vender tokens, y es excelente para el tipo de ecosistema de IA estadounidense”, señaló Wang durante la conferencia de prensa. “Traen mucho a la mesa”.
La API ofrecerá herramientas para el ajuste y la evaluación, comenzando con el modelo LLAMA 3.3 8B, permitiendo a los desarrolladores generar datos, entrenar y probar la calidad de sus modelos personalizados. Meta enfatiza que no utilizará datos de clientes para capacitar a sus propios modelos, y los modelos construidos con la API de LLAMA se pueden transferir a otros hosts, una clara diferenciación de los enfoques más cerrados de algunos competidores.
Las cerebras alimentarán el nuevo servicio de Meta a través de su red de centros de datos ubicados en toda América del Norte, incluidas las instalaciones en Dallas, Oklahoma, Minnesota, Montreal y California.
“Todos nuestros centros de datos que sirven a la inferencia están en América del Norte en este momento”, explicó Choi. “Serviremos Meta con toda la capacidad de las cerebras. La carga de trabajo se equilibrará en todos estos diferentes centros de datos”.
El arreglo comercial sigue lo que Choi describió como “el proveedor de cómputo clásico para un modelo hiperscalador”, similar a la forma en que NVIDIA proporciona hardware a los principales proveedores de la nube. “Están reservando bloques de nuestro cómputo para que puedan servir a su población de desarrolladores”, dijo.
Más allá de las cerebras, Meta también ha anunciado una asociación con Groq para proporcionar opciones de inferencia rápida, brindando a los desarrolladores múltiples alternativas de alto rendimiento más allá de la inferencia tradicional basada en GPU.
La entrada de Meta en el mercado de API de inferencia con métricas de rendimiento superiores podría potencialmente alterar el orden establecido dominado por Operai, Google y Anthrope. Al combinar la popularidad de sus modelos de código abierto con capacidades de inferencia dramáticamente más rápidas, Meta se está posicionando como un competidor formidable en el espacio comercial de IA.
“Meta está en una posición única con 3 mil millones de usuarios, centros de datos de hiper escala y un gran ecosistema de desarrolladores”, según los materiales de presentación de Cerebras. La integración de la tecnología de cerebras “ayuda a Meta Leapfrog OpenAi y Google en rendimiento en aproximadamente 20X”.
Para las cerebras, esta asociación representa un hito importante y la validación de su enfoque especializado de hardware de IA. “Hemos estado construyendo este motor a escala de obleas durante años, y siempre supimos que la primera tarifa de la tecnología, pero en última instancia tiene que terminar como parte de la nube de hiperescala de otra persona. Ese fue el objetivo final desde una perspectiva de estrategia comercial, y finalmente hemos alcanzado ese hito”, dijo Wang.
La API de LLAMA está actualmente disponible como una vista previa limitada, con Meta planifica un despliegue más amplio en las próximas semanas y meses. Los desarrolladores interesados en acceder a la inferencia Ultra-Fast Llama 4 pueden solicitar el acceso temprano seleccionando cerebras de las opciones del modelo dentro de la API de LLAMA.
“Si te imaginas a un desarrollador que no sabe nada sobre cerebras porque somos una empresa relativamente pequeña, solo pueden hacer clic en dos botones en el SDK estándar de SDK estándar de Meta, generar una tecla API, seleccionar la bandera de cerebras y luego, de repente, sus tokens se procesan en un motor gigante a escala de dafers”, explicó las cejas. “Ese tipo de hacernos estar en el back -end del ecosistema de desarrolladores de Meta todo el ecosistema es tremendo para nosotros”.
La elección de Meta de silicio especializada señala algo profundo: en la siguiente fase de la IA, no es solo lo que saben sus modelos, sino lo rápido que pueden pensarlo. En ese futuro, la velocidad no es solo una característica, es todo el punto.

