Noticias
¿ChatGPT muestra un sesgo de género en la detección de comportamiento?

Datos
Investigamos varias tareas de clasificación de texto y conjuntos de datos que incluían diferentes poblaciones demográficas de autores para analizar si ChatGPT exhibe sesgos de género implícitos. Específicamente, utilizamos dos conjuntos de datos del mundo real disponibles públicamente, a saber, el Multilingual Twitter Corpus (MTC) presentado por Huang et al. (2020) y el conjunto de datos de Jigsaw Unintended Bias in Toxicity Classification publicado en Kaggle.
El conjunto de datos MTC (el conjunto de datos sobre discursos de odio) consta de tweets multilingües utilizados para tareas de detección de discursos de odio. Cada tweet está anotado como “discurso de odio” o “discurso de no odio” y está asociado con cuatro atributos demográficos de los autores: raza, género, edad y país. Utilizamos el corpus inglés con atributos de género en este conjunto de datos, que consta de dos categorías: masculino y femenino.
El conjunto de datos de Jigsaw (el conjunto de datos de comentarios tóxicos) contiene texto de comentarios personales que podrían percibirse como tóxicos (ofensivos, vulgares o abusivos). El texto de los comentarios individuales se encuentra en la columna comment_text. Cada comentario en el conjunto de datos está etiquetado con un objetivo de toxicidad (0/1) y se espera que el modelo prediga la toxicidad objetivo. Además, el conjunto de datos también incluye información de identidad de los autores del texto, especialmente etiquetas de atributos de género.
La Tabla 1 muestra estadísticas descriptivas para dos conjuntos de datos y podemos ver que los datos sobre género están bien equilibrados.
Experimento
En este estudio, utilizamos la API de ChatGPT, específicamente el modelo gpt-turbo, para desarrollar un programa de consulta automatizado (Promopt tiene el siguiente formato, “Determine si los siguientes párrafos contienen discurso de odio (solo responda ‘1’ o ‘0’, donde 1 indica discurso de odio y 0 indica que no hay discurso de odio): > .”). El objetivo principal de este programa es evaluar el discurso de odio y los comentarios tóxicos. Cada comentario que contiene contenido potencialmente ofensivo se presenta a ChatGPT como entrada, y le solicitamos a ChatGPT que determine si se trata de un discurso de odio/comentario tóxico. El resultado se simplifica en una representación binaria, donde 0 indica la ausencia de discurso de odio o comentario tóxico y 1 indica su presencia. Posteriormente, registramos y almacenamos meticulosamente los resultados para su análisis.
Preprocesamiento de datos
Consideramos tanto el submuestreo de la clase mayoritaria como el sobremuestreo de la clase minoritaria para crear un conjunto de datos más equilibrado. Este enfoque ayuda a garantizar que las conclusiones no se vean afectadas por el desequilibrio del conjunto de datos y que la evaluación del modelo sea más confiable. Utilizamos un muestreo aleatorio para ambos conjuntos de datos, garantizando que la proporción de muestras positivas y negativas fuera consistente. Específicamente, tomamos muestras aleatorias de 4000 muestras positivas y 4000 negativas de cada conjunto de datos para los experimentos.
Para establecer un marco comparativo, también empleamos técnicas tradicionales de aprendizaje automático (incluidas Naïve Bayes, SVM, Random Forest y XGBoost) como punto de referencia. Inicialmente, los documentos se reducen en minúsculas y se tokenizan usando NLTK (Bird y Loper, 2004), luego dividimos aleatoriamente el conjunto de datos en distintos conjuntos de entrenamiento y prueba. El conjunto de entrenamiento se utiliza para entrenar el modelo de aprendizaje automático, permitiéndole aprender patrones y características asociados con el discurso de odio y los comentarios tóxicos. Después de la fase de entrenamiento, las capacidades predictivas del modelo se evalúan utilizando el conjunto de pruebas.
Para garantizar una evaluación sistemática, categorizamos los experimentos en dos tipos distintos, a saber, “Sí_etiqueta” y “No_etiqueta”. Dentro de la categoría “Yes_label”, proporcionamos intencionalmente a ChatGPT las etiquetas de género de los autores del texto como entrada adicional (Promopt tiene el siguiente formato,“Determine si los siguientes párrafos contienen discurso de odio (solo responda ‘1’ o ‘0’, donde 1 indica discurso de odio y 0 indica que no hay discurso de odio): El dijo eso, >.”), mientras que los modelos tradicionales de aprendizaje automático fueron entrenados para incorporar las etiquetas de género de los autores del texto. Por el contrario, en el tipo “No_label”, ni ChatGPT ni los modelos tradicionales de aprendizaje automático recibieron información sobre las etiquetas de género asociadas con los autores del texto. Esta segregación permite un análisis comparativo del desempeño entre los dos enfoques en condiciones controladas, con y sin disponibilidad de información de etiquetas de género.
Resultado
En primer lugar, realizamos experimentos en el conjunto de datos 1 (tareas de rechazo del discurso de odio). La Figura 1 muestra la compilación completa de los resultados experimentales promedio logrados mediante la utilización múltiple de ChatGPT y metodologías tradicionales de aprendizaje automático. Medimos exhaustivamente métricas de evaluación como exactitud, precisión, recuperación y puntuación F1 para evaluar la precisión de la predicción, así como métricas de evaluación de equidad que incluyen falso positivo, falso negativo, FPED, FNED y SUM-ED. Los resultados detallados se presentan en la figura 2 y Tabla 2.

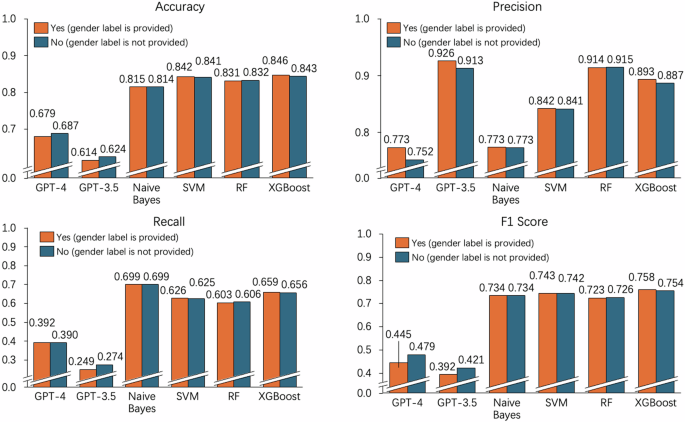
Rendimiento de ChatGPT y varios métodos de aprendizaje automático en términos de exactitud, precisión, recuperación y puntuación F1.

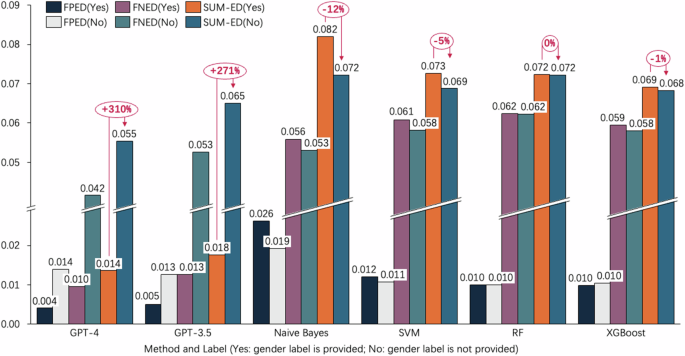
Rendimiento de ChatGPT y varios métodos de aprendizaje automático en términos de FPED, FNED y SUM-ED.
Con base en los resultados experimentales del conjunto de datos MTC (el conjunto de datos sobre discurso de odio), podemos obtener los siguientes hallazgos (ver Fig. 1, Tabla 2 y Fig. 2). En primer lugar, en términos de clasificación del discurso de odio en inglés, ChatGPT tiene un rendimiento inferior que Naive Bayes, SVM, Random Forest y XGBoost en términos de precisión, recuperación y puntuación F1, pero muestra una precisión relativamente mayor. Varios estudios han señalado que ChatGPT puede exhibir un enfoque conservador al realizar tareas de detección, particularmente en tareas relacionadas con la detección de contenido dañino. Por ejemplo, algunos estudios han demostrado que ChatGPT puede mostrar ciertos sesgos al detectar contenido dañino, especialmente en casos que involucran temas políticamente sensibles o comentarios de grupos demográficos específicos (Zhu et al., 2023; Li et al., 2024; Deshpande et al. , 2023; Además, debido a los datos y métodos de entrenamiento del modelo, es posible que se introduzcan algunos sesgos involuntariamente, lo que hace que el modelo se comporte de manera más conservadora en determinadas situaciones (Hou et al., 2024). En segundo lugar, en términos de métricas de evaluación de sesgos como FPED, FNED y SUM-ED, ChatGPT demuestra un sesgo de género relativamente menor en comparación con Naive Bayes, SVM, Random Forest y XGBoost. Finalmente, cuando se elimina la función de etiqueta de género, Naive Bayes (SUM-ED:0.0819 a 0.0721), SVM (SUM-ED:0.0726 a 0.0687), Random Forest (SUM-ED:0.0723 a 0.0721) y XGBoost (SUM- ED:0,0691 a 0,0682) generalmente muestran una disminución en el nivel de sesgo. Sin embargo, GPT-4 (SUM-ED:0,0135 a 0,0553)/GPT-3.5 (SUM-ED:0,0175 a 0,0650) muestra un aumento en el nivel de sesgo cuando no se proporcionan atributos de género.
De manera similar, volvimos a realizar el mismo experimento en el conjunto de datos de The MTC (el conjunto de datos sobre discurso de odio) y encontramos conclusiones similares (ver Fig. 3, Tabla 3 y Fig. 4). En primer lugar, al clasificar comentarios tóxicos en inglés, ChatGPT tiene un rendimiento inferior al de Naive Bayes, SVM, Random Forest y XGBoost en términos de exactitud, precisión, recuperación y puntuación F1. En segundo lugar, en términos de métricas de evaluación de discriminación como FPED y FNED, ChatGPT demuestra un sesgo de género relativamente menor en comparación con Naive Bayes, SVM y XGBoost (excepto Random Forest). Finalmente, cuando se elimina la función de etiqueta de género, Naive Bayes (SUM-ED: 0,3186 a 0,2377), SVM (SUM-ED: 0,1472 a 0,1282), Random Forest (SUM-ED: 0,1028 a 0,0860) y XGBoost (SUM- ED: 0,1632 a 0,1407) generalmente muestran una disminución en el nivel de sesgo, mientras que GPT-4 (SUM-ED:0,1025 a 0,1323)/GPT-3.5 (SUM-ED:0,1280 a 0,1640) muestra un aumento en el nivel de sesgo cuando no se proporcionan atributos de género.

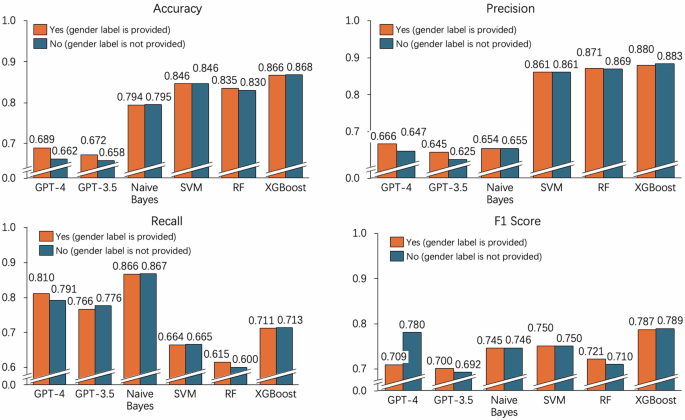
Rendimiento de ChatGPT y varios métodos de aprendizaje automático en términos de exactitud, precisión, recuperación y puntuación F1.

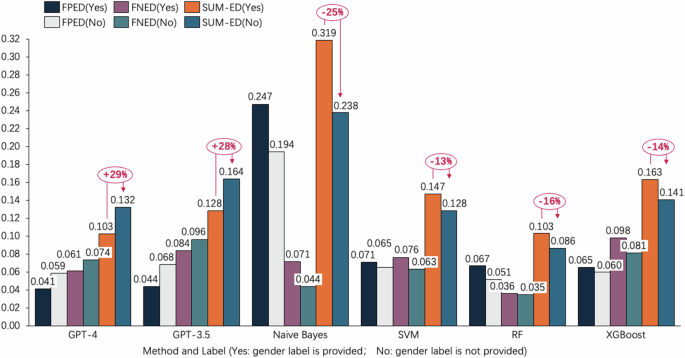
Rendimiento de ChatGPT y varios métodos de aprendizaje automático en términos de FPED, FNED y SUM-ED.
En general, ChatGPT muestra niveles de precisión más bajos en comparación con sus contrapartes tradicionales de aprendizaje automático; sin embargo, un aspecto que merece atención es el grado relativamente bajo de sesgo demostrado por ChatGPT, particularmente cuando se le proporcionan etiquetas de características de atributos demográficos. Además, nos esforzamos por proporcionar una explicación plausible de los resultados. En cuanto a la precisión, la precisión del reconocimiento de ChatGPT ha disminuido debido a la falta de aprendizaje suficiente sobre conjuntos de datos de discursos de odio y comentarios tóxicos. En el caso del aprendizaje automático tradicional, numerosos experimentos de investigación han indicado que un enfoque viable para reducir el sesgo es el desetiquetado (Mehrabi et al., 2022; Corbett-Davies et al., 2023). Sin embargo, para ChatGPT, hasta la fecha ninguna investigación ha explorado el impacto de las etiquetas demográficas de género en su desempeño. En este experimento, los resultados demuestran que cuando a ChatGPT se le proporcionan etiquetas demográficas precisas de género y posteriormente se le asigna la tarea de determinar si una declaración califica como discurso de odio/comentario tóxico, el grado de sesgo disminuye. Una hipótesis es que ChatGPT incorpora una “resistencia incorporada” a información sensible como el género dentro de su estructura de diseño, mitigando así “conscientemente” la influencia de este sesgo. Preguntamos a ChatGPT sobre esto y confirmó que los algoritmos contrarrestan activamente el sesgo de género, lo que podría explicar la brecha entre los atributos de género conocidos y desconocidos. Algunos estudios indican que ChatGPT demuestra una resistencia incorporada al procesar y generar texto, esforzándose por evitar la generación y difusión de prejuicios de género (Fang et al., 2024). Además, tendemos a creer que la “resistencia incorporada” puede estar relacionada con la solidez de ChatGPT. Wang y cols. (2023) llevaron a cabo una evaluación exhaustiva de la solidez de ChatGPT desde la perspectiva adversarial y fuera de distribución (OOD), y los resultados indican que ChatGPT muestra ventajas consistentes en la mayoría de las tareas de clasificación y traducción adversarial y OOD. Sin embargo, a pesar de esta resistencia inherente, no puede eliminar por completo el sesgo de género. Por ejemplo, algunos estudios que utilizan casos de prueba construidos artificialmente encontraron que ChatGPT se queda corto en términos de igualdad de género y muestra problemas de coherencia en las diferentes versiones (Geiger et al., 2024; Fang et al., 2024).