Noticias
DeepSeek-R1 de código abierto utiliza aprendizaje por refuerzo puro para igualar OpenAI o1, con un costo un 95 % menor

Únase a nuestros boletines diarios y semanales para obtener las últimas actualizaciones y contenido exclusivo sobre la cobertura de IA líder en la industria. Más información
La startup china de IA DeepSeek, conocida por desafiar a los principales proveedores de IA con tecnologías de código abierto, acaba de lanzar otra bomba: un nuevo LLM de razonamiento abierto llamado DeepSeek-R1.
Basado en el modelo de mezcla de expertos DeepSeek V3 recientemente introducido, DeepSeek-R1 iguala el rendimiento de o1, el LLM de razonamiento fronterizo de OpenAI, en tareas de matemáticas, codificación y razonamiento. ¿La mejor parte? Lo hace a un costo mucho más tentador, resultando ser entre un 90 y un 95% más asequible que este último.
El lanzamiento marca un gran paso adelante en el ámbito del código abierto. Muestra que los modelos abiertos están cerrando aún más la brecha con los modelos comerciales cerrados en la carrera hacia la inteligencia artificial general (AGI). Para mostrar la destreza de su trabajo, DeepSeek también utilizó R1 para destilar seis modelos Llama y Qwen, llevando su rendimiento a nuevos niveles. En un caso, la versión destilada de Qwen-1.5B superó a modelos mucho más grandes, GPT-4o y Claude 3.5 Sonnet, en pruebas comparativas matemáticas seleccionadas.
Estos modelos destilados, junto con el R1 principal, son de código abierto y están disponibles en Hugging Face bajo una licencia del MIT.
¿Qué aporta DeepSeek-R1?
La atención se está centrando en la inteligencia artificial general (AGI), un nivel de IA que puede realizar tareas intelectuales como los humanos. Muchos equipos están redoblando esfuerzos para mejorar las capacidades de razonamiento de los modelos. OpenAI dio el primer paso notable en este ámbito con su modelo o1, que utiliza un proceso de razonamiento en cadena de pensamiento para abordar un problema. A través del RL (aprendizaje por refuerzo u optimización impulsada por recompensas), o1 aprende a perfeccionar su cadena de pensamiento y refinar las estrategias que utiliza; en última instancia, aprende a reconocer y corregir sus errores, o a probar nuevos enfoques cuando los actuales no funcionan.
Ahora, continuando con el trabajo en esta dirección, DeepSeek ha lanzado DeepSeek-R1, que utiliza una combinación de RL y ajuste fino supervisado para manejar tareas de razonamiento complejas y igualar el rendimiento de o1.
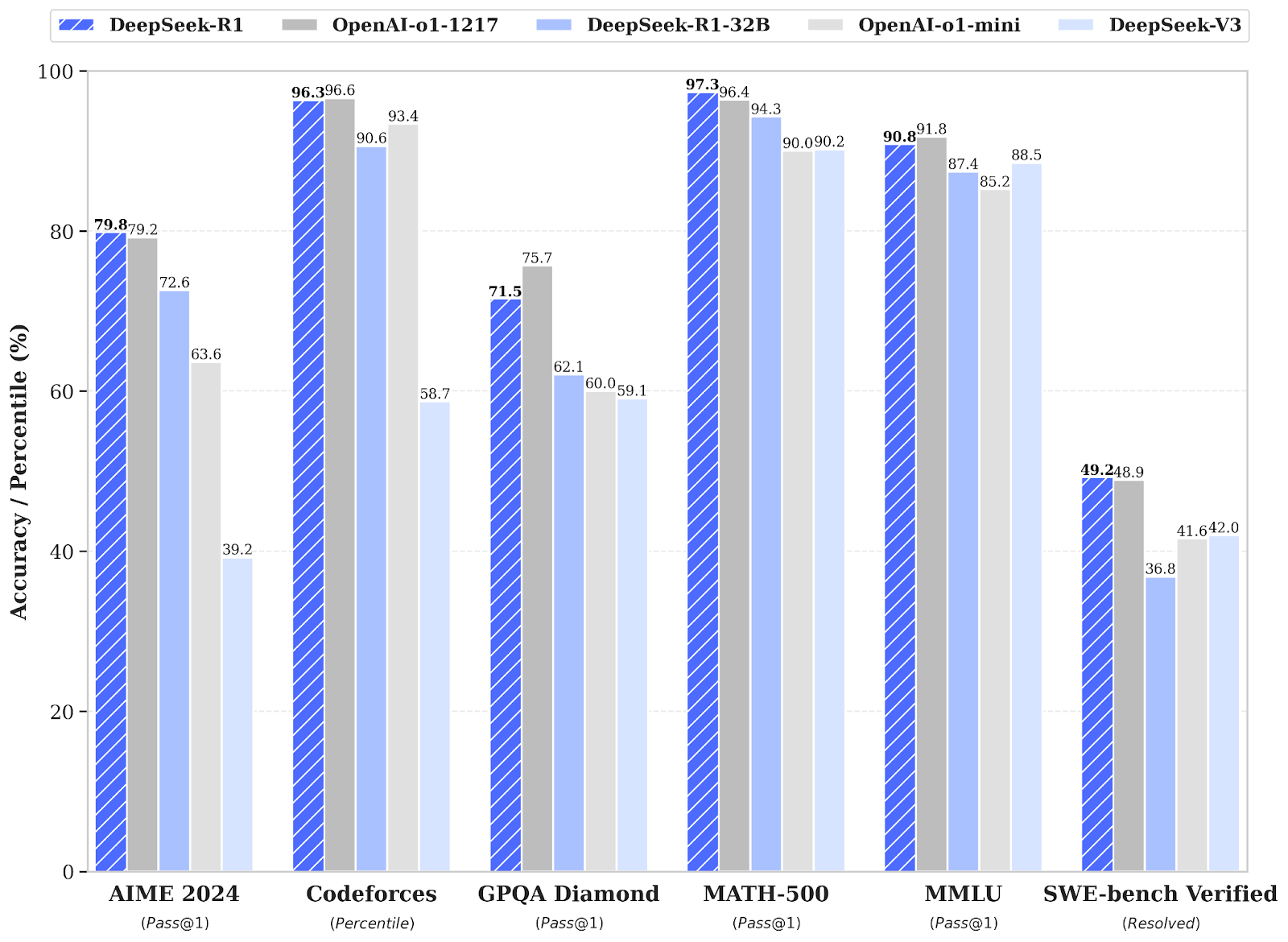
Cuando se probó, DeepSeek-R1 obtuvo una puntuación del 79,8 % en las pruebas de matemáticas AIME 2024 y del 97,3 % en MATH-500. También logró una calificación de 2029 en Codeforces, mejor que el 96,3% de los programadores humanos. Por el contrario, o1-1217 obtuvo una puntuación del 79,2%, 96,4% y 96,6% respectivamente en estos puntos de referencia.
También demostró un sólido conocimiento general, con una precisión del 90,8% en MMLU, justo detrás del 91,8% de o1.

El canal de formación
El rendimiento de razonamiento de DeepSeek-R1 marca una gran victoria para la startup china en el espacio de la IA dominado por Estados Unidos, especialmente porque todo el trabajo es de código abierto, incluida la forma en que la empresa entrenó todo.
Sin embargo, el trabajo no es tan sencillo como parece.
Según el artículo que describe la investigación, DeepSeek-R1 se desarrolló como una versión mejorada de DeepSeek-R1-Zero, un modelo innovador entrenado únicamente a partir del aprendizaje por refuerzo.
We are living in a timeline where a non-US company is keeping the original mission of OpenAI alive – truly open, frontier research that empowers all. It makes no sense. The most entertaining outcome is the most likely.
— Jim Fan (@DrJimFan) January 20, 2025
DeepSeek-R1 not only open-sources a barrage of models but… pic.twitter.com/M7eZnEmCOY
La compañía utilizó por primera vez DeepSeek-V3-base como modelo base, desarrollando sus capacidades de razonamiento sin emplear datos supervisados, enfocándose esencialmente solo en su autoevolución a través de un proceso de prueba y error puro basado en RL. Desarrollada intrínsecamente a partir del trabajo, esta capacidad garantiza que el modelo pueda resolver tareas de razonamiento cada vez más complejas aprovechando el cálculo de tiempo de prueba extendido para explorar y refinar sus procesos de pensamiento con mayor profundidad.
“Durante el entrenamiento, DeepSeek-R1-Zero emergió naturalmente con numerosos comportamientos de razonamiento poderosos e interesantes”, señalan los investigadores en el artículo. “Después de miles de pasos de RL, DeepSeek-R1-Zero exhibe un rendimiento excelente en pruebas comparativas de razonamiento. Por ejemplo, la puntuación pass@1 en AIME 2024 aumenta del 15,6% al 71,0%, y con la votación mayoritaria, la puntuación mejora aún más hasta el 86,7%, igualando el rendimiento de OpenAI-o1-0912”.
Sin embargo, a pesar de mostrar un rendimiento mejorado, incluidos comportamientos como la reflexión y la exploración de alternativas, el modelo inicial mostró algunos problemas, incluida una legibilidad deficiente y una mezcla de idiomas. Para solucionar este problema, la empresa se basó en el trabajo realizado para R1-Zero, utilizando un enfoque de varias etapas que combina aprendizaje supervisado y aprendizaje reforzado, y así creó el modelo R1 mejorado.
“Específicamente, comenzamos recopilando miles de datos de arranque en frío para ajustar el modelo DeepSeek-V3-Base”, explicaron los investigadores. “Después de esto, realizamos RL orientada al razonamiento como DeepSeek-R1-Zero. Al acercarse a la convergencia en el proceso de RL, creamos nuevos datos SFT mediante muestreo de rechazo en el punto de control de RL, combinados con datos supervisados de DeepSeek-V3 en dominios como escritura, control de calidad factual y autoconocimiento, y luego volvemos a entrenar el DeepSeek-V3. -Modelo básico. Después de realizar ajustes con los nuevos datos, el punto de control se somete a un proceso de RL adicional, teniendo en cuenta las indicaciones de todos los escenarios. Después de estos pasos, obtuvimos un punto de control llamado DeepSeek-R1, que logra un rendimiento a la par con OpenAI-o1-1217”.
Mucho más asequible que o1
Además de un rendimiento mejorado que casi iguala al o1 de OpenAI en todos los puntos de referencia, el nuevo DeepSeek-R1 también es muy asequible. Específicamente, mientras que OpenAI o1 cuesta $15 por millón de tokens de entrada y $60 por millón de tokens de salida, DeepSeek Reasoner, que se basa en el modelo R1, cuesta $0,55 por millón de entradas y $2,19 por millón de tokens de salida.
Sooo @deepseek_ai's reasoner model, which sits somewhere between o1-mini & o1 is about 90-95% cheaper 👀 https://t.co/ohnI6dtPRC pic.twitter.com/Qn78yIGUtt
— Emad (@EMostaque) January 20, 2025
El modelo se puede probar como “DeepThink” en la plataforma de chat DeepSeek, que es similar a ChatGPT. Los usuarios interesados pueden acceder a los pesos de los modelos y al repositorio de códigos a través de Hugging Face, bajo una licencia del MIT, o pueden utilizar la API para una integración directa.

