Noticias
Diagnóstico integrador de afecciones psiquiátricas utilizando Datos de CHATGPT y FMRI | Psiquiatría BMC

Diseño experimental
La Figura 1 presenta el flujo de trabajo general de nuestro diseño experimental. La etapa de recopilación de datos implica interacciones del paciente con la adquisición de datos CHATGPT y FMRI. Los resultados procesados de las tuberías de texto y imágenes se transforman en matrices de características, que posteriormente se utilizan para entrenar una red neuronal para la evaluación. La etapa final evalúa el rendimiento del modelo y lleva a cabo validación estadística.

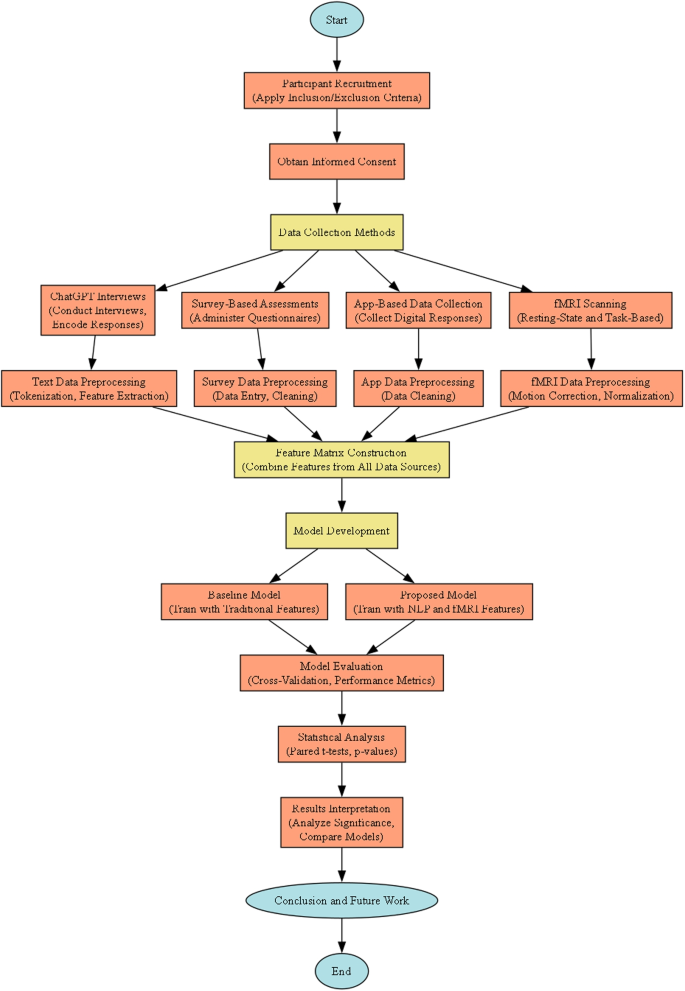
Flujo de trabajo de diseño experimental
Recopilación de datos
En este estudio, ChatGPT juega un papel crucial en la recopilación de información detallada y estandarizada del paciente a través de entrevistas dinámicas e interactivas. A diferencia de los métodos tradicionales, como las encuestas basadas en aplicaciones o en papel, que proporcionan datos estructurados pero rígidos, el enfoque de conversación de ChatGPT se adapta a las respuestas de los pacientes en tiempo real. Esta adaptabilidad permite que la IA investigue más profundamente en función de las respuestas iniciales, descubriendo los síntomas latentes y las preocupaciones de que los cuestionarios estandarizados pueden pasar por alto.
Un enfoque de método mixto combina datos cuantitativos (incluidas codificaciones numéricas como respuestas a escala de Likert) con ideas cualitativas capturadas de los diálogos de pacientes de forma libre. Esta estrategia combina la profundidad de las investigaciones cualitativas con la objetividad de las evaluaciones cuantitativas, ofreciendo una visión más holística del estado mental del paciente [18].
Al adherirse a un guión de entrevista constante al tiempo que permite variaciones de lenguaje natural, ChatGPT asegura que todos los pacientes participen en las mismas áreas centrales de investigación. Esta uniformidad incluye preguntas sobre el estado de ánimo, los niveles de ansiedad, los patrones de sueño e historial médico. Debido a que todos los pacientes experimentan el mismo conjunto de temas guiados, el sesgo del entrevistador se minimiza, lo cual es particularmente importante dada la subjetividad del diagnóstico psiquiátrico.
ChatGPT también proporciona un nivel de comodidad y compromiso para los pacientes que pueden sentirse más a gusto revelar información confidencial a un entrevistador de IA. Estudios, como Lucas et al. (2014), indican que el miedo reducido al juicio puede conducir a una mayor divulgación [19]. Esta apertura puede dar lugar a datos más ricos, lo que refleja más a fondo la condición del paciente.
Además de obtener respuestas, CHATGPT utiliza técnicas NLP avanzadas para extraer y cuantificar detalles matizados del diálogo. Los marcadores lingüísticos correlacionados con los trastornos psiquiátricos, como los cambios significativos en el sentimiento o los cambios en el uso del pronombre, se capturan automáticamente [20]. Las encuestas tradicionales a menudo pasan por alto estas sutiles señales lingüísticas, limitando así su potencial de diagnóstico.
Una vez que se recopilan los datos, el contenido de conversación se analiza y se transforma en una matriz de características numéricas. Las respuestas se tokenizan, se limitan y se clasifican en categorías estandarizadas, como descriptores de humor o indicadores de comportamiento. Esto garantiza la consistencia y la comparabilidad entre diferentes pacientes y sesiones, lo que permite la integración de datos basados en el diálogo con medidas de neuroimagen.
Al fusionar información cualitativa y cuantitativa en una sola tubería, el método mitiga las trampas de enfoques puramente narrativos o puramente numéricos y produce un conjunto de datos robusto y ricamente texturizado. Los datos resultantes están listos para el entrenamiento de modelos posterior y el análisis predictivo.
adquisición de datos fMRI
Se realizaron escaneos fMRI para capturar patrones de actividad cerebral asociados con trastornos psiquiátricos. La FMRI en estado de reposo identificó la actividad neuronal de referencia mientras los participantes se quedan quietas con los ojos cerrados, centrándose en la red de modo predeterminado y otras redes de conectividad intrínsecas. La FMRI basada en tareas ayudó a sondear procesos cognitivos y afectivos específicos. En una tarea de reconocimiento emocional, los participantes vieron imágenes de caras que expresan diferentes emociones (por ejemplo, felicidad, tristeza, miedo, ira) e identificaron, activando así la amígdala y la corteza prefrontal. Una tarea de recuperación de memoria requirió a los participantes para memorizar una lista de palabras o imágenes y luego recordarlas después de un retraso, dirigido al hipocampo y las estructuras de lóbulo temporal medial circundante. Una tarea de atención e inhibición, como la prueba Stroop, llevó a los participantes a nombrar los colores de tinta mientras ignoraba el significado léxico de las palabras, activando la corteza cingulada anterior y la corteza prefrontal dorsolateral.
Los datos de fMRI sin procesar se preprocesaron para corregir el movimiento, alinear las imágenes con una plantilla común a través de la normalización espacial y reducir el ruido de baja frecuencia a través del filtrado temporal. Al estandarizar estos procedimientos, la calidad de los datos mejoró y se hizo consistente en todos los participantes del estudio, lo que permite la extracción de características posterior centrada en los patrones regionales de activación cerebral y conectividad.
Construcción de matriz de características
Características del modelo de referencia
También se desarrolló un modelo de línea de base, confiando en las características clínicas tradicionales en lugar de los datos derivados de PNL. Las características de referencia incluían información demográfica como la edad y el género. También abarcaron evaluaciones clínicas, incluidas las puntuaciones basadas en el cuestionario (PHQ-9 para la depresión y GAD-7 para la ansiedad) y las clasificaciones de gravedad de los síntomas, así como cambios básicos autoinformados en el sueño, el apetito y la energía. Estos puntos de datos de línea de base se ensamblaron en una matriz numérica análoga al modelo principal, pero no incluyeron las características derivadas de NLP más ricas de los diálogos de los pacientes.
Extracción de características de los diálogos del paciente
Las características basadas en el diálogo se extrajeron utilizando técnicas de PNL que estandarizaron y codificaron las respuestas del paciente. Se utilizaron la tokenización, la lemmatización y las asignaciones de categorías para garantizar un tratamiento de datos uniforme. Las descripciones del estado de ánimo y los patrones de sueño se convirtieron en indicadores de comportamiento, y también se codificaron señales lingüísticas, como dudas, negación o cambios de sentimiento. Este enfoque uniforme minimizó la variabilidad entre los pacientes y permitió comparaciones directas en una amplia variedad de insumos cualitativos.
Preprocesamiento de datos fMRI
El preprocesamiento de los datos de fMRI incluyó la corrección de movimiento para compensar los movimientos de los participantes, la normalización espacial para asignar imágenes en una plantilla cerebral común y filtrado temporal para eliminar el ruido de baja frecuencia. Estos pasos culminaron en mapas volumétricos consistentes de actividad cerebral entre los pacientes. Los datos de fMRI finalizados se usaron luego para extraer características como los niveles de activación regional y los patrones de conectividad cerebral, formateados para la integración posterior con las características del diálogo del paciente.
Criterios de selección de pacientes
Se requirió que los participantes en el estudio tengan un diagnóstico confirmado de un solo trastorno psiquiátrico, tengan al menos 18 años y fueran competentes en chino mandarín. Solo se incluyeron aquellos capaces de consentimiento informado y dispuestos a someterse a entrevistas con CHATGPT y escanear fMRI. Cualquier persona con trastornos neurológicos severos, síntomas psiquiátricos agudos que requirieron intervención inmediata, implantes metálicos contraindicados para la resonancia magnética o los diagnósticos de abuso de sustancias. Factores adicionales, como el embarazo o la incapacidad de permanecer quieto durante los escaneos, también provocaron exclusión.
Procedimientos de recopilación de datos
Antes del estudio, todos los equipos (incluida la interfaz CHATGPT y el escáner de resonancia magnética) fueron validados y calibrados. Los participantes dieron su consentimiento informado y se sometieron a las entrevistas con CHATGPT después de un guión estructurado diseñado para cubrir el estado de ánimo, el sueño, el historial de ansiedad o la depresión, y otros factores clínicos relevantes. Sus escaneos FMRI se realizaron luego de acuerdo con los protocolos descritos anteriormente. Todos los datos, tanto de diálogos como de escaneos, se limpiaron y prepararon posteriormente para el análisis como matrices de características numéricas.
Arquitectura de redes neuronales
La sintonización de hiperparámetros implicaba ajustar las tasas de aprendizaje, los tamaños de lotes, los recuentos de capa y las unidades de capa. La búsqueda en la red y los métodos de búsqueda aleatoria ayudaron a identificar configuraciones óptimas. Se exploraron arquitecturas alternativas como RNN, pero la arquitectura elegida superó a estas alternativas. La dimensionalidad más alta de nuestros datos y la necesidad de características integradas de texto y imagen nos llevó a favorecer el enfoque de fusión que se describe a continuación.
La red neuronal procesa dos entradas principales: la matriz de características derivadas del diálogo y los volúmenes de fMRI 4D. Las características basadas en el diálogo incluyen variables demográficas y lingüísticas, generalmente formateadas en un \ (N \ Times 16 \) matriz, donde norte es el número de muestras y 16 representa las características extraídas. Los datos de fMRI, después del preprocesamiento, aparecen como un volumen 3D (\ (64 \ Times 64 \ Times 30 \) Voxels) con una dimensión de tiempo que captura los cambios funcionales en una ventana de 30 segundos.
En las transmisiones paralelas, las características basadas en el diálogo pasan a través de varias capas densas (totalmente conectadas), con configuraciones que generalmente comienzan en 64 unidades (activación de RELU), luego 32 unidades, etc. Los datos de FMRI se gestionan a través de capas convolucionales y de politización máxima, con filtros de tamaño \ (3 \ Times 3 \ Times 3 \)también utilizando la activación de Relu, seguido de aplanamiento para fusionar características espaciales y temporales en un vector.
Ambas corrientes finalmente se alimentan en una capa de fusión que concatena los datos de diálogo procesados con las características de fMRI aplanadas. Esta representación integrada se pasa a través de capas densas adicionales (128 unidades seguidas de 64 unidades, ambas usando RELU) para aprender una incrustación de articulación óptima.
Después de concatenar las características de fMRI aplanadas con las características del diálogo procesado, se aplica una capa densa con 128 unidades y se aplica la activación de RELU. Esta capa realiza una reducción de dimensionalidad y la normalización del vector de características fusionadas, asegurando que la información combinada de ambas modalidades esté en una escala comparable antes de ingresar las capas densas posteriores. La elección de 128 unidades se determinó empíricamente a través de la validación cruzada para lograr un equilibrio entre la complejidad del modelo y el rendimiento diagnóstico.
Se utiliza un pequeño conjunto de capas totalmente conectadas finales para la clasificación, concluyendo con una capa Softmax para una salida multiclase. Cinco clases generalmente representan trastornos depresivos, trastornos de ansiedad, trastornos bipolares y relacionados, espectro de esquizofrenia y otros trastornos psicóticos/ninguno. Esta estructura se adapta a los resultados específicos del diagnóstico de manera clínicamente significativa.
La Figura 2 muestra el flujo general de la red neuronal, que muestra flujos paralelos para las características de diálogo basadas en texto y los datos de fMRI 4D, una etapa de fusión posterior y capas de clasificación que generan categorías de diagnóstico.

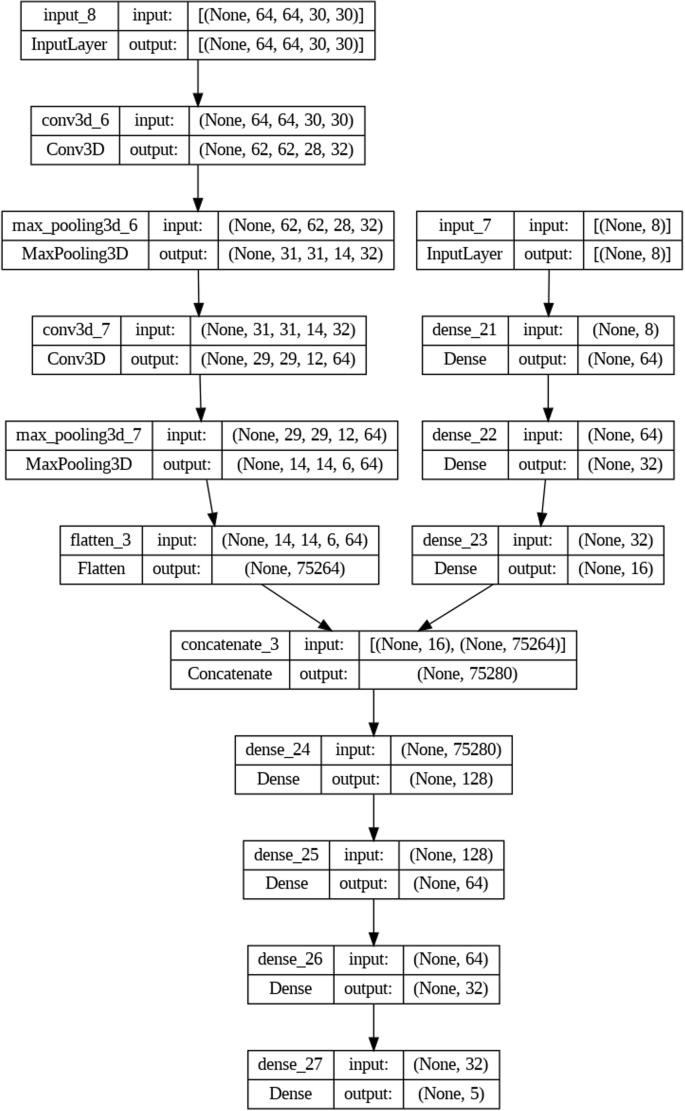
Arquitectura del modelo de red neuronal. El modelo comprende dos transmisiones de entrada distintas, una de procesamiento de datos de fMRI (flujo izquierdo) y las otras características de procesamiento derivadas de los diálogos del paciente (flujo derecho). Estas entradas se fusionan posteriormente para el análisis conjunto, lo que lleva a la clasificación final. (1) Entrada de datos de fMRI (flujo izquierdo): los datos de fMRI, formateados como un tensor 4D con dimensiones (64x64x30x30), pasan a través de una secuencia de capas convolucionales 3D (conv3d), seguidas de capas maxpooling3D a temple y de extracción de características spaciales. La salida se aplana en un vector de características del tamaño 75,264, capturando patrones clave de actividad cerebral. (2) Entrada del diálogo del paciente (flujo derecho): los datos del diálogo del paciente, representados como un vector 8 dimensional, se procesan a través de una serie de capas densas (totalmente conectadas). Estas capas reducen progresivamente la dimensionalidad, con la salida final como un vector de 16 dimensiones que captura características lingüísticas y emocionales. (3) Fusión y procesamiento de características: las salidas de ambas secuencias de entrada se concatenan en un solo vector de tamaño 75,280. Esta representación conjunta se procesa a través de varias capas densas, con el número de unidades reducida gradualmente (de 128 a 64, y luego a 32), lo que permite que el modelo refine sus representaciones de características. (4) Capa de clasificación: la capa de salida final consta de 5 unidades, correspondientes a las categorías de trastorno psiquiátrico bajo consideración. Se aplica una función de activación de Softmax para producir las probabilidades de clasificación final para cada trastorno
Capacitación y evaluación de modelos
La capacitación se realizó en conjuntos de datos etiquetados que contenían las características del diálogo del paciente y las exploraciones de fMRI correspondientes. El Adam Optimizer se utilizó con una tasa de aprendizaje de \ (1 \ Times 10^{-4} \). La entropía cruzada categórica sirvió como función de pérdida para la clasificación multiclase. El tamaño del lote generalmente involucraba 8 muestras, y la red fue entrenada para 20 épocas con una parada temprana si la pérdida de validación no mejoró para 5 épocas consecutivas. La precisión, la precisión, el recuerdo y la puntuación F1 se usaron como métricas primarias. Se realizó diez veces la validación cruzada para medir la estabilidad y robustez del modelo.