El próximo modelo de inteligencia artificial de OpenAI está generando menores ganancias de rendimiento que sus predecesores, dijeron a The Information fuentes familiarizadas con el asunto.
Las pruebas de los empleados revelan que Orion logró un rendimiento de nivel GPT-4 después de completar solo el 20% de su capacitación, informa The Information.
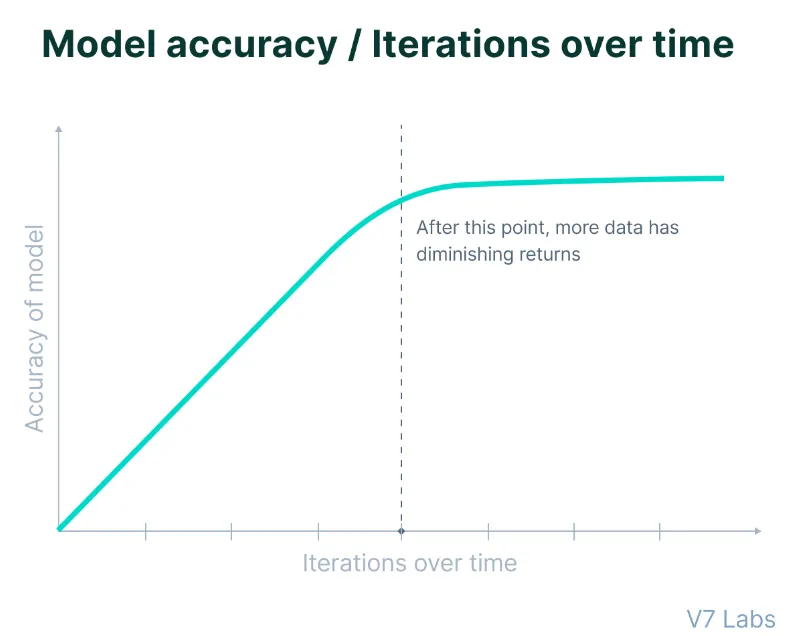
El aumento de calidad de GPT-4 a la versión actual de GPT-5 parece ser menor que el de GPT-3 a GPT-4.
“Algunos investigadores de la compañía creen que Orion no es mejor que su predecesor en el manejo de ciertas tareas, según los empleados (de OpenAI)”, informó The Information. “Orion se desempeña mejor en tareas de lenguaje, pero es posible que no supere a los modelos anteriores en tareas como la codificación, según un empleado de OpenAI”.
Si bien el hecho de que Orion se acerque a GPT-4 con un 20% de su entrenamiento puede parecer impresionante para algunos, es importante tener en cuenta que las primeras etapas del entrenamiento de IA suelen ofrecer las mejoras más espectaculares, mientras que las fases posteriores producen ganancias menores.
Por lo tanto, no es probable que el 80% restante del tiempo de capacitación produzca la misma magnitud de avance observado en saltos generacionales anteriores, dijeron las fuentes.
Imagen: Laboratorios V7
Las limitaciones surgen en un momento crítico para OpenAI luego de su reciente ronda de financiación de 6.600 millones de dólares.
La empresa ahora enfrenta mayores expectativas por parte de los inversores mientras lidia con limitaciones técnicas que desafían los enfoques tradicionales de escalamiento en el desarrollo de la IA. Si estas primeras versiones no cumplen con las expectativas, es posible que los próximos esfuerzos de recaudación de fondos de la compañía no reciban el mismo entusiasmo que antes, y eso podría ser un problema para una empresa potencialmente lucrativa, que es lo que Sam Altman parece querer para OpenAI. .
Los resultados decepcionantes apuntan a un desafío fundamental que enfrenta toda la industria de la IA: la oferta cada vez menor de datos de capacitación de alta calidad y la necesidad de seguir siendo relevante en un campo tan competitivo como la IA generativa.
Una investigación publicada en junio predijo que las empresas de inteligencia artificial agotarán los datos de texto públicos disponibles generados por humanos entre 2026 y 2032, lo que marca un punto de inflexión crítico para los enfoques de desarrollo tradicionales.
“Nuestros hallazgos indican que las tendencias actuales de desarrollo de LLM no pueden sostenerse únicamente mediante el escalamiento de datos convencional”, afirma el artículo de investigación, destacando la necesidad de enfoques alternativos para la mejora del modelo, incluida la generación de datos sintéticos, la transferencia de aprendizaje de dominios ricos en datos y el uso. de datos no públicos.
La estrategia histórica de entrenar modelos de lenguaje en texto disponible públicamente de sitios web, libros y otras fuentes ha llegado a un punto de rendimiento decreciente, y los desarrolladores han “exprimido en gran medida ese tipo de datos tanto como pueden”, según The Information. .
Cómo OpenAI está abordando este problema: razonamiento versus modelos de lenguaje
Para abordar estos desafíos, OpenAI está reestructurando fundamentalmente su enfoque para el desarrollo de la IA.
“En respuesta al reciente desafío a las leyes de escalamiento basadas en capacitación que plantea la desaceleración de las mejoras de GPT, la industria parece estar cambiando sus esfuerzos para mejorar los modelos después de su capacitación inicial, lo que podría generar un tipo diferente de ley de escala”, informa The Information.
Para lograr este estado de mejora continua, OpenAI está separando el desarrollo de modelos en dos vías distintas:
La Serie O (que parece tener el nombre en clave Strawberry), centrada en las capacidades de razonamiento, representa una nueva dirección en la arquitectura de modelos. Estos modelos operan con una intensidad computacional significativamente mayor y están diseñados explícitamente para tareas complejas de resolución de problemas.
Las demandas computacionales son sustanciales, y las primeras estimaciones sugieren costos operativos seis veces mayores que los de los modelos actuales. Sin embargo, las capacidades de razonamiento mejoradas podrían justificar el aumento del gasto para aplicaciones específicas que requieren procesamiento analítico avanzado.
Este modelo, si es el mismo que Strawberry, también tiene la tarea de generar suficientes datos sintéticos para aumentar constantemente la calidad de los LLM de OpenAI.
Paralelamente, los Modelos Orion o la Serie GPT (considerando que OpenAI registra el nombre GPT-5) continúan evolucionando, enfocándose en tareas generales de procesamiento del lenguaje y comunicación. Estos modelos mantienen requisitos computacionales más eficientes al tiempo que aprovechan su base de conocimientos más amplia para tareas de redacción y argumentación.
El CPO de OpenAI, Kevin Weil, también confirmó esto durante una AMA y dijo que espera que ambos desarrollos converjan en algún momento en el futuro.
“No es una cosa o la otra”, respondió cuando se le preguntó si OpenAI se centraría en escalar los LLM con más datos o usar un enfoque diferente, centrándose en modelos más pequeños pero más rápidos, “mejores modelos base y más computación de escalado/tiempo de inferencia”. “
¿Una solución alternativa o la solución definitiva?
El enfoque de OpenAI para abordar la escasez de datos mediante la generación de datos sintéticos presenta desafíos complejos para la industria. Los investigadores de la compañía están desarrollando modelos sofisticados diseñados para generar datos de entrenamiento, pero esta solución introduce nuevas complicaciones en el mantenimiento de la calidad y confiabilidad del modelo.
Como informó anteriormente por Descifrarlos investigadores han descubierto que el entrenamiento de modelos con datos sintéticos representa un arma de doble filo. Si bien ofrece una solución potencial a la escasez de datos, introduce nuevos riesgos de degradación del modelo y problemas de confiabilidad con una degradación comprobada después de varias iteraciones de entrenamiento.
En otras palabras, a medida que los modelos se entrenan con contenido generado por IA, pueden comenzar a amplificar imperfecciones sutiles en sus resultados. Estos ciclos de retroalimentación pueden perpetuar y magnificar los sesgos existentes, creando un efecto compuesto que se vuelve cada vez más difícil de detectar y corregir.
El equipo de Foundations de OpenAI está desarrollando nuevos mecanismos de filtrado para mantener la calidad de los datos, implementando diferentes técnicas de validación para distinguir entre contenido sintético de alta calidad y potencialmente problemático. El equipo también está explorando enfoques de capacitación híbridos que combinan estratégicamente contenido generado por humanos y por IA para maximizar los beneficios de ambas fuentes y minimizar sus respectivos inconvenientes.
La optimización post-entrenamiento también ha ganado relevancia. Los investigadores están desarrollando nuevos métodos para mejorar el rendimiento del modelo después de la fase de entrenamiento inicial, ofreciendo potencialmente una manera de mejorar las capacidades sin depender únicamente de expandir el conjunto de datos de entrenamiento.
Dicho esto, GPT-5 es todavía un embrión de un modelo completo con un importante trabajo de desarrollo por delante. Sam Altman, director ejecutivo de OpenAI, ha indicado que no estará listo para su implementación este año ni el próximo. Este cronograma ampliado podría resultar ventajoso, ya que permitiría a los investigadores abordar las limitaciones actuales y potencialmente descubrir nuevos métodos para mejorar el modelo, mejorando considerablemente GPT-5 antes de su lanzamiento final.
Editado por Josh Quittner y Sebastian Sinclair.
Generalmente inteligente Hoja informativa
Un viaje semanal de IA narrado por Gen, un modelo de IA generativa.