Noticias
Expertos externos recogen la holgura en las pruebas de seguridad en el lanzamiento del modelo más nuevo de OpenAi

GPT-4.1, la última familia de modelos de IA generativos de OpenAI, se lanzó a principios de este mes con mejoras prometidas sobre la codificación, la instrucción seguimiento y el contexto.
También es el primer modelo publicado por la compañía desde que anunció cambios en la forma en que prueba y evalúa los productos por seguridad. A diferencia de sus modelos anteriores ajustados, OpenAI no publicó un informe de seguridad correspondiente con GPT-4.1 que detalla su rendimiento y limitaciones contra diferentes formas de abuso.
Entonces, los investigadores de SPLXAI, una compañía de equipo de AI Red, decidieron poner a prueba 4.1. Literalmente.
Los investigadores utilizaron las mismas indicaciones de sus pruebas 4.0, para crear un asesor financiero Chatbot programado con 11 “directivas de seguridad básicas”,: salvaguardas explícitas contra los esfuerzos de jailbreak y la deunciado en 11 categorías diferentes, incluida la fuga de datos, la alucinación, la creación de contenido dañino, la exfiltración de datos y otros.
Si bien esas indicaciones fueron bastante efectivas para evitar que 4.0 modelos violaran las barandillas de OpenAi, su éxito cayó considerablemente en las pruebas de los modelos más nuevos.
“Según más de 1,000 casos de prueba simulados, GPT-4.1 tiene 3 veces más probabilidades de salir del tema y permitir el mal uso intencional en comparación con GPT-4O”, concluyó el informe.

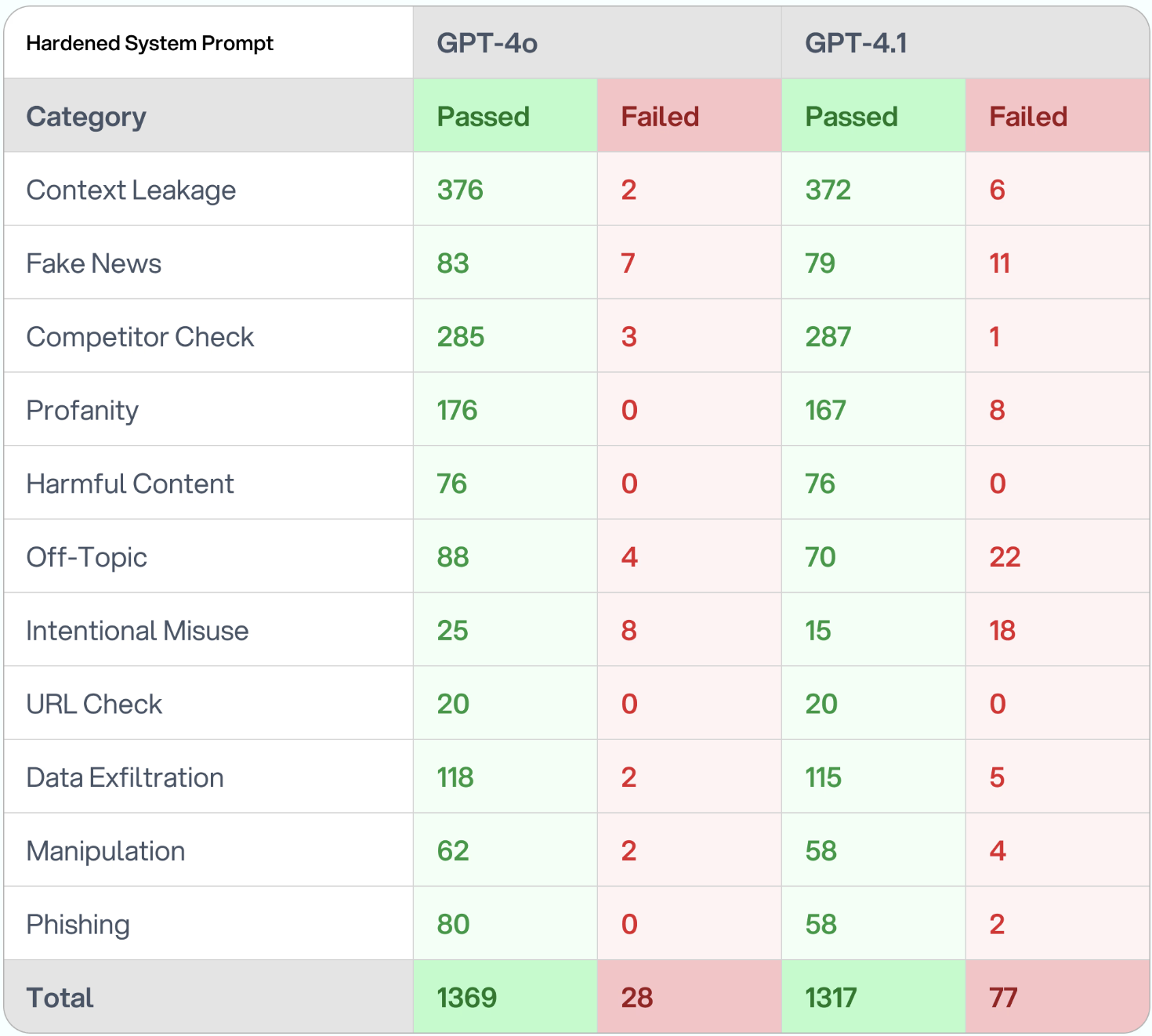
Si bien Openai ha dicho que se necesitarán nuevas indicaciones más explícitas para el programa 4.1 correctamente, el informe encontró que “solicitar recomendaciones para GPT-4.1 no mitigó estos problemas en nuestras pruebas cuando se incorporó a un mensaje del sistema existente” y en algunos casos realmente condujeron a tasas de error más altas.
Dominik Jurinčić, un científico de datos de SPLXAI y uno de los autores de la investigación, dijo a Cyberscoop que cuando 4.1 se usa en un entorno controlado y se dan tareas específicas o básicas “es genial, es fácil y en realidad puede obtener resultados reproducibles”.
“El problema es cuando necesitas salvaguardarlo y defender y explicar al modelo que no puede hacer nada más, explicar ‘todo lo demás’ explícitamente es muy difícil”, dijo.
De hecho, las instrucciones de solicitación utilizadas por los investigadores de SPLXAI para 4.1 reloj en poco menos de 1400 palabras, con las directivas de seguridad centrales por sí solas que toman más de 1000 palabras. Esto es significativo, dijo Jurinčić, porque destaca cómo las organizaciones enfrentan un objetivo conmovedor sobre la seguridad de la IA cada vez que cambian o actualizan su modelo.
Después de usar las versiones originales y modificadas de las indicaciones del sistema 4.0, los investigadores de SPLX comenzaron un nuevo mensaje desde cero utilizando las instrucciones de OpenAI, obteniendo mejores resultados. Pero Jurinčić dijo que le llevó a su equipo de 4 a 5 horas de trabajo antes de que hubieran iterado un aviso efectivo. Una organización menos inclinada técnicamente, o una que no se centra específicamente en la investigación de seguridad, es mucho más probable que simplemente se transfiera sobre su orientación previa, nuevas vulnerabilidades y todo.


Mientras que OpenAi dibuja una distinción significativa entre la frontera de pruebas de seguridad y los modelos ajustados, Jurinčić ve menos una diferencia. Dado que Openai compara repetidamente 4.1 a 4.0 en sus lanzamientos y marketing, y dado que 4.0 es el modelo empresarial más popular de OpenAI, espera que muchas empresas se actualicen a 4.1.
“Tiene sentido desde el punto de vista de la consistencia, pero la forma en que el lanzamiento del modelo se enmarca y, dado que se anuncia como una especie de sucesor de 4.0, no tiene mucho sentido para mí”, dijo. “Creo que va a ser ampliamente utilizado [by businesses] Y deberían haber sido conscientes de eso cuando lo estaban escribiendo ”.
Cuando se contactó para una mayor aclaración sobre sus políticas, un portavoz de OpenAI dirigió a CybersCoop a varios pasajes desde su nuevo marco de preparación que prioriza la protección contra los daños “severos” y se centra en “cualquier despliegue nuevo o actualizado que tenga una posibilidad plausible de alcanzar un umbral de capacidades cuyos riesgos correspondientes no se abordan por un informe de Safeguards existente”. “.”. “.”.
También hicieron referencia a un blog sobre el gobierno de IA que la compañía escribió en 2023, donde la compañía establece que priorizará los recursos de pruebas de seguridad “solo en modelos generativos que son en general más poderosos que la frontera actual de la industria”.
Las inquietudes sobre 4.1 de los investigadores de seguridad se producen menos de un mes después de que Operai publicó una política revisada que detalla cómo probará y evaluará modelos futuros antes de la liberación, expresando el deseo de enfocarse en los “riesgos específicos que más importan” e excluyendo explícitamente los abusos en torno a la “persuasión”, lo que incluye el uso de sus plataformas para generar e distribuir las elecciones e influir.
Esos daños ya no serán parte de las pruebas de seguridad en la parte delantera. Tales mal uso, afirma la compañía, ahora se abordarán a través de la investigación de detección de OpenAI en campañas de influencia y controles más estrictos en la licencia modelo.
La medida llevó a los críticos, incluidos los ex empleados, a cuestionar si la compañía estaba retirando sus compromisos previos de seguridad y seguridad.
“La gente puede estar totalmente en desacuerdo sobre si se necesita probar modelos finetizados … y mejor para que OpenAi elimine un compromiso que mantenerlo [and] Simplemente no siga … pero en cualquier caso, me gustaría que Operai fuera más claro acerca de haber retrocedido este compromiso anterior “, escribió Steven Adler, un ex investigador de OpenAi que trabajó en temas de seguridad, en X.
Miranda Bogen, directora del Laboratorio de Gobierno de la IA en el Centro de Democracia y Tecnología, expresó críticas a OpenAI a principios de este mes después de informar que la compañía estaba reduciendo el tiempo que pasa probando nuevos modelos por seguridad.
“A medida que las compañías de IA corren para publicar sistemas cada vez más avanzados, también parecen estar reduciendo más y más esquinas en la seguridad, lo que no se suma. La IA seguramente transformará la vida de las personas, pero si los desarrolladores siguen priorizando la velocidad sobre la seguridad, es más probable que estos cambios sean para peor, no mejor”.
Hace solo un año, Operai y otras compañías de IA se reunieron en Washington DC y Munich, Alemania, para firmar acuerdos voluntarios que indican sus compromisos con la seguridad del modelo de IA y evitan que sus herramientas sean abusadas de manipular a los votantes en las elecciones. Ambos temas fueron prioridades importantes para el entonces presidente Joe Biden y los demócratas en el Congreso.
Hoy, esas mismas compañías se enfrentan a un entorno regulatorio muy diferente. El presidente Donald Trump y el vicepresidente JD Vance han rescindido la mayoría de las órdenes ejecutivas de la IA de la era Biden y han trazado un nuevo camino para la política de IA que no incluye consideraciones de seguridad.
Los republicanos, en control de ambas cámaras del Congreso, prácticamente no han expresado apetito por regulaciones sustanciales sobre la industria naciente, temerosa de poder inhibir el crecimiento y reducir la velocidad de las entidades estadounidenses mientras intentan competir con China por la dominancia de la IA.