Noticias
Gemini 2.0 Flash marca el inicio de una nueva era de IA multimodal en tiempo real
Únase a nuestros boletines diarios y semanales para obtener las últimas actualizaciones y contenido exclusivo sobre la cobertura de IA líder en la industria. Más información
El lanzamiento de Gemini 2.0 Flash por parte de Google esta semana, que ofrece a los usuarios una forma de interactuar en vivo con videos de su entorno, ha preparado el escenario para lo que podría ser un cambio fundamental en la forma en que las empresas y los consumidores interactúan con la tecnología.
Este lanzamiento, junto con los anuncios de OpenAI, Microsoft y otros, es parte del salto transformador que se está produciendo en el área tecnológica llamada “IA multimodal”. La tecnología le permite tomar videos (o audio o imágenes) que ingresan a su computadora o teléfono y hacer preguntas al respecto.
También señala una intensificación de la carrera competitiva entre Google y sus principales rivales (OpenAI y Microsoft) por el dominio de las capacidades de IA. Pero lo más importante es que parece que está definiendo la próxima era de la informática interactiva y agente.
Este momento de la IA me parece un “momento iPhone”, y con esto me refiero a 2007-2008, cuando Apple lanzó un iPhone que, a través de una conexión a Internet y una elegante interfaz de usuario, transformó la vida cotidiana al ofrecer a las personas una potente ordenador en el bolsillo.
Si bien ChatGPT de OpenAI puede haber iniciado este último momento de IA con su poderoso chatbot con apariencia humana en noviembre de 2022, el lanzamiento de Google aquí a fines de 2024 parece una gran continuación de ese momento, en un momento en el que muchos observadores estaban preocupados. una posible desaceleración en las mejoras de la tecnología de IA.
Gemini 2.0 Flash: el catalizador de la revolución multimodal de la IA
Gemini 2.0 Flash de Google ofrece una funcionalidad innovadora que permite la interacción en tiempo real con vídeo capturado a través de un teléfono inteligente. A diferencia de demostraciones realizadas anteriormente (por ejemplo, el Proyecto Astra de Google en mayo), esta tecnología ahora está disponible para los usuarios cotidianos a través del AI Studio de Google.
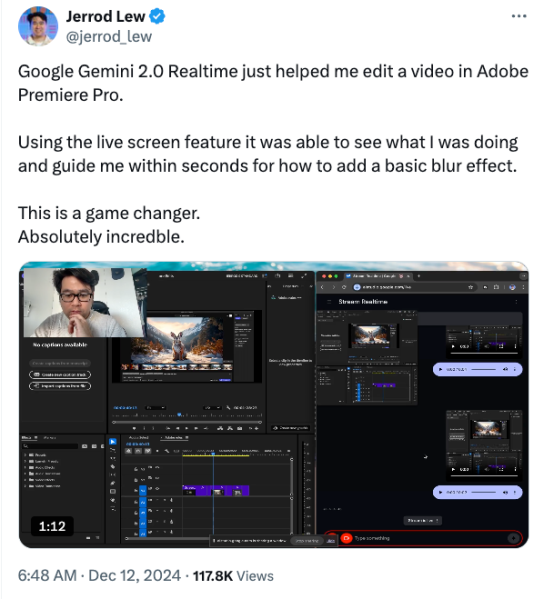
Te animo a que lo pruebes tú mismo. Lo usé para ver e interactuar con mi entorno, que para mí esta mañana era mi cocina y mi comedor. Puede ver al instante cómo esto ofrece avances para la educación y otros casos de uso. Puedes ver por qué el creador de contenidos Jerrod Lew reaccionó en X ayer con asombro cuando usó Gemini 2.0 Realtime para editar un video en Adobe Premier Pro. “Esto es absolutamente una locura”, dijo, después de que Google lo guiara en cuestión de segundos sobre cómo agregar un efecto de desenfoque básico a pesar de que era un usuario novato.

Sam Witteveen, un destacado desarrollador de inteligencia artificial y cofundador de Red Dragon AI, recibió acceso temprano para probar Gemini 2.0 Flash, y destacó que la velocidad de Gemini Flash (es dos veces más rápida que el buque insignia de Google hasta ahora, Gemini 1.5 Pro) y Los precios “increíblemente baratos” lo convierten no solo en un escaparate para que los desarrolladores prueben nuevos productos, sino también en una herramienta práctica para las empresas que gestionan presupuestos de IA. (Para ser claros, Google aún no ha anunciado el precio de Gemini 2.0 Flash. Es una vista previa gratuita. Pero Witteveen basa sus suposiciones en el precedente establecido por la serie Gemini 1.5 de Google).
Para los desarrolladores, la Live API de estas funciones multimodales en vivo ofrece un potencial significativo, porque permiten una integración perfecta en las aplicaciones. Esa API también está disponible para su uso; Hay una aplicación de demostración disponible. Aquí está la publicación del blog de Google para desarrolladores.
El programador Simon Willison llamó a la API de streaming el siguiente nivel: “Esto parece sacado directamente de la ciencia ficción: poder tener una conversación de audio con un LLM capacitado sobre cosas que puede ‘ver’ a través de su cámara es una de esas ‘en las que vivimos’. los momentos del futuro”. Observó cómo se le pide a la API que habilite un modo de ejecución de código, que permite a los modelos escribir código Python, ejecutarlo y considerar el resultado como parte de su respuesta, todo parte de un futuro agente.

La tecnología es claramente un presagio de nuevos ecosistemas de aplicaciones y expectativas de los usuarios. Imagine poder analizar video en vivo durante una presentación, sugerir ediciones o solucionar problemas en tiempo real.
Sí, la tecnología es interesante para los consumidores, pero es importante que los usuarios y líderes empresariales también la comprendan. Las nuevas funciones son la base de una forma completamente nueva de trabajar e interactuar con la tecnología, lo que sugiere futuras ganancias de productividad y flujos de trabajo creativos.
El panorama competitivo: una carrera para definir el futuro
El Gemini 2.0 Flash de Google del miércoles llega en medio de una avalancha de lanzamientos tanto de Google como de sus principales competidores, que se apresuran a lanzar sus últimas tecnologías para finales de año. Todos prometen ofrecer capacidades multimodales listas para el consumidor: interacción de video en vivo, generación de imágenes y síntesis de voz, pero algunas de ellas no están completamente preparadas o ni siquiera completamente disponibles.
Una de las razones de la prisa es que algunas de estas empresas bonifican a sus empleados para que entreguen productos clave antes de fin de año. Otra es el derecho a presumir cuando lanzan nuevas funciones primero. Pueden conseguir una mayor tracción entre los usuarios si son los primeros, como lo demostró OpenAI en 2022, cuando su ChatGPT se convirtió en el producto de consumo de más rápido crecimiento de la historia. Aunque Google tenía una tecnología similar, no estaba preparado para un lanzamiento público y se quedó desprevenido. Desde entonces, los observadores han criticado duramente a Google por ser demasiado lento.
Esto es lo que otras empresas han anunciado en los últimos días, todas ellas contribuyendo a introducir esta nueva era de IA multimodal.
- Modo de voz avanzado de OpenAI con visión: Lanzado ayer pero aún en implementación, ofrece funciones como análisis de video en tiempo real y uso compartido de pantalla. Si bien son prometedores, los problemas de acceso temprano tienen un impacto inmediato limitado. Por ejemplo, todavía no pude acceder a él aunque soy suscriptor Plus.
- La visión del copiloto de Microsoft: La semana pasada, Microsoft lanzó una tecnología similar en versión preliminar, solo para un grupo selecto de sus usuarios Pro. Su diseño integrado en el navegador sugiere aplicaciones empresariales, pero carece del pulido y la accesibilidad de Gemini 2.0. Microsoft también lanzó un modelo Phi-4 rápido y potente.
- Haiku Claude 3.5 de Anthropic: Anthropic, hasta ahora en una acalorada carrera por el liderazgo del modelo de lenguaje grande (LLM) con OpenAI, no ha entregado nada tan innovador en el lado multimodal (. Acaba de lanzar 3.5 Haiku, notable por su eficiencia y velocidad. Pero su centrarse en la reducción de costos y tamaños de modelos más pequeños contrasta con las características innovadoras de la última versión de Google y la del modo de voz con visión de OpenAI.
Navegando desafíos y aprovechando oportunidades
Si bien estas tecnologías son revolucionarias, persisten desafíos:
- Accesibilidad y escalabilidad: OpenAI y Microsoft se han enfrentado a obstáculos en su implementación, y Google debe asegurarse de evitar obstáculos similares. Google hizo referencia a que su función de transmisión en vivo (Proyecto Astra) tiene un límite de memoria contextual de hasta diez minutos de memoria durante la sesión. Aunque es probable que esa cifra aumente con el tiempo.
- Privacidad y seguridad: Los sistemas de inteligencia artificial que analizan videos en tiempo real o datos personales necesitan salvaguardias sólidas para mantener la confianza. El modelo Flash Gemini 2.0 de Google tiene generación de imágenes nativas incorporada, acceso a API de terceros y puede acceder a la búsqueda de Google y ejecutar código. Todo eso es poderoso, pero puede ser peligrosamente fácil revelar accidentalmente información privada mientras se juega con estas cosas.
- Integración de ecosistemas: Mientras Microsoft aprovecha su suite empresarial y Google se ancla en Chrome, la pregunta sigue siendo: ¿Qué plataforma ofrece la experiencia más fluida para las empresas?
Sin embargo, todos estos obstáculos se ven superados por los beneficios potenciales de la tecnología, y no hay duda de que los desarrolladores y las empresas se apresurarán a adoptarla durante el próximo año.
Conclusión: Un nuevo amanecer, liderado por ahora por Google
Como comentamos el desarrollador Sam Witteveen y yo en nuestro podcast grabado el miércoles por la noche después del lanzamiento de Google, Gemini 2.0 Flash es un lanzamiento realmente impresionante: el momento en que la IA multimodal se ha vuelto real. Los avances de Google han marcado un nuevo punto de referencia, aunque es cierto que esta ventaja puede ser extremadamente fugaz. OpenAI y Microsoft le pisan los talones. Todavía estamos en las primeras etapas de esta revolución, al igual que en 2008, cuando a pesar del lanzamiento del iPhone, no estaba claro cómo responderían Google, Nokia y RIM. La historia demostró que Nokia y RIM no lo hicieron y murieron. Google respondió muy bien y le ha dado una oportunidad al iPhone.
Asimismo, está claro que Microsoft y OpenAI están muy en esta carrera con Google. Mientras tanto, Apple decidió asociarse en la tecnología y esta semana anunció una mayor integración con ChatGPT, pero ciertamente no está tratando de ganar directamente en esta nueva era de ofertas multimodales.
En nuestro podcast, Sam y yo también cubrimos la ventaja estratégica especial de Google en el área del navegador. Por ejemplo, su versión Project Mariner, una extensión de Chrome, le permite realizar tareas de navegación web en el mundo real con incluso más funcionalidad que las tecnologías competidoras ofrecidas por Anthropic (llamada Computer Use) y OmniParser de Microsoft (aún en investigación). Aunque es cierto que la función de Anthropic te brinda más acceso a los recursos locales de tu computadora. Todo esto le da a Google una ventaja en la carrera por impulsar las tecnologías de IA agentes también en 2005, incluso si Microsoft parece estar a la cabeza en el lado de la ejecución real de la entrega de soluciones agentes a las empresas. Los agentes de IA realizan tareas complejas de forma autónoma, con una mínima intervención humana; por ejemplo, pronto realizarán tareas de investigación avanzada y comprobaciones de bases de datos antes de realizar comercio electrónico, negociación de acciones o incluso compra de bienes raíces.
El enfoque de Google en hacer que estas capacidades de Gemini 2.0 sean accesibles tanto para los desarrolladores como para los consumidores es inteligente, porque garantiza que se dirige a la industria con un plan integral. Hasta ahora, Google ha tenido la reputación de no centrarse tan agresivamente en los desarrolladores como Microsoft.
La pregunta para los tomadores de decisiones no es si adoptar estas herramientas, sino qué tan rápido pueden integrarlas en los flujos de trabajo. Será fascinante ver a dónde nos lleva el próximo año. Asegúrese de escuchar nuestras conclusiones para usuarios empresariales en el siguiente vídeo:


