Noticias
‘Insane’: OpenAI presenta la generación de imágenes nativas de GPT-4O y ya está cautivando a los usuarios
Únase a nuestros boletines diarios y semanales para obtener las últimas actualizaciones y contenido exclusivo sobre la cobertura de IA líder de la industria. Obtenga más información
Estamos llegando en el aniversario de un año desde que Operai lanzó su primer modelo “Omni” o multimodal, GPT-4O en mayo de 2024, pero ese viejo estado todavía tiene algunos trucos bajo la manga.
Case-in-Point, hoy OpenAi finalmente encendió las capacidades nativas de generación de imágenes multimodales de GPT-4O para los usuarios de su exitoso chatbot chatgpt en los niveles de uso plus, profesionales y de uso gratuitos, aunque la compañía dijo que pronto también estaría disponible para Enterprise, EDU y a través de su interfaz de programación de aplicaciones (API).
A diferencia del modelo de imagen AI generativo anterior disponible en ChatGPT: Dall-E 3 de OpenAI, un modelo de transformador de difusión clásico que fue entrenado para reconstruir imágenes a partir de indicaciones de texto al eliminar el ruido de los píxeles: este nuevo generador de imágenes es parte del mismo modelo que escupe texto y código, ya que OpenAi entrenó todo el modelo para comprender todas estas formas de medios de comunicación a una vez.
El presidente de Openai, Greg Brockman, había previsualizado hace mucho tiempo esta capacidad nativa de GPT-4O en mayo de 2024, pero por razones que aún siguen desconocidas públicamente, la compañía se mantuvo hasta ahora, luego del lanzamiento público de lo que muchos usuarios de IA vieron como una característica similar de Google AI Studio con su modelo experimental Gemini 2 Flash.
Esto ha resultado en un generador de imágenes de mayor calidad que produce muchas más imágenes realistas y texto preciso horneado, y ya está impresionando a los usuarios, uno de los cuales llama a la calidad “loca”.

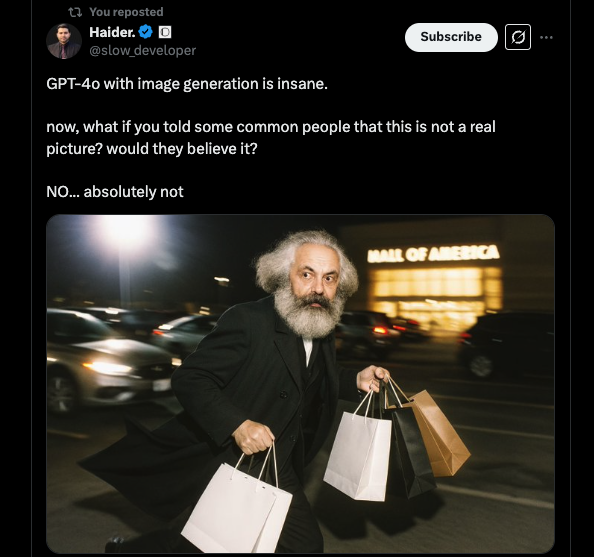
Del mismo modo (juego de palabras), OpenAi todavía no ha dicho con precisión en qué datos se capacitaron las capacidades de generación de imágenes de GPT-4O, y dada la historia de la compañía y otros proveedores de modelos, probablemente incluye muchas obras de arte raspadas de la web, algunas de las cuales probablemente tienen derechos de autor, lo que probablemente se enojará a los artistas detrás de ellos.
Traer la generación de imágenes a Chatgpt y Sora
OpenAI ha tenido como objetivo hacer que la generación de imágenes sea una capacidad central de sus modelos de IA. Con GPT-4O, los usuarios ahora pueden generar imágenes directamente en ChatGPT, refinandolas a través de la conversación y ajustando los detalles sobre la marcha.
El modelo también se integra en Sora, la plataforma de video de videoceneración de OpenAI, expandiendo aún más las capacidades multimodales.
En un anuncio en X, Operai confirmó que la generación de imágenes de GPT-4O está diseñada para:
- Prender el texto con precisión dentro de las imágenes, permitiendo la creación de signos, menús, invitaciones e infografías.
- Siga las indicaciones complejas con precisión, manteniendo una alta fidelidad incluso en composiciones detalladas.
- Construya sobre imágenes y texto anteriores, asegurando la consistencia visual en múltiples interacciones.
- Apoya varios estilos artísticos, desde el fotorrealismo hasta las ilustraciones estilizadas.
Los usuarios pueden describir una imagen en ChatGPT, especificando detalles como la relación de aspecto, los esquemas de color (códigos hexadecimales) o la transparencia, y GPT-4O la generará en un minuto.
Como la consultora independiente de IA Allie K. Miller escribió en X, es un “gran salto en la generación de texto”, y es “el mejor” modelo de generación de imágenes de IA que ha visto.


Capacidades clave y casos de uso
GPT-4O está diseñado para hacer que la generación de imágenes no solo sea visualmente impresionante sino también sea práctica. Algunas de las aplicaciones clave incluyen:
- Diseño y marca: genere logotipos, carteles y anuncios con una colocación de texto precisa.
- Educación y visualización: cree diagramas científicos, infografías e imágenes históricas para el aprendizaje.
- Desarrollo del juego: mantenga la consistencia del personaje en diferentes iteraciones de diseño.
- Creación de marketing y contenido: produce activos de redes sociales, invitaciones de eventos e ilustraciones digitales adaptadas a las necesidades de la marca.
Cómo GPT-4O mejora las imágenes generativas sobre Dall-E
Según el hilo oficial de OpenAI en X, GPT-4O presenta varias mejoras sobre modelos anteriores:
- Mejor integración de texto: A diferencia de los modelos de IA pasados que lucharon con un texto legible y bien ubicado, GPT-4O ahora puede incrustar con precisión las palabras dentro de las imágenes.
- Comprensión contextual mejorada: GPT-4O aprovecha el historial de chat, lo que permite a los usuarios refinar las imágenes de manera interactiva y mantener la coherencia en múltiples generaciones.
- Enlace mejorado de múltiples objetos: Si bien los modelos anteriores tenían dificultades para posicionar correctamente muchos objetos distintos en una escena, GPT-4O ahora puede manejar hasta 10-20 objetos a la vez.
- Adaptación de estilo versátil: El modelo puede generar o transformar imágenes en una variedad de estilos, desde bocetos dibujados a mano hasta fotorrealismo de alta resolución.
Limitaciones
A pesar de sus avances, GPT-4O todavía tiene algunos desafíos conocidos:
- Problemas de recorte: Las imágenes grandes, como los carteles, a veces se pueden recortar demasiado.
- Precisión de texto en scripts no latinos: Algunos personajes que no son ingleses pueden no rendir correctamente.
- Retención de detalles en texto pequeño: El texto altamente detallado o de fuentes pequeñas puede perder claridad.
- Precisión de edición: La modificación de partes específicas de una imagen puede afectar inadvertidamente otros elementos.
Operai aborda activamente estos problemas a través de refinamientos de modelos en curso.
Medidas de seguridad y etiquetado
Como parte del compromiso de OpenAI con el desarrollo responsable de la IA, todas las imágenes generadas por GPT-4O incluyen metadatos C2PA, lo que permite a los usuarios verificar su origen de IA.
Además, OpenAI ha creado una herramienta de búsqueda interna para ayudar a detectar imágenes generadas por IA.
Existen protectores estrictos para bloquear el contenido dañino y evitar el mal uso, como prohibir imágenes explícitas, engañosas o dañinas.
Operai también asegura que las imágenes con personas reales estén sujetas a mayores restricciones.
El CEO de Operai, Sam Altman, describió el lanzamiento como una “nueva marca de alta agua para la libertad creativa”, enfatizando que los usuarios podrán crear una amplia gama de imágenes, con OpenAI observando y refinando su enfoque basado en el uso del mundo real.
A medida que las imágenes generadas por AI se vuelven más precisas y accesibles, GPT-4O representa un paso adelante significativo para hacer que la generación de texto a imagen sea una herramienta convencional para la comunicación, la creatividad y la productividad.

