Noticias
Investigadores de Alibaba presentan Marco-o1, un LLM con capacidades de razonamiento avanzadas
Únase a nuestros boletines diarios y semanales para obtener las últimas actualizaciones y contenido exclusivo sobre la cobertura de IA líder en la industria. Más información
El reciente lanzamiento de OpenAI o1 ha atraído gran atención a los grandes modelos de razonamiento (LRM) y está inspirando nuevos modelos destinados a resolver problemas complejos con los que a menudo luchan los modelos de lenguaje clásicos. Aprovechando el éxito de o1 y el concepto de LRM, los investigadores de Alibaba han introducido Marco-o1, que mejora las capacidades de razonamiento y aborda problemas con soluciones abiertas donde no existen estándares claros ni recompensas cuantificables.
OpenAI o1 utiliza “escala de tiempo de inferencia” para mejorar la capacidad de razonamiento del modelo dándole “tiempo para pensar”. Básicamente, el modelo utiliza más ciclos de cómputo durante la inferencia para generar más tokens y revisar sus respuestas, lo que mejora su desempeño en tareas que requieren razonamiento. o1 es conocido por sus impresionantes capacidades de razonamiento, especialmente en tareas con respuestas estándar como matemáticas, física y codificación.
Sin embargo, muchas aplicaciones implican problemas abiertos que carecen de soluciones claras y recompensas cuantificables. “Nuestro objetivo era ampliar aún más los límites de los LLM, mejorando sus capacidades de razonamiento para abordar desafíos complejos del mundo real”, escriben los investigadores de Alibaba.
Marco-o1 es una versión mejorada del Qwen2-7B-Instruct de Alibaba que integra técnicas avanzadas como el ajuste de la cadena de pensamiento (CoT), la búsqueda de árboles de Monte Carlo (MCTS) y estrategias de acción de razonamiento.
Los investigadores entrenaron a Marco-o1 en una combinación de conjuntos de datos, incluido el conjunto de datos CoT Open-O1; el conjunto de datos Marco-o1 CoT, un conjunto de datos sintético generado utilizando MCTS; y el conjunto de datos de instrucción Marco-o1, una colección de datos personalizados de seguimiento de instrucciones para tareas de razonamiento.

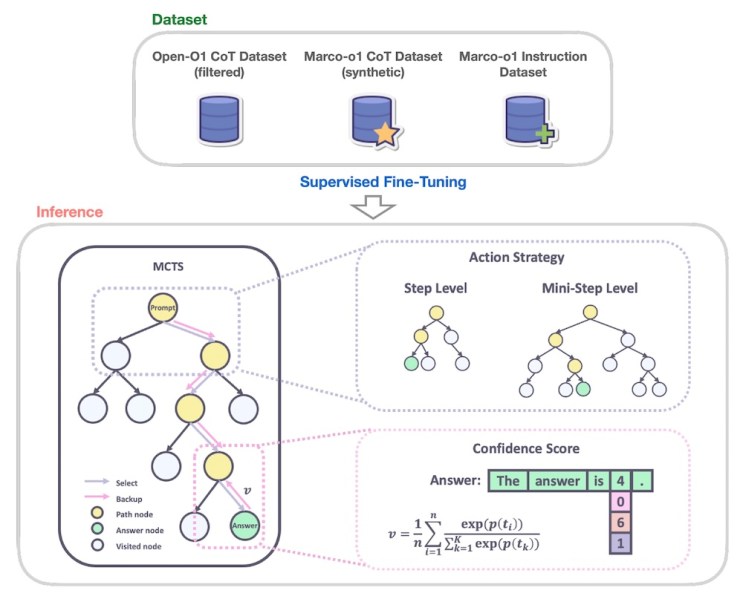
MCTS es un algoritmo de búsqueda que ha demostrado ser eficaz en escenarios complejos de resolución de problemas. Explora de manera inteligente diferentes caminos de solución al muestrear repetidamente posibilidades, simular resultados y construir gradualmente un árbol de decisiones. Ha demostrado ser muy eficaz en problemas complejos de IA, como superar el juego Go.
Marco-o1 aprovecha MCTS para explorar múltiples rutas de razonamiento mientras genera tokens de respuesta. El modelo utiliza las puntuaciones de confianza de los tokens de respuesta de los candidatos para construir su árbol de decisiones y explorar diferentes ramas. Esto permite que el modelo considere una gama más amplia de posibilidades y llegue a conclusiones más informadas y matizadas, especialmente en escenarios con soluciones abiertas. Los investigadores también introdujeron una estrategia de acción de razonamiento flexible que les permite ajustar la granularidad de los pasos MCTS definiendo la cantidad de tokens generados en cada nodo del árbol. Esto proporciona un equilibrio entre precisión y costo computacional, brindando a los usuarios la flexibilidad para equilibrar el rendimiento y la eficiencia.
Otra innovación clave en Marco-o1 es la introducción de un mecanismo de reflexión. Durante el proceso de razonamiento, el modelo periódicamente se incita a sí mismo con la frase “¡Espera! ¡Quizás cometí algunos errores! Necesito repensar desde cero”. Esto hace que el modelo reevalúe sus pasos de razonamiento, identifique errores potenciales y refine su proceso de pensamiento.
“Este enfoque permite que el modelo actúe como su propio crítico, identificando errores potenciales en su razonamiento”, escriben los investigadores. “Al incitar explícitamente al modelo a cuestionar sus conclusiones iniciales, lo alentamos a reexpresar y perfeccionar su proceso de pensamiento”.
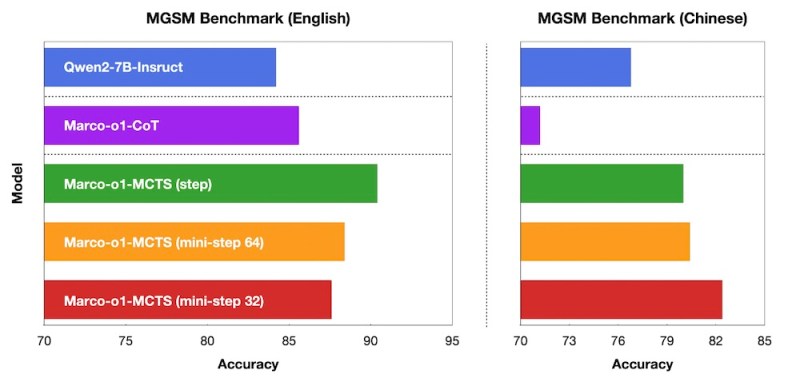
Para evaluar el desempeño de Marco-o1, los investigadores realizaron experimentos en varias tareas, incluido el punto de referencia MGSM, un conjunto de datos para problemas matemáticos multilingües de la escuela primaria. Marco-o1 superó significativamente al modelo base Qwen2-7B, particularmente cuando el componente MCTS se ajustó para la granularidad de un solo token.

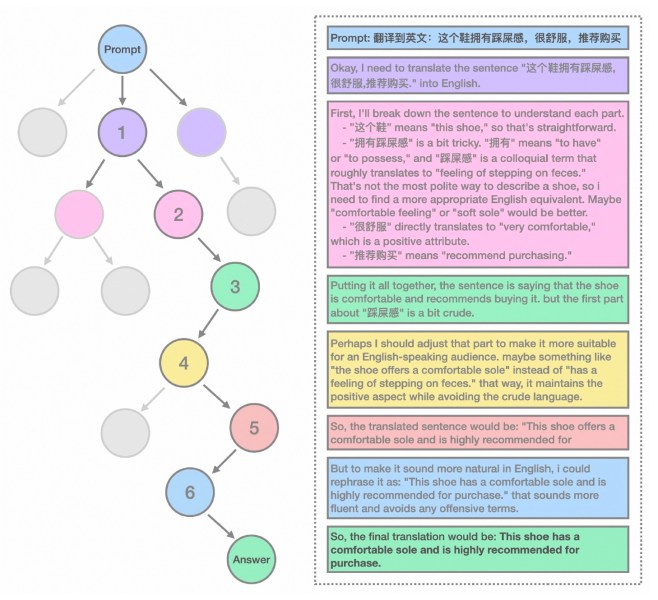
Sin embargo, el objetivo principal de Marco-o1 era abordar los desafíos del razonamiento en escenarios abiertos. Con este fin, los investigadores probaron el modelo en la traducción de expresiones coloquiales y de jerga, una tarea que requiere comprender matices sutiles del idioma, la cultura y el contexto. Los experimentos demostraron que Marco-o1 pudo capturar y traducir estas expresiones de manera más efectiva que las herramientas de traducción tradicionales. Por ejemplo, la modelo tradujo correctamente una expresión coloquial en chino, que literalmente significa “Este zapato ofrece una sensación de pisar caca”, al equivalente en inglés, “Este zapato tiene una suela cómoda”. La cadena de razonamiento del modelo muestra cómo evalúa diferentes significados potenciales y llega a la traducción correcta.
Este paradigma puede resultar útil para tareas como el diseño y la estrategia de productos, que requieren una comprensión profunda y contextual y no tienen puntos de referencia ni métricas bien definidos.

Una nueva ola de modelos de razonamiento
Desde el lanzamiento de o1, los laboratorios de IA se apresuran a lanzar modelos de razonamiento. La semana pasada, el laboratorio chino de IA DeepSeek lanzó R1-Lite-Preview, su competidor o1, que actualmente sólo está disponible a través de la interfaz de chat en línea de la compañía. Según se informa, R1-Lite-Preview supera a o1 en varios puntos de referencia clave.
La comunidad de código abierto también se está poniendo al día con el mercado de modelos privados, lanzando modelos y conjuntos de datos que aprovechan las leyes de escalamiento de tiempo de inferencia. El equipo de Alibaba lanzó Marco-o1 en Hugging Face junto con un conjunto de datos de razonamiento parcial que los investigadores pueden utilizar para entrenar sus propios modelos de razonamiento. Otro modelo lanzado recientemente es LLaVA-o1, desarrollado por investigadores de varias universidades de China, que lleva el paradigma de razonamiento en tiempo de inferencia a modelos de lenguaje de visión (VLM) de código abierto.
El lanzamiento de estos modelos se produce en medio de la incertidumbre sobre el futuro de las leyes de escalado de modelos. Varios informes indican que los beneficios del entrenamiento de modelos más grandes están disminuyendo y podrían estar chocando contra una pared. Pero lo que es seguro es que apenas estamos comenzando a explorar las posibilidades de escalar el tiempo de inferencia.