Noticias
La generación de imágenes de IA multimodal nativa de Google en Gemini 2.0 Flash impresiona con ediciones rápidas, transferencias de estilo
Únase a nuestros boletines diarios y semanales para obtener las últimas actualizaciones y contenido exclusivo sobre la cobertura de IA líder de la industria. Obtenga más información
El último modelo de IA de código abierto de Google, Gemma 3, no es la única gran noticia de la subsidiaria del alfabeto hoy.
No, de hecho, el centro de atención puede haber sido robado por Gemini 2.0 Flash de Google con la generación de imágenes nativas, un nuevo modelo experimental disponible para los usuarios de Google AI Studio y para los desarrolladores a través de la API Gemini de Google.
Marca la primera vez que una importante compañía de tecnología estadounidense ha enviado una generación de imágenes multimodales directamente dentro de un modelo a los consumidores. La mayoría de las otras herramientas de generación de imágenes de IA fueron modelos de difusión (imagen específicos de la imagen) conectados a modelos de lenguaje grande (LLM), lo que requiere un poco de interpretación entre dos modelos para derivar una imagen que el usuario solicitó en un mensaje de texto.
Por el contrario, Gemini 2.0 Flash puede generar imágenes de forma nativa dentro del mismo modelo en el que el texto de los tipos de usuario indica, lo que teóricamente permite una mayor precisión y más capacidades, y las primeras indicaciones son que esto es completamente cierto.
Gemini 2.0 Flash, presentado por primera vez en diciembre de 2024, pero sin la capacidad de generación de imágenes nativa activada para los usuarios, integra la entrada multimodal, el razonamiento y la comprensión del lenguaje natural para generar imágenes junto con el texto.
La versión experimental recientemente disponible, Gemini-2.0-Flash-Exp, permite a los desarrolladores crear ilustraciones, refinar imágenes a través de la conversación y generar imágenes detalladas basadas en el conocimiento mundial.
Cómo Gemini 2.0 Flash mejora las imágenes generadas por IA
En una publicación de blog que orienta el desarrollador publicada el día de hoy, Google destaca varias capacidades clave de Géminis 2.0 flash Generación de imágenes nativas:
• TEXTO E IMAGEN NORATRA: Los desarrolladores pueden usar Gemini 2.0 Flash para generar historias ilustradas mientras mantienen la consistencia en personajes y configuraciones. El modelo también responde a la retroalimentación, lo que permite a los usuarios ajustar la historia o cambiar el estilo de arte.
• Edición de imagen conversacional: La IA es compatible edición múltiplelo que significa que los usuarios pueden refinar iterativamente una imagen proporcionando instrucciones a través de indicaciones de lenguaje natural. Esta característica permite la colaboración en tiempo real y la exploración creativa.
• Generación de imágenes basada en el conocimiento mundial: A diferencia de muchos otros modelos de generación de imágenes, Gemini 2.0 Flash aprovecha las capacidades de razonamiento más amplias para producir imágenes más contextualmente relevantes. Por ejemplo, puede ilustrar recetas con imágenes detalladas que se alinean con los ingredientes del mundo real y los métodos de cocción.
• Representación de texto mejorado: Muchos modelos de imagen de IA luchan para generar con precisión el texto legible dentro de las imágenes, a menudo produciendo errores ortográficos o personajes distorsionados. Google informa que Gemini 2.0 flash supera a los competidores líderes En la representación de texto, haciéndolo particularmente útil para anuncios, publicaciones en redes sociales e invitaciones.
Los ejemplos iniciales muestran un potencial y promesa increíbles
Googlers y algunos usuarios de IA encierran a X para compartir ejemplos de las nuevas capacidades de generación de imágenes y edición que se ofrecen a través de Gemini 2.0 Flash Experimental, y sin duda fueron impresionantes.
El investigador de Google Deepmind, Robert Riachi, mostró cómo el modelo puede generar imágenes en un estilo de píxel y luego crear otras nuevas en el mismo estilo basado en las indicaciones de texto.



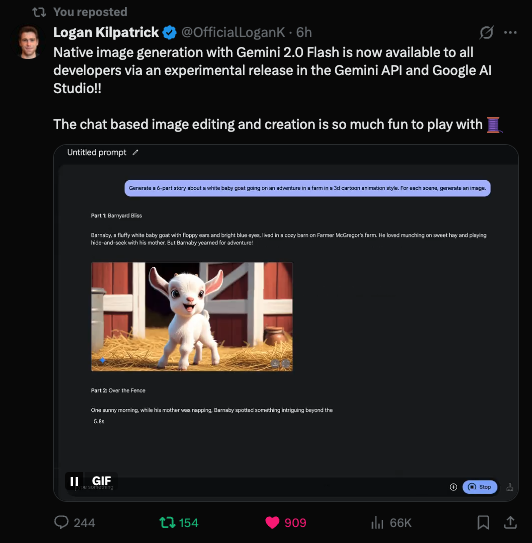
AI News Cuenta TestingCatalog News informó sobre el despliegue de las capacidades multimodales de Gemini 2.0 Flash Experimental, señalando que Google es el primer laboratorio importante en implementar esta función.


El usuario @angaisb_, también conocido como “Angel”, se mostró en un ejemplo convincente cómo una solicitud para “agregar llovizna de chocolate” modificó una imagen existente de cruasanes en segundos, revelando las capacidades de edición de imágenes rápidas y precisas de Gemini 2.0 Flash a través de simplemente chatear de un lado a otro con el modelo.


Teóricamente, los medios de comunicación de YouTuber señalaron que esta edición de imagen incremental sin regeneración total es algo que la industria de la IA ha anticipado durante mucho tiempo, lo que demuestra cómo era fácil pedirle a Gemini 2.0 Flash que editara una imagen para elevar el brazo de un personaje mientras preservaba todo el resto de la imagen.


El ex Googler convertido en AI YouTuber Bilawal Sidhu mostró cómo el modelo colorea las imágenes en blanco y negro, insinuando una potencial restauración histórica o aplicaciones de mejora creativa.

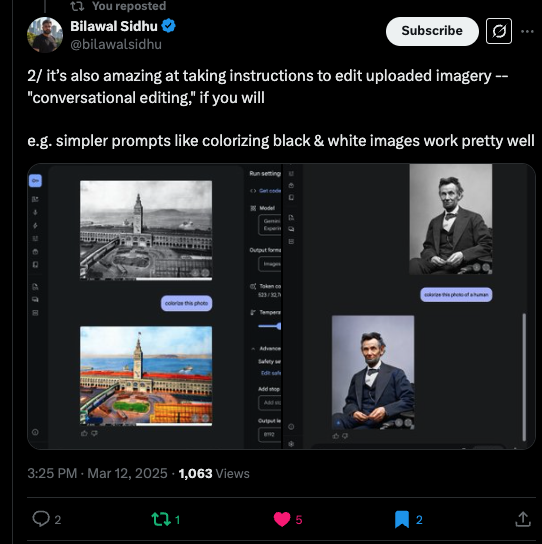
Estas reacciones tempranas sugieren que los desarrolladores y los entusiastas de la IA ven Gemini 2.0 Flash como una herramienta altamente flexible para el diseño iterativo, la narración creativa y la edición visual asistida por AI-AI.
El lanzamiento de Swift también contrasta con el GPT-4O de Opensei, que previseció las capacidades nativas de generación de imágenes en mayo de 2024, hace casi un año, pero aún no ha lanzado la función públicamente, le permite a Google aprovechar una oportunidad para liderar la implementación de IA multimodal.
Como el usuario @chatgpt21, también conocido como “Chris”, señaló en X, Operai tiene en este caso “Loss[t] El año + liderazgo ”que tenía en esta capacidad por razones desconocidas. El usuario invitó a cualquier persona de OpenAI para comentar por qué.


Mis propias pruebas revelaron algunas limitaciones con el tamaño de la relación de aspecto, parecía atascado en 1: 1 para mí, a pesar de pedirle al texto que lo modifique, pero pudo cambiar la dirección de los caracteres en una imagen en cuestión de segundos.

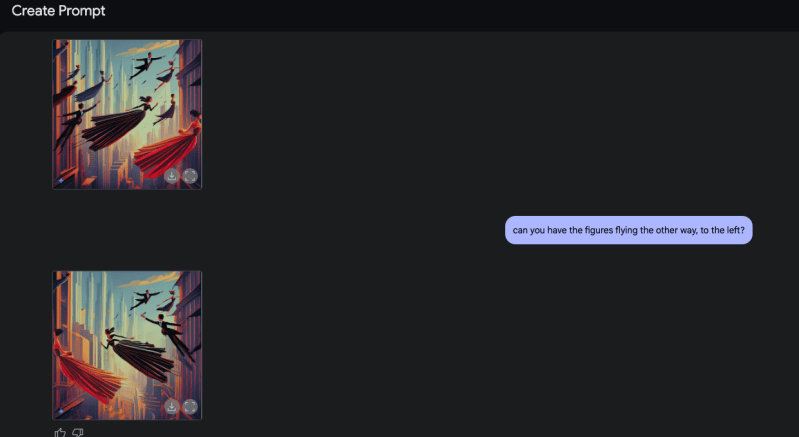
Si bien gran parte de la discusión inicial sobre la generación de imágenes nativas de Gemini 2.0 Flash se ha centrado en usuarios individuales y aplicaciones creativas, sus implicaciones para equipos empresariales, desarrolladores y arquitectos de software son significativas.
Diseño y marketing de IA a escala: Para los equipos de marketing y los creadores de contenido, Gemini 2.0 Flash podría servir como una alternativa rentable a los flujos de trabajo de diseño gráfico tradicionales, automatizando la creación de contenido de marca, anuncios y imágenes en las redes sociales. Dado que admite la representación de texto dentro de las imágenes, podría optimizar la creación de anuncios, el diseño del empaque y los gráficos promocionales, reduciendo la dependencia de la edición manual.
Herramientas de desarrollador mejoradas y flujos de trabajo de IA: para CTO, CIO e ingenieros de software, la generación de imágenes nativas podría simplificar la integración de IA en aplicaciones y servicios. Al combinar salidas de texto e imágenes en un solo modelo, Gemini 2.0 Flash permite a los desarrolladores construir:
- Asistentes de diseño con IA que generan maquetas UI/UX o activos de aplicaciones.
- Herramientas de documentación automatizadas que ilustran conceptos en tiempo real.
- Plataformas dinámicas de narración de historias impulsadas por IA para medios y educación.
Dado que el modelo también admite la edición de imágenes conversacionales, los equipos podrían desarrollar interfaces impulsadas por la IA donde los usuarios refinan los diseños a través del diálogo natural, bajando la barrera de entrada para usuarios no técnicos.
Nuevas posibilidades para el software de productividad impulsado por IA: Para equipos empresariales que construyen herramientas de productividad con IA, Gemini 2.0 Flash podría admitir aplicaciones como:
- Generación de presentación automatizada con diapositivas y imágenes creadas por AI.
- Anotación de documentos legales y comerciales con infografías generadas por IA.
- Visualización de comercio electrónico, generando dinámicamente maquetas de productos basados en descripciones.
Cómo implementar y experimentar con esta capacidad
Los desarrolladores pueden comenzar a probar las capacidades de generación de imágenes de Gemini 2.0 Flash utilizando la API de Gemini. Google proporciona una solicitud de API de muestra para demostrar cómo los desarrolladores pueden generar historias ilustradas con texto e imágenes en una sola respuesta:
from google import genai
from google.genai import types
client = genai.Client(api_key="GEMINI_API_KEY")
response = client.models.generate_content(
model="gemini-2.0-flash-exp",
contents=(
"Generate a story about a cute baby turtle in a 3D digital art style. "
"For each scene, generate an image."
),
config=types.GenerateContentConfig(
response_modalities=["Text", "Image"]
),
)Al simplificar la generación de imágenes con AI, Gemini 2.0 Flash ofrece a los desarrolladores nuevas formas de crear contenido ilustrado, diseñar aplicaciones asistidas por AI y experimentar con la narración visual.

