Noticias
La IA Gemini de Google acaba de romper las reglas del procesamiento visual: esto es lo que eso significa para usted
Únase a nuestros boletines diarios y semanales para obtener las últimas actualizaciones y contenido exclusivo sobre la cobertura de IA líder en la industria. Más información
Gemini AI de Google ha trastocado silenciosamente el panorama de la inteligencia artificial, logrando un hito que pocos creían posible: el procesamiento simultáneo de múltiples flujos visuales en tiempo real.
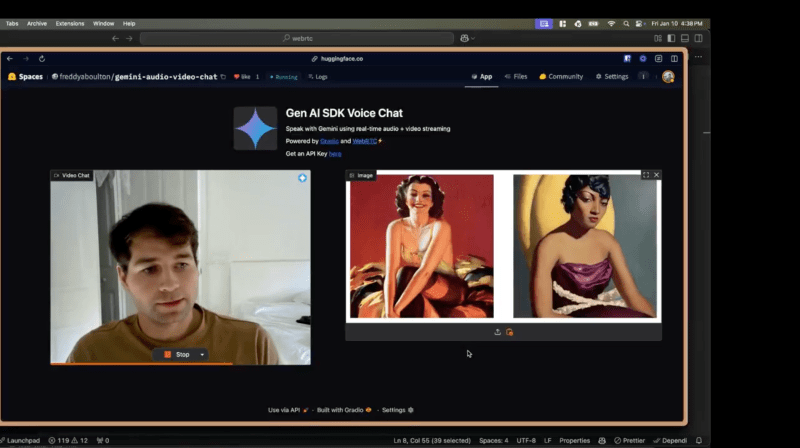
Este avance, que permite a Gemini no solo ver videos en vivo sino también analizar imágenes estáticas simultáneamente, no se dio a conocer a través de las plataformas emblemáticas de Google. En cambio, surgió de una aplicación experimental llamada “AnyChat”.
Este salto imprevisto subraya el potencial sin explotar de la arquitectura de Gemini, ampliando los límites de la capacidad de la IA para manejar interacciones complejas y multimodales. Durante años, las plataformas de IA se han limitado a gestionar transmisiones de vídeo en directo o fotografías estáticas, pero nunca ambas a la vez. Con AnyChat, esa barrera se ha roto decisivamente.
“Ni siquiera el servicio pago de Gemini puede hacer esto todavía”, dice Ahsen Khaliq, líder de aprendizaje automático en Gradio y creador de AnyChat, en una entrevista exclusiva con VentureBeat. “Ahora puedes tener una conversación real con la IA mientras procesa tanto tu video en vivo como cualquier imagen que quieras compartir”.

Cómo Gemini de Google está redefiniendo silenciosamente la visión de la IA
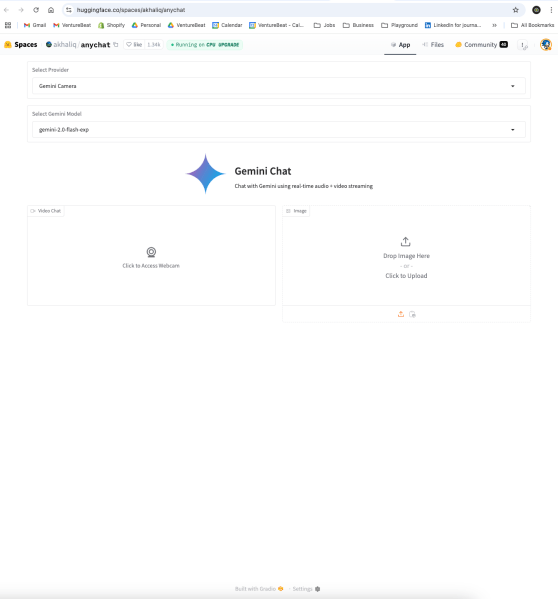
El logro técnico detrás de la capacidad de transmisión múltiple de Gemini radica en su arquitectura neuronal avanzada, una infraestructura que AnyChat explota hábilmente para procesar múltiples entradas visuales sin sacrificar el rendimiento. Esta capacidad ya existe en la API de Gemini, pero no está disponible en las aplicaciones oficiales de Google para los usuarios finales.
Por el contrario, las demandas computacionales de muchas plataformas de IA, incluido ChatGPT, las limitan al procesamiento de un solo flujo. Por ejemplo, ChatGPT actualmente desactiva la transmisión de video en vivo cuando se carga una imagen. Incluso manejar una sola transmisión de video puede agotar los recursos, y mucho menos combinarla con el análisis de imágenes estáticas.
Las aplicaciones potenciales de este avance son tan transformadoras como inmediatas. Los estudiantes ahora pueden apuntar su cámara a un problema de cálculo mientras le muestran a Gemini un libro de texto como guía paso a paso. Los artistas pueden compartir trabajos en progreso junto con imágenes de referencia, recibiendo comentarios matizados y en tiempo real sobre la composición y la técnica.

La tecnología detrás del avance de la IA de flujo múltiple de Gemini
Lo que hace que el logro de AnyChat sea notable no es sólo la tecnología en sí, sino la forma en que elude las limitaciones del despliegue oficial de Gemini. Este avance fue posible gracias a las prestaciones especializadas de la API Gemini de Google, que permiten a AnyChat acceder a funciones que siguen ausentes en las propias plataformas de Google.
Al utilizar estos permisos ampliados, AnyChat optimiza los mecanismos de atención de Gemini para rastrear y analizar múltiples entradas visuales simultáneamente, todo mientras mantiene la coherencia conversacional. Los desarrolladores pueden replicar fácilmente esta capacidad usando unas pocas líneas de código, como lo demuestra el uso de Gradio por parte de AnyChat, una plataforma de código abierto para crear interfaces de aprendizaje automático.
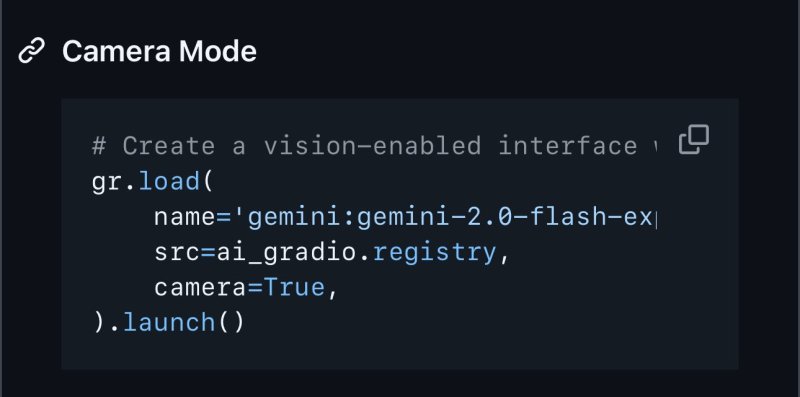
Por ejemplo, los desarrolladores pueden lanzar su propia plataforma de video chat impulsada por Gemini con soporte para carga de imágenes utilizando el siguiente fragmento de código:

(Crédito: Cara de abrazo / Gradio)
Esta simplicidad resalta cómo AnyChat no es solo una demostración del potencial de Gemini, sino un conjunto de herramientas para desarrolladores que buscan crear aplicaciones de IA personalizadas habilitadas para visión.
Lo que hace que el logro de AnyChat sea notable no es sólo la tecnología en sí, sino la forma en que elude las limitaciones del despliegue oficial de Gemini. Este avance fue posible gracias a asignaciones especializadas del equipo Gemini de Google, que permitieron a AnyChat acceder a funciones que permanecen ausentes en las propias plataformas de Google.
“La función de vídeo en tiempo real de Google AI Studio no puede manejar imágenes cargadas durante la transmisión”, dijo Khaliq a VentureBeat. “Ninguna otra plataforma ha implementado este tipo de procesamiento simultáneo en este momento”.
La aplicación experimental que desbloqueó las capacidades ocultas de Gemini
El éxito de AnyChat no fue un simple accidente. Los desarrolladores de la plataforma trabajaron estrechamente con la arquitectura técnica de Gemini para ampliar sus límites. Al hacerlo, revelaron un lado de Gemini que ni siquiera las herramientas oficiales de Google han explorado aún.
Este enfoque experimental permitió a AnyChat manejar transmisiones simultáneas de video en vivo e imágenes estáticas, rompiendo esencialmente la “barrera de la transmisión única”. El resultado es una plataforma que se siente más dinámica, intuitiva y capaz de manejar casos de uso del mundo real de manera mucho más efectiva que sus competidores.
Por qué el procesamiento visual simultáneo cambia las reglas del juego
Las implicaciones de las nuevas capacidades de Gemini van mucho más allá de las herramientas creativas y las interacciones casuales de IA. Imagine a un profesional médico mostrando a una IA los síntomas de un paciente en vivo y escaneos de diagnóstico históricos al mismo tiempo. Los ingenieros podían comparar el rendimiento del equipo en tiempo real con esquemas técnicos y recibir comentarios instantáneos. Los equipos de control de calidad podrían comparar la producción de la línea de producción con los estándares de referencia con una precisión y eficiencia sin precedentes.
En educación, el potencial es transformador. Los estudiantes pueden usar Gemini en tiempo real para analizar libros de texto mientras trabajan en problemas de práctica, recibiendo apoyo contextual que cierra la brecha entre entornos de aprendizaje estáticos y dinámicos. Para los artistas y diseñadores, la capacidad de mostrar múltiples aportaciones visuales simultáneamente abre nuevas vías para la colaboración y la retroalimentación creativa.
Qué significa el éxito de AnyChat para el futuro de la innovación en IA
Por ahora, AnyChat sigue siendo una plataforma de desarrollo experimental, que opera con límites de velocidad ampliados otorgados por los desarrolladores de Gemini. Sin embargo, su éxito demuestra que la visión simultánea de múltiples flujos de IA ya no es una aspiración lejana: es una realidad presente, lista para su adopción a gran escala.
La aparición de AnyChat plantea preguntas provocativas. ¿Por qué el lanzamiento oficial de Gemini no incluyó esta capacidad? ¿Es un descuido, una elección deliberada en la asignación de recursos o una indicación de que desarrolladores más pequeños y ágiles están impulsando la próxima ola de innovación?
A medida que se acelera la carrera de la IA, la lección de AnyChat es clara: es posible que los avances más significativos no siempre provengan de los crecientes laboratorios de investigación de los gigantes tecnológicos. En cambio, pueden provenir de desarrolladores independientes que ven potencial en las tecnologías existentes y se atreven a impulsarlas más.
Ahora que la innovadora arquitectura de Gemini ha demostrado ser capaz de procesar múltiples flujos, el escenario está preparado para una nueva era de aplicaciones de IA. Aún es incierto si Google incorporará esta capacidad a sus plataformas oficiales. Sin embargo, una cosa está clara: la brecha entre lo que la IA puede hacer y lo que hace oficialmente se ha vuelto mucho más interesante.

