Noticias
Los investigadores de OpenAI proponen un enfoque de aprendizaje por refuerzo de varios pasos para mejorar el equipo rojo de LLM
A medida que el uso de modelos de lenguaje grande (LLM) se vuelve cada vez más frecuente en aplicaciones del mundo real, aumentan las preocupaciones sobre sus vulnerabilidades. A pesar de sus capacidades, los LLM todavía son susceptibles a varios tipos de ataques adversarios, incluidos aquellos que generan contenido tóxico, revelan información privada o permiten inyecciones rápidas. Estas vulnerabilidades plantean importantes preocupaciones éticas en cuanto a prejuicios, desinformación, posibles violaciones de la privacidad y abuso del sistema. La necesidad de una estrategia eficaz para abordar estas cuestiones es apremiante. Tradicionalmente, el equipo rojo (un proceso que implica probar los sistemas de IA mediante la simulación de ataques) ha sido eficaz para la detección de vulnerabilidades. Sin embargo, los enfoques anteriores para la formación de equipos rojos automatizados a menudo han tenido dificultades para equilibrar la diversidad de ataques generados y su efectividad, lo que limita la solidez de los modelos.
Para abordar estos desafíos, los investigadores de OpenAI proponen un enfoque para el equipo rojo automatizado que incorpora diversidad y efectividad en los ataques generados. Esto se logra descomponiendo el proceso de formación de equipos rojos en dos pasos distintos. El primer paso implica generar diversos objetivos de atacante, mientras que el segundo paso entrena a un atacante de aprendizaje por refuerzo (RL) para alcanzar estos objetivos de manera efectiva. El método propuesto utiliza aprendizaje por refuerzo de varios pasos (RL de varios pasos) y generación automatizada de recompensas. Este enfoque implica aprovechar grandes modelos de lenguaje para generar objetivos de atacantes y utilizar recompensas basadas en reglas (RBR) y medidas de diversidad personalizadas para guiar el entrenamiento de RL. Al recompensar a un atacante basado en RL por ser eficaz y distinto de sus intentos anteriores, el método garantiza una mayor diversidad y eficacia de los ataques.


Detalles técnicos
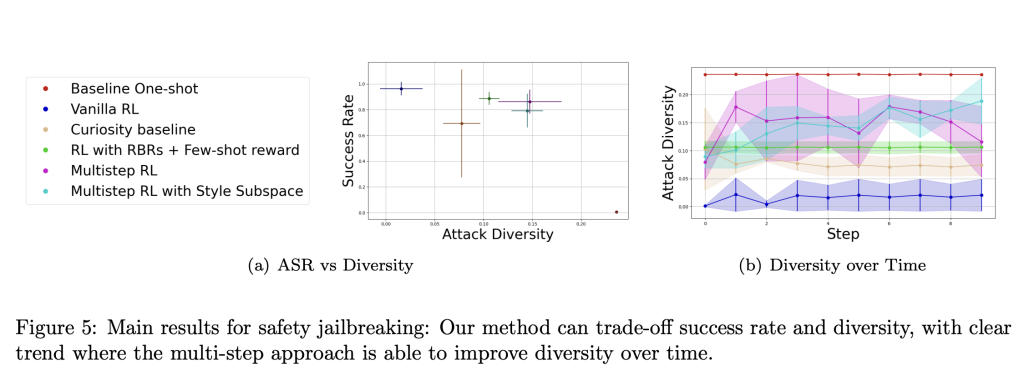
El equipo de investigación describe la descomposición del sistema de equipos rojos en la generación de objetivos y ataques de entrenamiento como un medio para simplificar el proceso y al mismo tiempo lograr resultados sólidos. Para generar objetivos, los autores utilizan tanto indicaciones breves de un modelo de lenguaje como conjuntos de datos existentes de ataques pasados. Estos objetivos sirven como una base diversa, brindando al atacante basado en RL direcciones específicas pero variadas para optimizar. El núcleo del entrenamiento de atacantes basado en RL utiliza una función de recompensa específica basada en reglas para cada ejemplo, lo que garantiza que cada ataque se alinee con un objetivo adversario específico. Además, para evitar que el atacante de RL converja en estrategias de ataque similares, se implementa una recompensa por diversidad que se centra en las diferencias de estilo en las indicaciones generadas. La RL de varios pasos permite al atacante repetir sus propios ataques y ser recompensado por generar con éxito tipos nuevos y variados de ataques, lo que lleva a un sistema de equipos rojos más completo. Este proceso ayuda a identificar las vulnerabilidades del modelo y al mismo tiempo garantiza que la diversidad de ejemplos contradictorios refleje fielmente aquellos que podrían encontrarse en situaciones del mundo real.
La importancia de este enfoque de equipo rojo radica en su capacidad para abordar tanto la efectividad como la diversidad de los ataques, una dualidad que ha sido un desafío de larga data en la generación de adversarios automatizados. Al utilizar RL de varios pasos y recompensas automatizadas, el enfoque permite que los ataques generados sean diversos y relevantes. Los autores demostraron su enfoque en dos aplicaciones clave: ataques de inyección rápida y ataques de “jailbreaking” que provocan respuestas inseguras. En ambos escenarios, el atacante basado en RL de varios pasos mostró una mayor efectividad y diversidad de ataques en comparación con los métodos anteriores. Específicamente, la inyección de aviso indirecto, que puede engañar a un modelo para que genere un comportamiento no deseado, logró una alta tasa de éxito del ataque y tenía un estilo notablemente más variado en comparación con los métodos de aviso de un solo disparo. En general, el método propuesto fue capaz de generar ataques con una tasa de éxito de hasta el 50 %, al tiempo que logró métricas de diversidad sustancialmente más altas que los enfoques anteriores. Esta combinación de generación automatizada de recompensas y aprendizaje reforzado proporciona un mecanismo matizado para probar la solidez del modelo y, en última instancia, mejorar las defensas del LLM contra amenazas del mundo real.

Conclusión
El enfoque de equipo rojo propuesto ofrece una dirección para las pruebas adversas automatizadas de LLM, abordando limitaciones anteriores que involucran compensaciones entre diversidad y efectividad de ataques. Al aprovechar tanto la generación automatizada de objetivos como el RL de varios pasos, esta metodología permite una exploración más detallada de las vulnerabilidades presentes en los LLM, lo que en última instancia ayuda a crear modelos más seguros y sólidos. Si bien los resultados presentados son prometedores, todavía existen limitaciones y áreas para futuras investigaciones, particularmente en el perfeccionamiento de las recompensas automatizadas y la optimización de la estabilidad del entrenamiento. Sin embargo, la combinación de RL con recompensas basadas en reglas y entrenamiento centrado en la diversidad marca un paso importante en las pruebas adversas, proporcionando un modelo que puede responder mejor a la naturaleza cambiante de los ataques.
Verificar el periódico aquí. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Conferencia virtual gratuita sobre GenAI con Meta, Mistral, Salesforce, Harvey AI y más. Únase a nosotros el 11 de diciembre en este evento virtual gratuito para aprender lo que se necesita para construir a lo grande con modelos pequeños de pioneros de la IA como Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face y más.


Asif Razzaq es el director ejecutivo de Marktechpost Media Inc.. Como emprendedor e ingeniero visionario, Asif está comprometido a aprovechar el potencial de la inteligencia artificial para el bien social. Su esfuerzo más reciente es el lanzamiento de una plataforma de medios de inteligencia artificial, Marktechpost, que se destaca por su cobertura en profundidad del aprendizaje automático y las noticias sobre aprendizaje profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el público.
🐝🐝 Lea este informe de investigación de IA de Kili Technology sobre ‘Evaluación de vulnerabilidades de modelos de lenguaje grandes: un análisis comparativo de las técnicas de Red Teaming’