Noticias
O3 de OpenAI muestra un progreso notable en ARC-AGI, lo que genera un debate sobre el razonamiento de la IA
Únase a nuestros boletines diarios y semanales para obtener las últimas actualizaciones y contenido exclusivo sobre la cobertura de IA líder en la industria. Más información
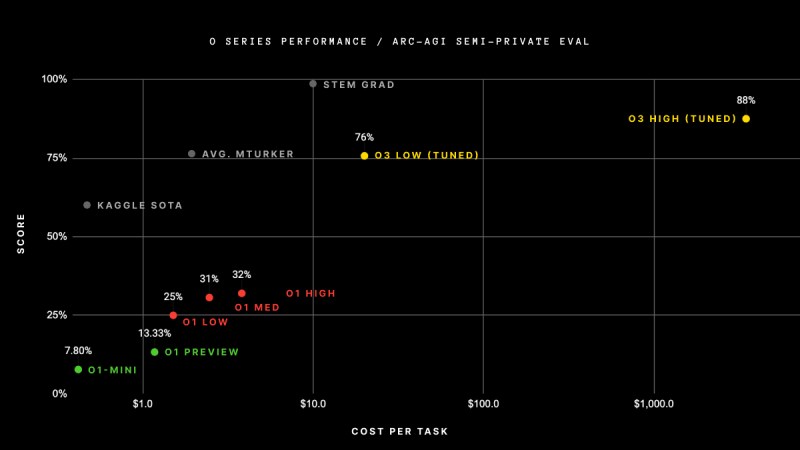
El último modelo o3 de OpenAI ha logrado un gran avance que ha sorprendido a la comunidad de investigación de IA. o3 obtuvo una puntuación sin precedentes del 75,7 % en el súper difícil punto de referencia ARC-AGI en condiciones de computación estándar, y una versión de alta computación alcanzó el 87,5 %.
Si bien el logro en ARC-AGI es impresionante, aún no prueba que se haya descifrado el código de la inteligencia artificial general (AGI).
Corpus de razonamiento abstracto
El punto de referencia ARC-AGI se basa en el Abstract Reasoning Corpus, que prueba la capacidad de un sistema de IA para adaptarse a tareas novedosas y demostrar una inteligencia fluida. ARC se compone de un conjunto de acertijos visuales que requieren la comprensión de conceptos básicos como objetos, límites y relaciones espaciales. Si bien los humanos pueden resolver fácilmente los acertijos ARC con muy pocas demostraciones, los sistemas de inteligencia artificial actuales tienen dificultades con ellos. ARC se ha considerado durante mucho tiempo una de las medidas de IA más desafiantes.


ARC ha sido diseñado de manera que no pueda ser engañado entrenando modelos con millones de ejemplos con la esperanza de cubrir todas las combinaciones posibles de acertijos.
El punto de referencia se compone de un conjunto de formación pública que contiene 400 ejemplos sencillos. El conjunto de capacitación se complementa con un conjunto de evaluación pública que contiene 400 acertijos que son más desafiantes como medio para evaluar la generalización de los sistemas de IA. El Desafío ARC-AGI contiene conjuntos de prueba privados y semiprivados de 100 rompecabezas cada uno, que no se comparten con el público. Se utilizan para evaluar sistemas de IA candidatos sin correr el riesgo de filtrar los datos al público y contaminar sistemas futuros con conocimientos previos. Además, la competencia establece límites en la cantidad de cálculos que los participantes pueden utilizar para garantizar que los acertijos no se resuelvan mediante métodos de fuerza bruta.
Un gran avance en la resolución de tareas novedosas
o1-preview y o1 obtuvieron un máximo de 32% en ARC-AGI. Otro método desarrollado por el investigador Jeremy Berman utilizó un enfoque híbrido, combinando Claude 3.5 Sonnet con algoritmos genéticos y un intérprete de código para lograr un 53%, la puntuación más alta antes de o3.
En una publicación de blog, François Chollet, el creador de ARC, describió el desempeño de o3 como “un aumento sorprendente e importante de la función escalonada en las capacidades de IA, que muestra una capacidad novedosa de adaptación de tareas nunca antes vista en los modelos de la familia GPT”.
Es importante señalar que el uso de más computación en generaciones anteriores de modelos no pudo alcanzar estos resultados. Para ponerlo en contexto, los modelos tardaron 4 años en progresar del 0% con GPT-3 en 2020 a solo el 5% con GPT-4o a principios de 2024. Si bien no sabemos mucho sobre la arquitectura de o3, podemos estar seguros de que sí. no es un orden de magnitud mayor que sus predecesores.

“Esto no es simplemente una mejora incremental, sino un avance genuino, que marca un cambio cualitativo en las capacidades de la IA en comparación con las limitaciones anteriores de los LLM”, escribió Chollet. “o3 es un sistema capaz de adaptarse a tareas que nunca antes había encontrado, posiblemente acercándose al rendimiento a nivel humano en el dominio ARC-AGI”.
Vale la pena señalar que el rendimiento de o3 en ARC-AGI tiene un costo elevado. En la configuración de computación baja, al modelo le cuesta entre 17 y 20 dólares y 33 millones de tokens resolver cada rompecabezas, mientras que en la configuración de computación alta, el modelo utiliza alrededor de 172 veces más computación y miles de millones de tokens por problema. Sin embargo, a medida que los costos de la inferencia sigan disminuyendo, podemos esperar que estas cifras se vuelvan más razonables.
¿Un nuevo paradigma en el razonamiento LLM?
La clave para resolver problemas novedosos es lo que Chollet y otros científicos denominan “síntesis de programas”. Un sistema de pensamiento debería ser capaz de desarrollar pequeños programas para resolver problemas muy específicos y luego combinar estos programas para abordar problemas más complejos. Los modelos de lenguaje clásicos han absorbido mucho conocimiento y contienen un rico conjunto de programas internos. Pero carecen de composicionalidad, lo que les impide resolver acertijos que están más allá de su distribución de entrenamiento.
Desafortunadamente, hay muy poca información sobre cómo funciona el o3 bajo el capó, y aquí las opiniones de los científicos divergen. Chollet especula que o3 utiliza un tipo de síntesis de programa que utiliza razonamiento de cadena de pensamiento (CoT) y un mecanismo de búsqueda combinado con un modelo de recompensa que evalúa y refina las soluciones a medida que el modelo genera tokens. Esto es similar a lo que los modelos de razonamiento de código abierto han estado explorando en los últimos meses.
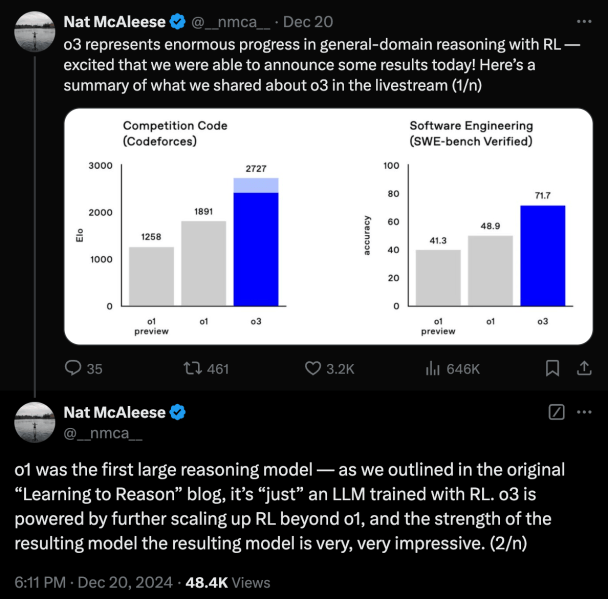
Otros científicos como Nathan Lambert del Instituto Allen de IA sugieren que “o1 y o3 pueden ser en realidad sólo pasos directos de un modelo de lenguaje”. El día en que se anunció o3, Nat McAleese, investigador de OpenAI, publicó en X que o1 era “solo un LLM capacitado con RL. o3 está impulsado por una mayor ampliación de RL más allá de o1”.

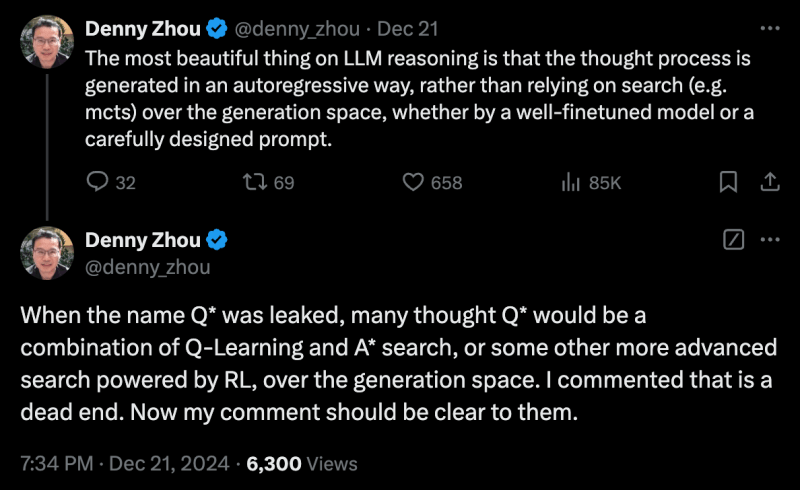
El mismo día, Denny Zhou, del equipo de razonamiento de Google DeepMind, calificó la combinación de búsqueda y los enfoques actuales de aprendizaje por refuerzo como un “callejón sin salida”.
“Lo más hermoso del razonamiento LLM es que el proceso de pensamiento se genera de forma autorregresiva, en lugar de depender de la búsqueda (por ejemplo, mcts) en el espacio generacional, ya sea mediante un modelo bien ajustado o un mensaje cuidadosamente diseñado”, publicó. en X.

Si bien los detalles de las razones de o3 pueden parecer triviales en comparación con el avance de ARC-AGI, pueden definir muy bien el próximo cambio de paradigma en la formación de LLM. Actualmente existe un debate sobre si las leyes de escalamiento de los LLM a través de datos de entrenamiento y computación se han topado con un muro. Si el escalado en el tiempo de prueba depende de mejores datos de entrenamiento o de diferentes arquitecturas de inferencia puede determinar el siguiente camino a seguir.
No AGI
El nombre ARC-AGI es engañoso y algunos lo han comparado con resolver AGI. Sin embargo, Chollet enfatiza que “ARC-AGI no es una prueba de fuego para AGI”.
“Aprobar ARC-AGI no equivale a alcanzar AGI y, de hecho, no creo que o3 sea AGI todavía”, escribe. “O3 todavía falla en algunas tareas muy fáciles, lo que indica diferencias fundamentales con la inteligencia humana”.
Además, señala que o3 no puede aprender estas habilidades de forma autónoma y depende de verificadores externos durante la inferencia y de cadenas de razonamiento etiquetadas por humanos durante el entrenamiento.
Otros científicos han señalado los defectos de los resultados informados por OpenAI. Por ejemplo, el modelo se ajustó en el conjunto de entrenamiento ARC para lograr resultados de última generación. “El solucionador no debería necesitar mucha ‘formación’ específica, ni en el dominio en sí ni en cada tarea específica”, escribe la científica Melanie Mitchell.
Para verificar si estos modelos poseen el tipo de abstracción y razonamiento para el que se creó el punto de referencia ARC, Mitchell propone “ver si estos sistemas pueden adaptarse a variantes en tareas específicas o a tareas de razonamiento utilizando los mismos conceptos, pero en otros dominios además de ARC. “
Chollet y su equipo están trabajando actualmente en un nuevo punto de referencia que supone un desafío para o3, ya que podría reducir su puntuación a menos del 30 % incluso con un presupuesto de cómputo elevado. Mientras tanto, los humanos podrían resolver el 95% de los acertijos sin ningún entrenamiento.
“Sabrás que AGI está aquí cuando el ejercicio de crear tareas que sean fáciles para los humanos comunes pero difíciles para la IA se vuelva simplemente imposible”, escribe Chollet.

