Noticias
O3 O3 de OpenAi es menos AGI de lo que se mide originalmente
![]()
Resumen

Un análisis reciente de la Fundación del Premio ARC encuentra que el modelo O3 de OpenAI ofrece resultados significativamente más débiles en puntos de referencia de razonamiento estandarizados que su versión de vista previa de O3 previamente probada.
La Fundación del Premio ARC, un grupo sin fines de lucro centrado en la evaluación de IA, utiliza puntos de referencia abiertos como ARC-AGI para resaltar la brecha entre el razonamiento humano y los sistemas de inteligencia artificial actuales. Cada evaluación tiene como objetivo aclarar el estado actual del campo.
El punto de referencia ARC-AGI está estructurado para probar el razonamiento simbólico, la composición de varios pasos y la aplicación de reglas dependiente del contexto, las habilidades que los humanos a menudo demuestran sin capacitación especial, pero que los modelos de IA solo funcionan en un grado limitado.
El análisis evaluó el rendimiento en niveles de razonamiento “bajo”, “medio” y “altos”, que varían la profundidad del razonamiento del modelo. “Bajo” prioriza la velocidad y el uso mínimo de token, mientras que “alto” tiene la intención de fomentar la resolución de problemas más integral. Para este estudio, dos modelos, O3 y O4-Mini, se probaron en los tres niveles de razonamiento en 740 tareas de ARC-AGI-1 y ARC-AGI-2, produciendo 4.400 puntos de datos.
Anuncio
Eficiencia de rentabilidad y rendimiento: O3 Outpacios O1
Según la Fundación del Premio ARC, O3 alcanzó la precisión del 41 por ciento (bajo cálculo) y el 53 por ciento (cómputo medio) en ARC-AGI-1. El modelo O4-Mini más pequeño alcanzó el 21 por ciento (bajo cálculo) y el 42 por ciento (cómputo medio). En el punto de referencia ARC-AGI-2 más desafiante, ambos modelos actuales lucharon considerablemente, anotando por debajo del tres por ciento de precisión.

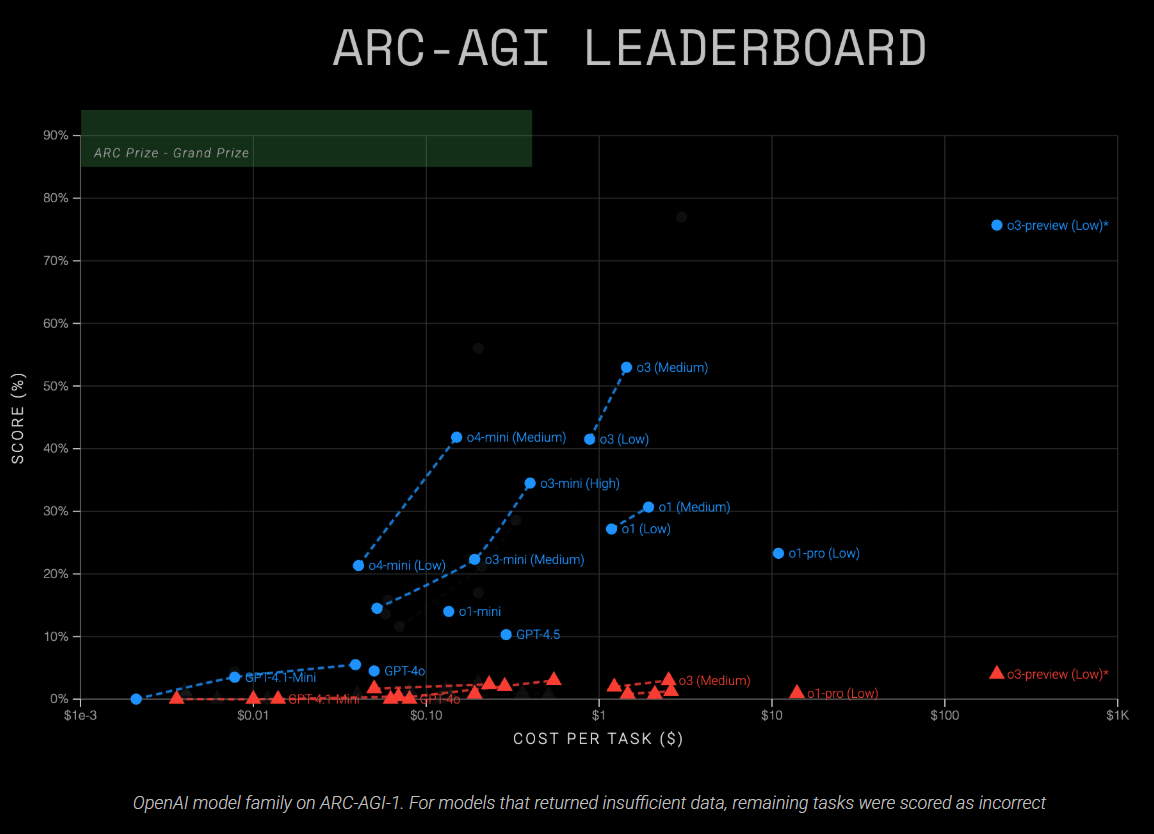
A niveles de razonamiento más altos (cómputo “alto”), ambos modelos no pudieron completar muchas tareas. El análisis también observó que los modelos tendían a responder tareas que podrían resolver más fácilmente, mientras dejaban tareas más difíciles sin respuesta. Evaluar solo las respuestas exitosas distorsionaría el rendimiento real, por lo que estos resultados parciales fueron excluidos de las tablas de clasificación oficiales.
| Modelo | Configuración de razonamiento | Eval Semi Private V1 | Eval Semi Private V2 | Costo por tarea (V2) |
|---|---|---|---|---|
| O3 | Bajo | 41% | 1,9% | 1.22 dólares estadounidenses |
| O3 | Medio | 53% | 2,9% | 2.52 dólares estadounidenses |
| O3 | Alto | – | – | – |
| O4-Mini | Bajo | 21% | 1,6% | 0.05 dólar estadounidense |
| O4-Mini | Medio | 42% | 2,3% | 0.23 dólar estadounidense |
| O4-Mini | Alto | – | – | – |
Los datos muestran que un mayor esfuerzo de razonamiento no garantiza mejores resultados, pero a menudo solo resulta en costos más altos. En particular, O3 High consume significativamente más tokens sin lograr una ganancia correspondiente en precisión para tareas más simples. Esto plantea preguntas sobre la escalabilidad del enfoque actual para el razonamiento de la cadena de pensamiento.

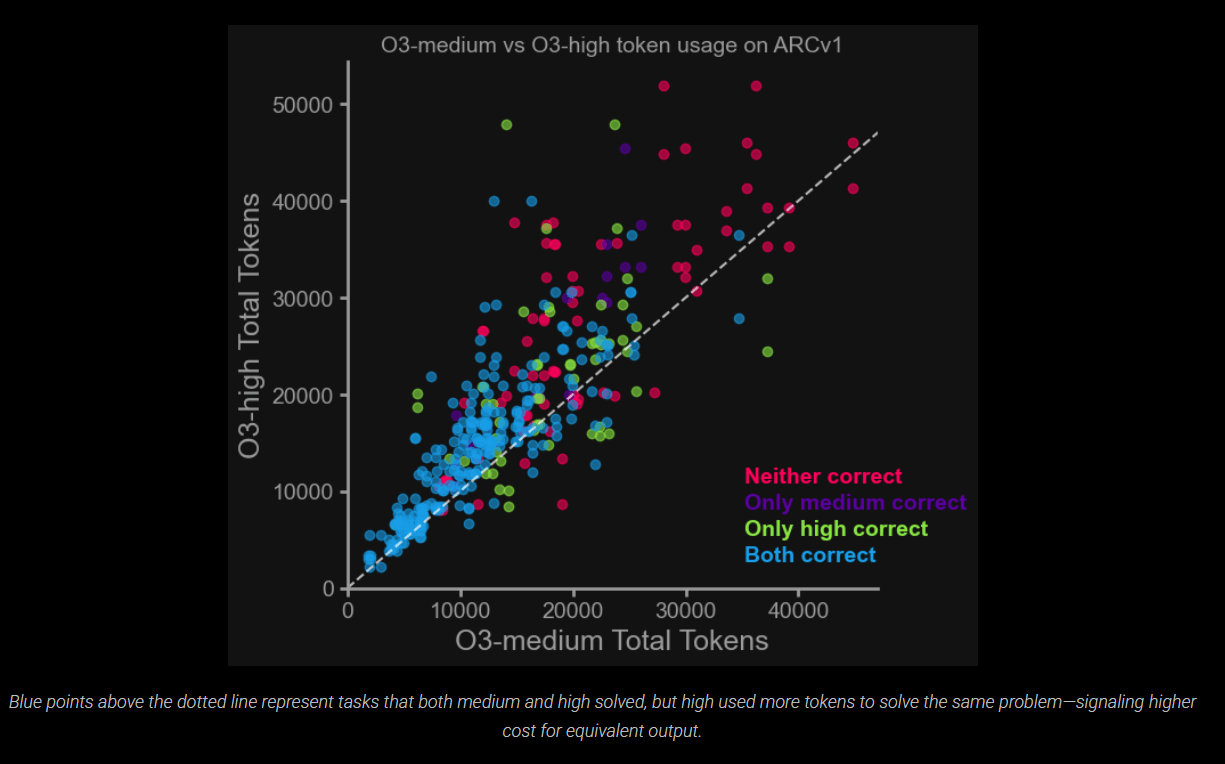
Para aplicaciones sensibles a los costos, la Fundación del Premio ARC aconseja el uso de O3-Medio como la configuración predeterminada. El modo de “alta recuperación” solo se recomienda cuando se necesita la máxima precisión y el costo es menos importante. “No hay una razón convincente para usar bajo si te importa la precisión”, dice Mike Knoop, cofundador de la Fundación del Premio ARC.
La Fundación también señala que, a medida que avanza el rendimiento del modelo, la eficiencia, con qué rapidez, de bajo costo y con el uso mínimo de tokens, un modelo puede resolver problemas, se convierte en el diferenciador primario. En este sentido, O4-Mini es notable: logra una precisión del 21 por ciento en ARC-AGI-1 a un costo de aproximadamente cinco centavos por tarea, mientras que los modelos más antiguos como O1-Pro requieren aproximadamente once dólares por tarea para obtener resultados comparables.
Recomendación


O3 O3 de OpenAI es menos AGI que O3 previa
La versión actual de O3 diverge sustancialmente de la versión de previsión de O3 probada en diciembre de 2024. En ese momento, la previa vista de O3 obtuvo un 76 por ciento (bajo cómputo) y un 88 por ciento (alto cálculo) en ARC-AGI-1 en el modo de texto, mientras que el modelo O3 liberado ahora ofrece 41 por ciento (bajo) y 53 por ciento (medio).
OpenAI confirmó a ARC que el modelo de producción O3 difiere de la versión de vista previa de varias maneras clave. La compañía explicó que el modelo lanzado tiene una arquitectura diferente, es un modelo general más pequeño, opera multimodalmente (manejando las entradas de texto e imágenes) y utiliza menos recursos computacionales que la versión de vista previa.
Con respecto a los datos de capacitación, OpenAI afirma que la capacitación de O3 previa revisión cubrió el 75 por ciento del conjunto de datos ARC-AGI-1. Para el modelo O3 lanzado, OpenAI dice que no fue capacitado directamente en los datos de ARC-AGI, ni siquiera en el conjunto de datos de capacitación. Sin embargo, es posible que el modelo esté expuesto indirectamente al punto de referencia a través de su disponibilidad pública.
El modelo O3 publicado también se ha refinado para los casos de uso de productos y productos, que, según el premio ARC, se presenta tanto en ventajas como en desventajas en el punto de referencia ARC-AGI. Estas diferencias subrayan que los resultados de referencia, especialmente para los modelos de IA inéditos, deben verse con precaución.
Progreso continuo y limitaciones persistentes
El modelo O3-Medium actualmente ofrece el mayor rendimiento entre los modelos de Fundación de Premios ARC de ARC publicados en Publicación en ARC-AGI-1, duplicando los resultados de los enfoques anteriores de la cadena de pensamiento.
A pesar de esta mejora, el recién introducido Arc-Agi-2 Benchmark sigue sin resolverse en gran medida por ambos modelos nuevos. Mientras que los humanos resuelven un promedio del 60 por ciento de las tareas ARC-AGI-2 incluso sin capacitación especial, el modelo de razonamiento más fuerte de OpenAI actualmente logra solo alrededor del tres por ciento.
“ARC V2 tiene un largo camino por recorrer, incluso con la gran eficiencia de razonamiento de O3. Todavía se necesitan nuevas ideas”, escribe Knoop.
Esto destaca una brecha persistente en la capacidad de resolución de problemas entre humanos y máquinas, a pesar de los recientes avances y lo que la CEO de Microsoft, Satya Nadella, ha descrito como “piratería de referencia sin sentido”.
Un análisis reciente también sugiere que los llamados modelos de razonamiento como O3 probablemente no tienen ninguna capacidad nueva más allá de las de sus modelos de lenguaje fundamental. En cambio, estos modelos están optimizados para llegar a soluciones correctas más rápidamente para ciertas tareas, particularmente aquellos para los que han sido entrenados a través del aprendizaje de refuerzo dirigido.