Noticias
OpenAI estabiliza los modelos generativos de tiempo continuo: cómo el marco innovador de TrigFlow redujo la brecha con los modelos de difusión líderes utilizando solo dos pasos de muestreo
Los modelos de inteligencia artificial (IA) generativa están diseñados para crear datos realistas y de alta calidad, como imágenes, audio y video, basados en patrones en grandes conjuntos de datos. Estos modelos pueden imitar distribuciones de datos complejas, produciendo contenido sintético que se asemeja a muestras. Una clase ampliamente reconocida de modelos generativos es el modelo de difusión. Ha logrado generar imágenes y videos invirtiendo una secuencia de ruido agregado a una muestra hasta lograr una salida de alta fidelidad. Sin embargo, los modelos de difusión suelen requerir de decenas a cientos de pasos para completar el proceso de muestreo, lo que exige mucho tiempo y recursos computacionales. Este desafío es especialmente pronunciado en aplicaciones donde el muestreo rápido es esencial o donde se deben generar muchas muestras simultáneamente, como en escenarios en tiempo real o implementaciones a gran escala.
Una limitación importante de los modelos de difusión es la carga computacional del proceso de muestreo, que implica invertir sistemáticamente una secuencia de ruido. Cada paso de esta secuencia es computacionalmente costoso y el proceso introduce errores cuando se discretiza en intervalos de tiempo. Los modelos de difusión en tiempo continuo ofrecen una forma de abordar este problema, ya que eliminan la necesidad de estos intervalos y, por tanto, reducen los errores de muestreo. Sin embargo, los modelos de tiempo continuo no se han adoptado ampliamente debido a la inestabilidad inherente durante el entrenamiento. La inestabilidad dificulta el entrenamiento de estos modelos a gran escala o con conjuntos de datos complejos, lo que ha ralentizado su adopción y desarrollo en áreas donde la eficiencia computacional es crítica.
Los investigadores han desarrollado recientemente métodos para hacer que los modelos de difusión sean más eficientes, con enfoques como la destilación directa, la destilación adversaria, la destilación progresiva y la destilación de puntuación variacional (VSD). Cada método ha demostrado potencial para acelerar el proceso de muestreo o mejorar la calidad de la muestra. Sin embargo, estas técnicas enfrentan desafíos prácticos, que incluyen una alta sobrecarga computacional, configuraciones de entrenamiento complejas y limitaciones en la escalabilidad. Por ejemplo, la destilación directa requiere capacitación desde cero, lo que añade importantes costos de tiempo y recursos. La destilación adversaria presenta desafíos cuando se utilizan arquitecturas GAN (Generative Adversarial Network), que a menudo necesitan ayuda con la estabilidad y coherencia en la salida. Además, aunque son eficaces para modelos de pasos cortos, la destilación progresiva y la VSD suelen producir resultados con diversidad limitada o muestras suaves y menos detalladas, especialmente en niveles de orientación altos.
Un equipo de investigación de OpenAI presentó un nuevo marco llamado flujo trigonométricodiseñado para simplificar, estabilizar y escalar modelos de consistencia de tiempo continuo (CM) de manera efectiva. La solución propuesta se dirige específicamente a los problemas de inestabilidad en el entrenamiento de modelos de tiempo continuo y agiliza el proceso incorporando mejoras en la parametrización del modelo, la arquitectura de red y los objetivos de entrenamiento. TrigFlow unifica los modelos de difusión y consistencia al establecer una nueva formulación que identifica y mitiga las principales causas de la inestabilidad, permitiendo que el modelo maneje tareas de tiempo continuo de manera confiable. Esto permite que el modelo logre un muestreo de alta calidad con costos computacionales mínimos, incluso cuando se escala a grandes conjuntos de datos como ImageNet. Utilizando TrigFlow, el equipo entrenó con éxito un modelo de 1.500 millones de parámetros con un proceso de muestreo de dos pasos que alcanzó puntuaciones de alta calidad con costos computacionales más bajos que los métodos de difusión existentes.
En el centro de TrigFlow hay una redefinición matemática que simplifica el flujo de probabilidad ODE (ecuación diferencial ordinaria) utilizado en el proceso de muestreo. Esta mejora incorpora normalización de grupo adaptativa y una función objetivo actualizada que utiliza ponderación adaptativa. Estas características ayudan a estabilizar el proceso de entrenamiento, permitiendo que el modelo funcione continuamente sin errores de discretización que a menudo comprometen la calidad de la muestra. El enfoque de TrigFlow para el acondicionamiento del tiempo dentro de la arquitectura de red reduce la dependencia de cálculos complejos, lo que hace factible escalar el modelo. El objetivo de entrenamiento reestructurado templa progresivamente los términos críticos en el modelo, permitiéndole alcanzar la estabilidad más rápido y a una escala sin precedentes.

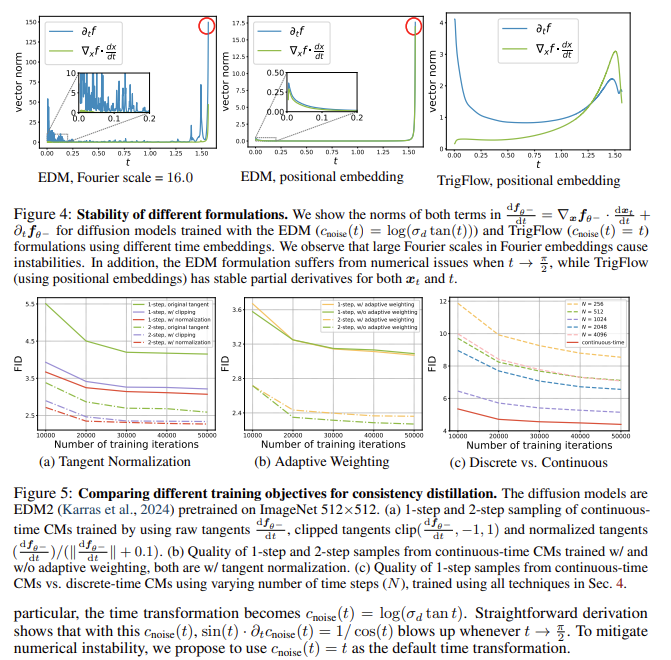
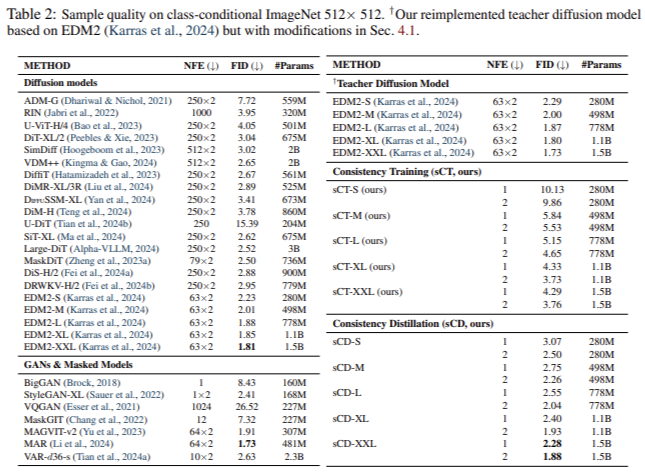
El modelo, denominado “sCM” (modelo de consistencia simple, estable y escalable), demostró resultados comparables a los modelos de difusión de última generación. Por ejemplo, logró una distancia de inicio de Fréchet (FID) de 2,06 en CIFAR-10, 1,48 en ImageNet 64×64 y 1,88 en ImageNet 512×512, lo que reduce significativamente la brecha entre los mejores modelos de difusión, incluso cuando solo se realizan dos pasos de muestreo. fueron utilizados. El modelo de dos pasos mostró una mejora FID de casi el 10 % con respecto a enfoques anteriores que requerían muchos más pasos, lo que marca un aumento sustancial en la eficiencia del muestreo. El marco TrigFlow representa un avance esencial en la escalabilidad del modelo y la eficiencia computacional.
Esta investigación ofrece varias conclusiones clave y demuestra cómo abordar las ineficiencias y limitaciones computacionales de los modelos de difusión tradicionales a través de un modelo de tiempo continuo cuidadosamente estructurado. Al implementar TrigFlow, los investigadores estabilizaron los CM de tiempo continuo y los ampliaron a conjuntos de datos y tamaños de parámetros más grandes con compensaciones computacionales mínimas.

Las conclusiones clave de la investigación incluyen:
- Estabilidad en modelos de tiempo continuo: TrigFlow introduce estabilidad en los modelos de consistencia de tiempo continuo, un área históricamente desafiante, que permite el entrenamiento sin desestabilización frecuente.
- Escalabilidad: El modelo escala con éxito hasta 1.500 millones de parámetros, el mayor entre sus pares para modelos de consistencia en tiempo continuo, lo que permite su uso en la generación de datos de alta resolución.
- Muestreo eficiente: Con solo dos pasos de muestreo, el modelo sCM alcanza puntuaciones FID comparables a los modelos que requieren amplios recursos informáticos, alcanzando 2,06 en CIFAR-10, 1,48 en ImageNet 64×64 y 1,88 en ImageNet 512×512.
- Eficiencia computacional: La ponderación adaptativa y el acondicionamiento de tiempo simplificado dentro del marco TrigFlow hacen que el modelo sea eficiente en cuanto a recursos, lo que reduce la demanda de muestreo intensivo en computación, lo que puede mejorar la aplicabilidad de los modelos de difusión en entornos en tiempo real y a gran escala.


En conclusión, este estudio representa un avance fundamental en el entrenamiento de modelos generativos, abordando la estabilidad, la escalabilidad y la eficiencia del muestreo a través del marco TrigFlow. La arquitectura TrigFlow y el modelo sCM del equipo OpenAI abordan eficazmente los desafíos críticos de los modelos de consistencia de tiempo continuo, presentando una solución estable y escalable que rivaliza con los mejores modelos de difusión en rendimiento y calidad, al tiempo que reduce significativamente los requisitos computacionales.
Mira el Papel y Detalles. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grarriba. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
[Upcoming Live Webinar- Oct 29, 2024] La mejor plataforma para ofrecer modelos optimizados: motor de inferencia Predibase (promocionado)


Nikhil es consultor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida formación en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.
Escuche nuestros últimos podcasts de IA y vídeos de investigación de IA aquí ➡️