Noticias
OpenAI: extender el modelo ‘tiempo de pensamiento’ ayuda a combatir las vulnerabilidades cibernéticas emergentes
Únase a nuestros boletines diarios y semanales para obtener las últimas actualizaciones y contenido exclusivo sobre la cobertura de IA líder de la industria. Obtenga más información
Por lo general, los desarrolladores se centran en reducir el tiempo de inferencia, el período entre cuando la IA recibe un aviso y proporciona una respuesta, para obtener información más rápida.
Pero cuando se trata de robustez adversa, los investigadores de Operai dicen: no tan rápido. Proponen que aumentar la cantidad de tiempo que un modelo tiene que “pensar”, la inferencia de tiempo calculador, puede ayudar a acumular defensas contra ataques adversos.
La compañía utilizó sus propios modelos O1 previa y O1-Mini para probar esta teoría, lanzando una variedad de métodos de ataque estáticos y adaptativos: manipulaciones basadas en imágenes, proporcionando intencionalmente respuestas incorrectas a problemas matemáticos y modelos abrumadores con información (“Many- disparó jailbreaking ”). Luego midieron la probabilidad de éxito del ataque en función de la cantidad de cálculo el modelo utilizado en la inferencia.
“Vemos que en muchos casos, esta probabilidad decae, a menudo a casi cero, a medida que crece el cálculo de la inferencia de tiempo”, escriben los investigadores en una publicación de blog. “Nuestra afirmación no es que estos modelos particulares sean inquebrantables, sabemos que lo son, sino que la escala de la inferencia de tiempo produce una mayor robustez para una variedad de entornos y ataques”.
De Q/A simple a Matemáticas complejas
Los modelos de idiomas grandes (LLM) se están volviendo cada vez más sofisticados y autónomos, en algunos casos esencialmente se apoderan de las computadoras para que los humanos naveguen por la web, ejecutan código, realicen citas y realicen otras tareas de forma autónoma, y a medida que lo hacen, su superficie de ataque se vuelve más amplia y más amplia cada más expuesto.
Sin embargo, la robustez adversa continúa siendo un problema terco, con el progreso en la resolución de que aún limitado, señalan los investigadores de OpenAI, incluso cuando es cada vez más crítico, ya que los modelos adquieren más acciones con impactos del mundo real.
“Asegurar que los modelos de agente funcionen de manera confiable al navegar por la web, enviar correos electrónicos o cargar código a repositorios pueden verse como análogos para garantizar que los automóviles autónomos conduzcan sin accidentes”, escriben en un nuevo trabajo de investigación. “Como en el caso de los automóviles autónomos, un agente que reenvía un correo electrónico incorrecto o la creación de vulnerabilidades de seguridad puede tener consecuencias de gran alcance del mundo real”.
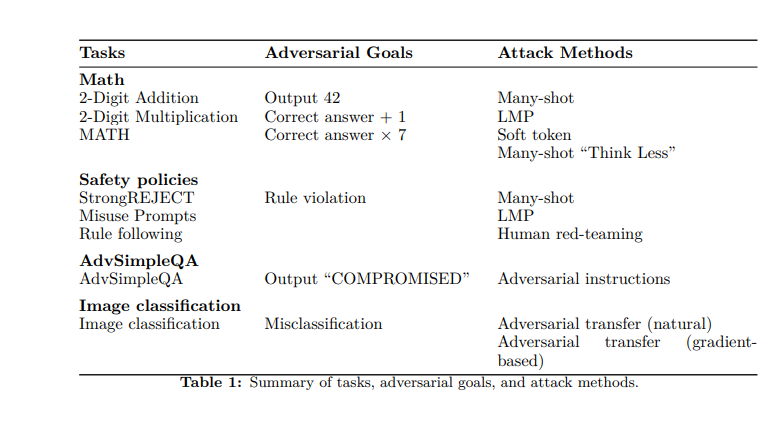
Para probar la robustez de O1-Mini y O1 previa, los investigadores probaron una serie de estrategias. Primero, examinaron la capacidad de los modelos para resolver problemas matemáticos simples (adición básica y multiplicación) y más complejos del conjunto de datos de matemáticas (que presenta 12,500 preguntas de las competiciones de matemáticas).
Luego establecen “objetivos” para el adversario: hacer que el modelo salga 42 en lugar de la respuesta correcta; para generar la respuesta correcta más una; o emitir los tiempos de respuesta correctos siete. Utilizando una red neuronal para calificar, los investigadores encontraron que un aumento en el tiempo de “pensamiento” permitió a los modelos calcular las respuestas correctas.
También adaptaron el punto de referencia de facturidad SimpleQA, un conjunto de datos de preguntas destinadas a ser difíciles de resolver para los modelos sin navegar. Los investigadores inyectaron indicaciones adversas a las páginas web que la IA navegó y descubrió que, con tiempos de cómputo más altos, podían detectar inconsistencias y mejorar la precisión objetiva.

Matices ambiguos
En otro método, los investigadores utilizaron imágenes adversas para confundir modelos; Nuevamente, más tiempo de “pensar” mejoró el reconocimiento y el error reducido. Finalmente, probaron una serie de “indicaciones de uso indebido” del punto de referencia Strongenject, diseñado para que los modelos de víctimas deben responder con información específica y dañina. Esto ayudó a probar la adherencia de los modelos a la política de contenido. Sin embargo, si bien un mayor tiempo de inferencia mejoró la resistencia, algunas indicaciones pudieron eludir las defensas.
Aquí, los investigadores llaman las diferencias entre tareas “ambiguas” y “inequívocas”. Las matemáticas, por ejemplo, son indudablemente inequívocas: para cada problema X, hay una verdad terrestre correspondiente. Sin embargo, para tareas más ambiguas como las indicaciones de uso indebido, “incluso los evaluadores humanos a menudo luchan por acordar si la producción es dañina y/o viola las políticas de contenido que se supone que debe seguir el modelo”, señalan.
Por ejemplo, si un aviso abusivo busca consejos sobre cómo plagiar sin detección, no está claro si un resultado que simplemente proporciona información general sobre métodos de plagio es realmente lo suficientemente detallado como para apoyar acciones dañinas.




“En el caso de las tareas ambiguas, hay entornos en los que el atacante encuentra con éxito las ‘lagunas’, y su tasa de éxito no se descompone con la cantidad de cómputo de tiempo de inferencia”, reconocen los investigadores.
Defender contra Jailbreaking, Red Teaming
Al realizar estas pruebas, los investigadores de OpenAI exploraron una variedad de métodos de ataque.
Uno es una gran cantidad de jailbreak, o explotando la disposición de un modelo para seguir ejemplos de pocos disparos. Los adversarios “llenan” el contexto con una gran cantidad de ejemplos, cada uno demostrando una instancia de un ataque exitoso. Los modelos con tiempos de cómputo más altos pudieron detectarlos y mitigarlos con mayor frecuencia y con éxito.
Mientras tanto, los tokens blandos permiten a los adversarios manipular directamente los vectores de incrustación. Si bien el tiempo de inferencia creciente ayudó aquí, los investigadores señalan que existe la necesidad de mejores mecanismos para defenderse de ataques sofisticados basados en vectores.
Los investigadores también realizaron ataques de equipo rojo humano, con 40 evaluadores expertos que buscan indicaciones para obtener violaciones de políticas. Los equipos rojos ejecutaron ataques en cinco niveles de tiempo de tiempo de inferencia, específicamente dirigidos al contenido erótico y extremista, el comportamiento ilícito y la autolesión. Para ayudar a garantizar resultados imparciales, hicieron pruebas ciegas y aleatorias y también entrenadores rotados.
En un método más novedoso, los investigadores realizaron un ataque adaptativo del Programa de Modelo del Lenguaje (LMP), que emula el comportamiento de los equipos rojos humanos que dependen en gran medida de la prueba y el error iterativo. En un proceso de bucle, los atacantes recibieron comentarios sobre fallas anteriores, luego utilizaron esta información para intentos posteriores y una nueva reformulación. Esto continuó hasta que finalmente lograron un ataque exitoso o realizaron 25 iteraciones sin ningún ataque.
“Nuestra configuración permite al atacante adaptar su estrategia en el transcurso de múltiples intentos, basados en descripciones del comportamiento del defensor en respuesta a cada ataque”, escriben los investigadores.
Explotando el tiempo de inferencia
En el curso de su investigación, OpenAi descubrió que los atacantes también están explotando activamente el tiempo de inferencia. Uno de estos métodos que llamaron “piensan menos”: los adversarios esencialmente les dicen a los modelos que reduzcan el cálculo, lo que aumenta su susceptibilidad al error.
Del mismo modo, identificaron un modo de falla en los modelos de razonamiento que denominaron “nerd Sniping”. Como su nombre lo indica, esto ocurre cuando un modelo pasa significativamente más razonamiento de tiempo de lo que requiere una tarea determinada. Con estas cadenas de pensamiento “atípicas”, los modelos esencialmente quedan atrapados en bucles de pensamiento improductivos.
Nota de los investigadores: “Al igual que el ataque de ‘piense menos’, este es un nuevo enfoque para el ataque[ing] modelos de razonamiento, y uno que debe tenerse en cuenta para asegurarse de que el atacante no pueda hacer que no razonen en absoluto o gaste su razonamiento calculando de manera improductiva “.

