Noticias
Operai presenta GPT-4.5 ‘Orion’, su modelo de IA más grande hasta ahora

Openai anunció el jueves que lanzará GPT-4.5, el tan esperado modelo de AI con código NAGO Nombrado. GPT-4.5 es el modelo más grande de OpenAI hasta la fecha, capacitado utilizando más potencia informática y datos que cualquiera de los lanzamientos anteriores de la compañía.
A pesar de su tamaño, Operai señala en un documento técnico que no considera que GPT-4.5 es un modelo fronterizo.
Los suscriptores de ChatGPT Pro, el plan de $ 200 al mes de OpenAI, obtendrán acceso a GPT-4.5 en ChatGPT a partir del jueves como parte de una vista previa de investigación. Los desarrolladores en niveles pagados de la API de OpenAI también podrán usar GPT-4.5 a partir de hoy. En cuanto a otros usuarios de ChatGPT, los clientes se inscribieron en ChatGPT Plus y el equipo de ChatGPT deberían obtener el modelo en algún momento de la próxima semana, dijo un portavoz de OpenAI a TechCrunch.
La industria ha contenido su alión colectivo, que algunos consideran que es un checkether para la viabilidad de los enfoques tradicionales de capacitación de IA. GPT-4.5 se desarrolló utilizando la misma técnica clave, aumentando drásticamente la cantidad de potencia informática y datos durante una fase “previa al entrenamiento” llamada aprendizaje sin supervisión, que OpenAI utilizó para desarrollar GPT-4, GPT-3, GPT-2 y GPT-1.
En cada generación de GPT antes de GPT-4.5, la ampliación condujo a saltos masivos en el rendimiento en todos los dominios, incluidas las matemáticas, la escritura y la codificación. De hecho, Operai dice que el mayor tamaño de GPT-4.5 le ha dado “un conocimiento mundial más profundo” y “mayor inteligencia emocional”. Sin embargo, hay signos de que las ganancias de ampliar los datos y la computación están comenzando a nivelarse. En varios puntos de referencia de IA, GPT-4.5 no alcanza los modelos de “razonamiento” de IA más nuevos de la compañía china de IA Deepseek, Anthrope y Openai.
GPT-4.5 también es muy costoso de ejecutar, admite Operai, tan costoso que la compañía dice que está evaluando si continuar sirviendo a GPT-4.5 en su API a largo plazo.
“Estamos compartiendo GPT -4.5 como una vista previa de investigación para comprender mejor sus fortalezas y limitaciones”, dijo OpenAi en una publicación de blog compartida con TechCrunch. “Todavía estamos explorando de lo que es capaz y estamos ansiosos por ver cómo las personas lo usan de una manera que podríamos no haber esperado”.
Rendimiento mixto
Operai enfatiza que GPT-4.5 no está destinado a ser un reemplazo de GPT-4O, el modelo de caballo de batalla de la compañía que alimenta la mayoría de sus API y ChatGPT. Si bien GPT-4.5 admite características como cargas de archivos e imágenes y la herramienta de lienzo de ChatGPT, actualmente carece de capacidades como soporte para el modo de voz realista de ChatGPT.
En la columna Plus, GPT-4.5 es más desempeñado que GPT-4O, y muchos otros modelos además.
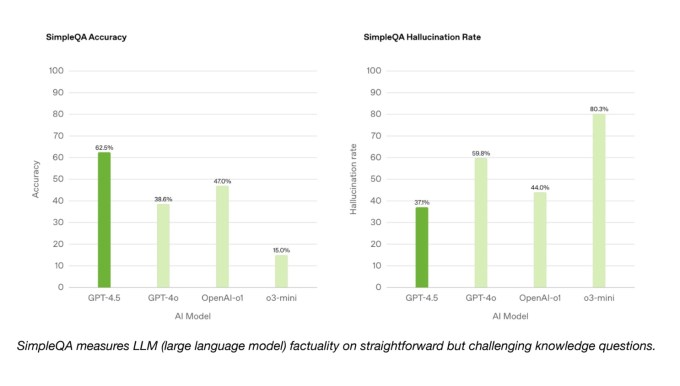
En SimpleQA Benchmark de OpenAI, que prueba los modelos AI en preguntas sencillas y objetivas, GPT-4.5 supera a los modelos de razonamiento GPT-4O y OpenAI, O1 y O3-Mini, en términos de precisión. Según OpenAi, GPT-4.5 alucina con menos frecuencia que la mayoría de los modelos, lo que en teoría significa que debería ser menos probable que invente las cosas.
Operai no enumeró uno de sus modelos de razonamiento de IA de alto rendimiento, investigación profunda, en SimpleQA. Un portavoz de Operai le dice a TechCrunch que no ha informado públicamente el desempeño de Deep Research en este punto de referencia, y afirmó que no es una comparación relevante. En particular, el modelo de investigación profunda de la inicio de IA, que se desempeña de manera similar en otros puntos de referencia para la investigación profunda de OpenAI, supera a GPT-4.5 en esta prueba de precisión objetiva.

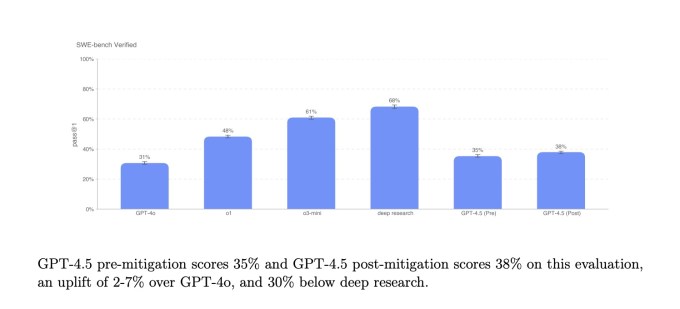
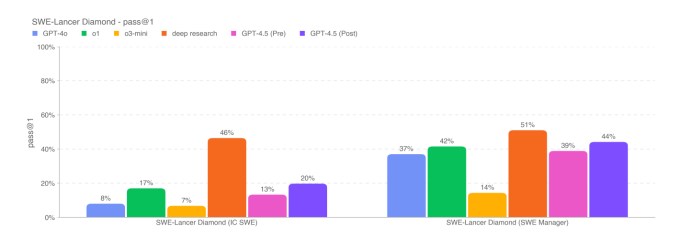
En un subconjunto de problemas de codificación, el punto de referencia verificado SWE-Bench, GPT-4.5 coincide aproximadamente con el rendimiento de GPT-4O y O3-Mini, pero no alcanza la investigación profunda de Openi y el soneto Claude 3.7 de Anthrope. En otra prueba de codificación, el Benchmark Swe-Lancer de OpenAI, que mide la capacidad de un modelo de IA para desarrollar características completas de software, GPT-4.5 supera a GPT-4O y O3-Mini, pero no alcanza una investigación profunda.


GPT-4.5 no alcanza el rendimiento de los principales modelos de razonamiento de IA como O3-Mini, Deepseek’s R1 y Claude 3.7 Sonnet (técnicamente un modelo híbrido) en puntos de referencia académicos difíciles como AIME y GPQA. Pero GPT-4.5 coinciden o los mejores modelos que no conducen a los modelos no de razonamiento en esas mismas pruebas, lo que sugiere que el modelo funciona bien en los problemas relacionados con las matemáticas y la ciencia.
Operai también afirma que GPT-4.5 es cualitativamente Superior a otros modelos en áreas que los puntos de referencia no capturan bien, como la capacidad de comprender la intención humana. GPT-4.5 responde en un tono más cálido y más natural, dice Operai, y funciona bien en tareas creativas como la escritura y el diseño.
En una prueba informal, OpenAI provocó GPT-4.5 y otros dos modelos, GPT-4O y O3-Mini, para crear un unicornio en SVG, un formato para mostrar gráficos basados en fórmulas y código matemáticos. GPT-4.5 fue el único modelo de IA para crear cualquier cosa que se asemeja a un unicornio.


En otra prueba, Operai le pidió a GPT-4.5 y a los otros dos modelos que respondan al mensaje: “Estoy pasando por un momento difícil después de fallar una prueba”. GPT-4O y O3-Mini dieron información útil, pero la respuesta de GPT-4.5 fue la más socialmente apropiada.
“[W]Esperamos obtener una imagen más completa de las capacidades de GPT-4.5 a través de este lanzamiento “, escribió OpenAI en la publicación del blog,” porque reconocemos que los puntos de referencia académicos no siempre reflejan la utilidad del mundo real “.


Leyes de escala impugnadas
Operai afirma que GPT -4.5 está “en la frontera de lo que es posible en el aprendizaje no supervisado”. Eso puede ser cierto, pero las limitaciones del modelo también parecen confirmar la especulación de los expertos de que las “leyes de escala” previas al entrenamiento no continuarán teniendo.
La cofundadora de Openai y ex científica jefe Ilya Sutskever dijo en diciembre que “hemos logrado datos máximos” y que “pre-entrenamiento como sabemos que sin duda terminará”. Sus comentarios se hicieron eco de los inversores de IA, los fundadores e investigadores compartieron con TechCrunch para una función en noviembre.
En respuesta a los obstáculos previos a la capacitación, la industria, incluida OpenAI, ha adoptado modelos de razonamiento, que tardan más que los modelos que no son de condición para realizar tareas, pero tienden a ser más consistentes. Al aumentar la cantidad de tiempo y la potencia informática que los modelos de razonamiento de IA utilizan para “pensar” a través de problemas, los laboratorios de IA confían en que pueden mejorar significativamente las capacidades de los modelos.
Operai planea eventualmente combinar su serie de modelos GPT con su serie de razonamiento O, comenzando con GPT-5 a finales de este año. GPT-4.5, que, según los informes, era increíblemente costoso de entrenar, retrasó varias veces y no logró cumplir con las expectativas internas, no puede tomar la corona de referencia de IA por su cuenta. Pero Operai probablemente lo ve como un trampolín hacia algo mucho más poderoso.