Noticias
Prueba de manejo del modelo Gemini-Exp-1206 de Google en análisis de datos y visualizaciones
Únase a nuestros boletines diarios y semanales para obtener las últimas actualizaciones y contenido exclusivo sobre la cobertura de IA líder en la industria. Más información
Uno de los últimos modelos experimentales de Google, Gemini-Exp-1206, muestra el potencial de aliviar uno de los aspectos más agotadores del trabajo de cualquier analista: lograr que sus datos y visualizaciones se sincronicen perfectamente y proporcionen una narrativa convincente, sin tener que trabajar toda la noche. .
Los analistas de inversiones, los banqueros junior y los miembros de equipos de consultoría que aspiran a puestos de socios asumen sus roles sabiendo que largas horas de trabajo, fines de semana y pasar toda la noche ocasionalmente podrían darles una ventaja interna en un ascenso.
Lo que consume gran parte de su tiempo es realizar análisis de datos avanzados y al mismo tiempo crear visualizaciones que refuercen una historia convincente. Lo que hace que esto sea más desafiante es que cada firma bancaria, fintech y consultora, como JP Morgan, McKinsey y PwC, tiene formatos y convenciones únicos para el análisis y visualización de datos.
VentureBeat entrevistó a miembros de equipos de proyectos internos cuyos empleadores habían contratado a estas empresas y las habían asignado al proyecto. Los empleados que trabajan en equipos dirigidos por consultores dijeron que producir imágenes que condensen y consoliden la enorme cantidad de datos es un desafío persistente. Uno dijo que era común que los equipos de consultores trabajaran durante la noche y hicieran un mínimo de tres o cuatro iteraciones de las visualizaciones de una presentación antes de decidirse por una y prepararla para las actualizaciones a nivel de tablero.
Un caso de uso convincente para probar el último modelo de Google
El proceso en el que confían los analistas para crear presentaciones que respalden una historia con visualizaciones y gráficos sólidos tiene tantos pasos manuales y repeticiones que resultó ser un caso de uso convincente para probar el último modelo de Google.
Al lanzar el modelo a principios de diciembre, Patrick Kane de Google escribió: “Ya sea que esté enfrentando desafíos complejos de codificación, resolviendo problemas matemáticos para proyectos escolares o personales, o brindando instrucciones detalladas de varios pasos para elaborar un plan de negocios personalizado, Gemini-Exp-1206 le ayudará a navegar tareas complejas con mayor facilidad”. Google notó el rendimiento mejorado del modelo en tareas más complejas, incluido el razonamiento matemático, la codificación y el seguimiento de una serie de instrucciones.
VentureBeat llevó el modelo Exp-1206 de Google a una prueba exhaustiva esta semana. Creamos y probamos más de 50 scripts de Python en un intento de automatizar e integrar análisis y visualizaciones intuitivas y fáciles de entender que pudieran simplificar los datos complejos que se analizan. Dado que los hiperescaladores dominan los ciclos de noticias actuales, nuestro objetivo específico era crear un análisis de un mercado tecnológico determinado y al mismo tiempo crear tablas de apoyo y gráficos avanzados.
A través de más de 50 iteraciones diferentes de scripts de Python verificados, nuestros hallazgos incluyeron:
- Cuanto mayor es la complejidad de una solicitud de código Python, más “piensa” el modelo e intenta anticipar el resultado deseado. Exp-1206 intenta anticipar lo que se necesita a partir de un mensaje complejo determinado y variará lo que produce incluso con el más mínimo cambio de matiz en un mensaje. Vimos esto en cómo el modelo alternaría entre formatos de tipos de tablas colocadas directamente encima del gráfico de araña del análisis de mercado de hiperescalador que creamos para la prueba.
- Obligar al modelo a intentar realizar análisis y visualización de datos complejos y producir un archivo Excel genera una hoja de cálculo con varias pestañas. Sin que nunca le pidieran una hoja de cálculo de Excel con varias pestañas, Exp-1206 creó una. El análisis tabular principal solicitado estaba en una pestaña, las visualizaciones en otra y una tabla auxiliar en la tercera.
- Decirle al modelo que repita los datos y recomiende las 10 visualizaciones que decida que mejor se ajustan a los datos ofrece resultados beneficiosos y reveladores. Con el objetivo de reducir el tiempo que supone tener que crear tres o cuatro iteraciones de presentaciones de diapositivas antes de una revisión por parte de la junta, obligamos al modelo a producir múltiples iteraciones conceptuales de imágenes. Estos podrían limpiarse e integrarse fácilmente en una presentación, ahorrando muchas horas de trabajo manual creando diagramas en diapositivas.
Impulsando a Exp-1206 hacia tareas complejas y en capas
El objetivo de VentureBeat era ver hasta dónde se podía llevar el modelo en términos de complejidad y tareas en capas. Su desempeño en la creación, ejecución, edición y ajuste de 50 scripts de Python diferentes mostró cuán rápido el modelo intenta captar matices en el código y reaccionar de inmediato. El modelo se flexiona y se adapta según el historial de indicaciones.
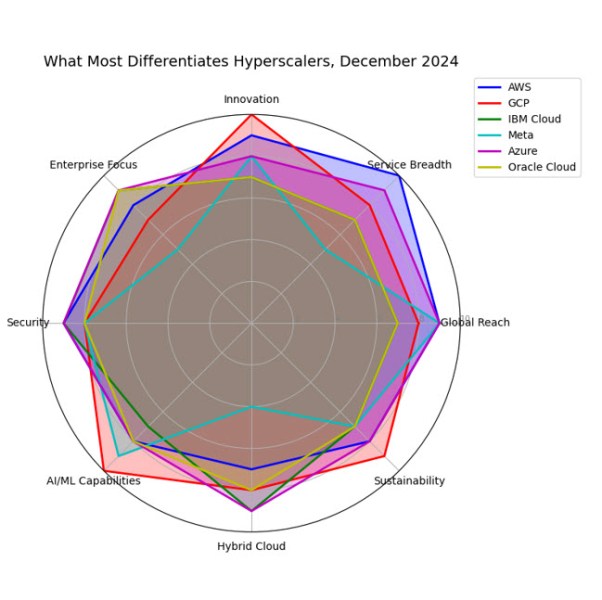
El resultado de ejecutar el código Python creado con Exp-1206 en Google Colab mostró que la granularidad matizada se extendía al sombreado y la translucidez de las capas en un gráfico de araña de ocho puntos que fue diseñado para mostrar cómo se comparan seis competidores hiperescaladores. Los ocho atributos que le pedimos a Exp-1206 que identificara en todos los hiperescaladores y que anclara el gráfico de araña se mantuvieron consistentes, mientras que las representaciones gráficas variaron.
Batalla de los hiperescaladores
Elegimos los siguientes hiperescaladores para comparar en nuestra prueba: Alibaba Cloud, Amazon Web Services (AWS), Digital Realty, Equinix, Google Cloud Platform (GCP), Huawei, IBM Cloud, Meta Platforms (Facebook), Microsoft Azure, NTT Global Data. Centros, Oracle Cloud y Tencent Cloud.
A continuación, escribimos un mensaje de 11 pasos de más de 450 palabras. El objetivo era ver qué tan bien Exp-1206 puede manejar la lógica secuencial y no perder su lugar en un proceso complejo de varios pasos. (Puede leer el mensaje en el apéndice al final de este artículo).
Luego enviamos el mensaje en Google AI Studio, seleccionando el modelo Gemini Experimental 1206, como se muestra en la siguiente figura.


A continuación, copiamos el código en Google Colab y lo guardamos en un cuaderno Jupyter (Comparación de Hyperscaler – Gemini Experimental 1206.ipynb), luego ejecutamos el script de Python. El script se ejecutó sin problemas y creó tres archivos (indicados con las flechas rojas en la parte superior izquierda).

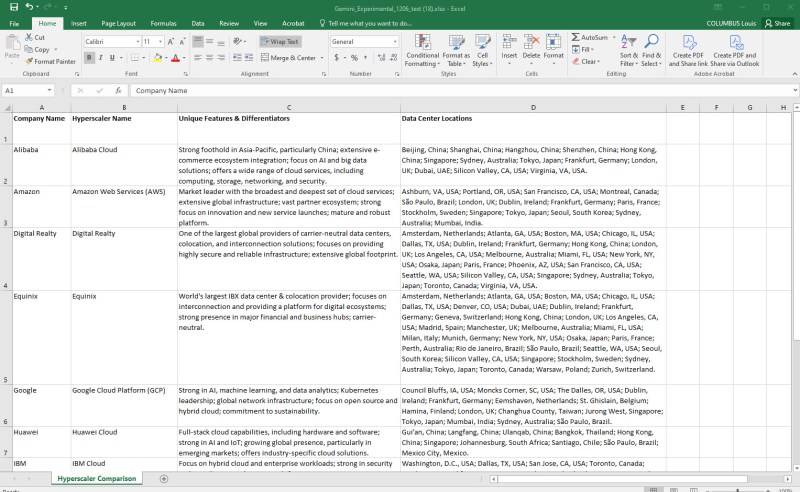
Análisis comparativo de Hyperscaler y un gráfico, en menos de un minuto
La primera serie de instrucciones en el mensaje pedía a Exp-1206 que creara un script de Python que comparara 12 hiperescaladores diferentes por su nombre de producto, características y diferenciadores únicos y ubicaciones de centros de datos. A continuación se muestra cómo resultó el archivo de Excel que se solicitó en el script. Me llevó menos de un minuto formatear la hoja de cálculo para reducirla y ajustarla a las columnas.

La siguiente serie de comandos solicitó una tabla de los seis principales hiperescaladores comparados en la parte superior de una página y el gráfico de araña a continuación. Exp-1206 eligió por sí solo representar los datos en formato HTML, creando la siguiente página.

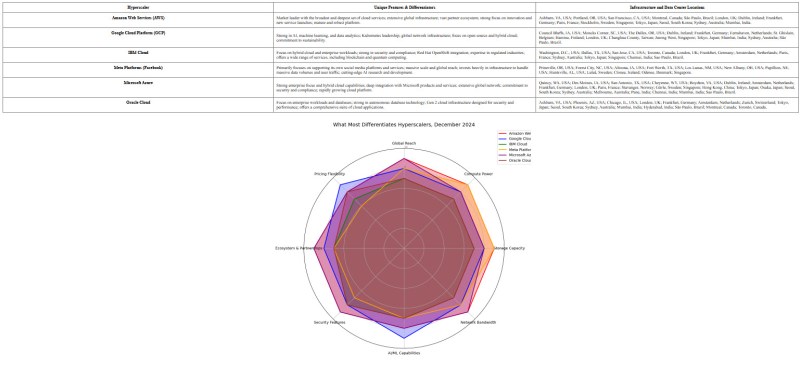
La secuencia final de comandos se centró en la creación de un gráfico de araña para comparar los seis hiperescaladores principales. Le asignamos a Exp-1206 la tarea de seleccionar los ocho criterios para la comparación y completar el gráfico. Esa serie de comandos se tradujo a Python y el modelo creó el archivo y lo proporcionó en la sesión de Google Colab.

Un modelo diseñado específicamente para ahorrar tiempo a los analistas
VentureBeat ha aprendido que en su trabajo diario, los analistas continúan creando, compartiendo y ajustando bibliotecas de indicaciones para modelos de IA específicos con el objetivo de optimizar los informes, el análisis y la visualización en todos sus equipos.
Los equipos asignados a proyectos de consultoría a gran escala deben considerar cómo modelos como Gemini-Exp-1206 pueden mejorar enormemente la productividad y aliviar la necesidad de semanas laborales de más de 60 horas y noches ocasionales en vela. Una serie de indicaciones automatizadas pueden realizar el trabajo exploratorio de observar las relaciones en los datos, lo que permite a los analistas producir imágenes con mucha mayor certeza sin tener que dedicar una cantidad excesiva de tiempo a llegar allí.
Apéndice:
Prueba rápida de Google Gemini Experimental 1206
Escriba un script de Python para analizar los siguientes hiperescaladores que han anunciado una presencia de centro de datos e infraestructura global para sus plataformas y cree una tabla comparándolos que capture las diferencias significativas en cada enfoque en presencia de centro de datos e infraestructura global.
Haga que la primera columna de la tabla sea el nombre de la empresa, la segunda columna sean los nombres de cada uno de los hiperescaladores de la empresa que tienen presencia de centro de datos e infraestructura global, la tercera columna sea lo que hace que sus hiperescaladores sean únicos y una inmersión profunda en los más diferenciados. características, y la cuarta columna son las ubicaciones de los centros de datos para cada hiperescalador a nivel de ciudad, estado y país. Incluya los 12 hiperescaladores en el archivo de Excel. No hagas web scraping. Genere un archivo de Excel del resultado y formatee el texto en el archivo de Excel para que no contenga corchetes ({}), comillas (‘), asteriscos dobles (**) ni ningún código HTML para mejorar la legibilidad. Nombra el archivo de Excel, Gemini_Experimental_1206_test.xlsx.
A continuación, cree una tabla de tres columnas de ancho y siete columnas de profundidad. La primera columna se titula Hiperescalador, la segunda Características únicas y diferenciadores y la tercera, Infraestructura y ubicaciones de centros de datos. Pon en negrita los títulos de las columnas y céntralos. Los títulos de los hiperescaladores también están en negrita. Verifique dos veces para asegurarse de que el texto dentro de cada celda de esta tabla se ajuste y no pase a la siguiente celda. Ajuste la altura de cada fila para asegurarse de que todo el texto quepa en la celda deseada. Esta tabla compara Amazon Web Services (AWS), Google Cloud Platform (GCP), IBM Cloud, Meta Platforms (Facebook), Microsoft Azure y Oracle Cloud. Centre la tabla en la parte superior de la página de resultados.
A continuación, tomemos Amazon Web Services (AWS), Google Cloud Platform (GCP), IBM Cloud, Meta Platforms (Facebook), Microsoft Azure y Oracle Cloud y defina los ocho aspectos más diferenciadores del grupo. Utilice esos ocho aspectos diferenciadores para crear un gráfico de araña que compare estos seis hiperescaladores. Cree un único gráfico de araña grande que muestre claramente las diferencias en estos seis hiperescaladores, utilizando diferentes colores para mejorar su legibilidad y la capacidad de ver los contornos o huellas de diferentes hiperescaladores. Asegúrese de titular el análisis, Lo que más diferencia a los hiperescaladores, diciembre de 2024. Asegúrese de que la leyenda sea completamente visible y no esté encima del gráfico.
Agregue el gráfico de la araña en la parte inferior de la página. Centre el gráfico de araña debajo de la tabla en la página de salida.
Estos son los hiperescaladores que se incluirán en el script Python: Alibaba Cloud, Amazon Web Services (AWS), Digital Realty, Equinix, Google Cloud Platform (GCP), Huawei, IBM Cloud, Meta Platforms (Facebook), Microsoft Azure, NTT Global Data. Centros, Oracle Cloud, Tencent Cloud.

