Noticias
Qué saber de las alternativas a OpenAI o1 y o3


El o1 de OpenAI y el último modelo o3 han generado mucho entusiasmo en torno a la nueva ley de escala de tiempo de inferencia. Básicamente, la premisa es que al darle al modelo más tiempo para “pensar”, se puede mejorar su desempeño en tareas difíciles que requieren planificación y razonamiento. Y ambos modelos han logrado avances en puntos de referencia de razonamiento, matemáticas y codificación que eran muy difíciles para los modelos de lenguajes grandes (LLM).
Cuando se les da una indicación, o1 y o3 usan más ciclos de cómputo para generar tokens adicionales, generar múltiples respuestas, revisar sus respuestas, hacer correcciones y evaluar diferentes soluciones para llegar a la respuesta final. Ha demostrado ser especialmente útil para tareas como codificación, matemáticas y análisis de datos.
Sin embargo, como se ha convertido en la norma con OpenAI, tanto o1 como o3 son muy reservados. No revelan su cadena de razonamiento, lo que dificulta que los usuarios comprendan cómo funcionan. Pero esto no ha impedido que la comunidad de IA intente realizar ingeniería inversa y reproducir las capacidades de estos grandes modelos de razonamiento (LRM). Y hay algunos artículos y modelos que insinúan lo que sucede bajo el capó.
Qwen con preguntas (QwQ)
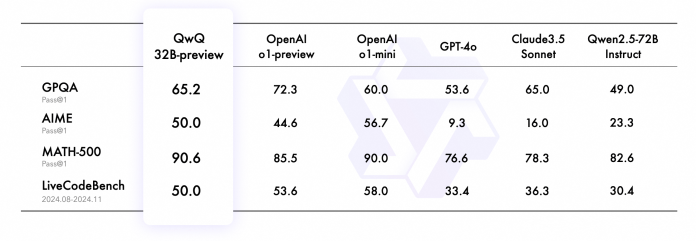
QwQ es un modelo abierto lanzado por Alibaba. Tiene 32 mil millones de parámetros y una ventana de contexto de 32.000 tokens. Según las pruebas publicadas por Alibaba, QwQ supera a o1-preview en los puntos de referencia AIME y MATH. También supera al o1-mini en el punto de referencia GPQA de razonamiento científico a prueba de Google.
Desafortunadamente, el equipo de Qwen no ha publicado detalles sobre el proceso y los datos utilizados para entrenar el modelo. Sin embargo, el modelo muestra completamente su cadena de razonamiento, lo que brinda a los usuarios una mejor visibilidad de cómo el modelo procesa las solicitudes y maneja las preguntas lógicas.
QwQ está disponible para descargar en Hugging Face y hay una demostración en línea en Hugging Face Spaces.

Marco o1
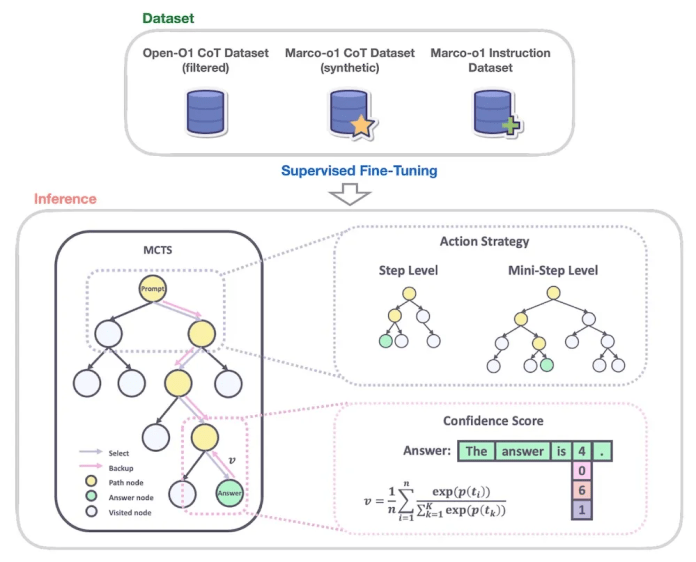
Alibaba ha lanzado otro modelo, Marco o1, otro modelo de razonamiento que utiliza escala de tiempo de inferencia para responder preguntas complejas. Marco-o1 es una versión de Qwen2-7B-Instruct que se ha perfeccionado en el conjunto de datos CoT Open-O1 y en conjuntos de datos personalizados de cadena de pensamiento (CoT) y seguimiento de instrucciones seleccionados por el equipo de Alibaba.
En el momento de la inferencia, Marco-o1 utiliza Monte-Carlo Tree Search (MTCS) para explorar múltiples rutas de razonamiento mientras genera tokens de respuesta. El modelo explora y evalúa los diferentes caminos en función de la puntuación de confianza de los tokens generados en cada rama del árbol. Esto permite que el modelo considere una gama más amplia de posibilidades y llegue a conclusiones más informadas y matizadas, especialmente en escenarios con soluciones abiertas.
Marco-o1 también utiliza un mecanismo de reflexión para revisar periódicamente sus respuestas y pasos de razonamiento para identificar posibles errores y corregir el rumbo.
Al igual que QwQ, Marco-o1 revela completamente su cadena de razonamiento. Marco-o1 es mejor que los LLM clásicos en el manejo de tareas de matemáticas y codificación. Pero es especialmente bueno para manejar problemas abiertos que no tienen una respuesta clara. Por ejemplo, en el artículo, los investigadores muestran cómo las capacidades de razonamiento del modelo le permiten mejorar su capacidad para traducir términos coloquiales del chino al inglés. Marco-o1 está disponible en Hugging Face.

Vista previa de DeepSeek R1-Lite
DeepSeek ha lanzado un modelo de razonamiento que rivaliza con o1. No es de código abierto y sólo está disponible a través de su interfaz web DeepSeek Chat.
El modelo muestra tanto sus pensamientos internos como un resumen final de su proceso de razonamiento antes de mostrar la respuesta, lo cual es una buena ventaja sobre o1 y o3.
Según DeepSeek, R1 supera a o1-preview en AIME y MATH. Hay poca información sobre cómo se entrenó el modelo o la técnica que utiliza para generar sus tokens de razonamiento. Sin embargo, la compañía ha insinuado que lanzará modelos de código abierto en el futuro.


Más investigaciones sobre el escalamiento del tiempo de inferencia
En agosto, DeepMind publicó un interesante estudio que exploraba la compensación entre la computación en el momento del entrenamiento y la del tiempo de prueba. El artículo respondió a la pregunta de que, dado un presupuesto de computación fijo, ¿obtendría un mejor rendimiento si lo gastara en entrenar un modelo más grande o lo usara en el momento de la inferencia para generar más tokens y revisar la respuesta del modelo (artículo completo aquí)? El estudio proporcionó pautas para asignar dinámicamente recursos informáticos y obtener los mejores resultados.

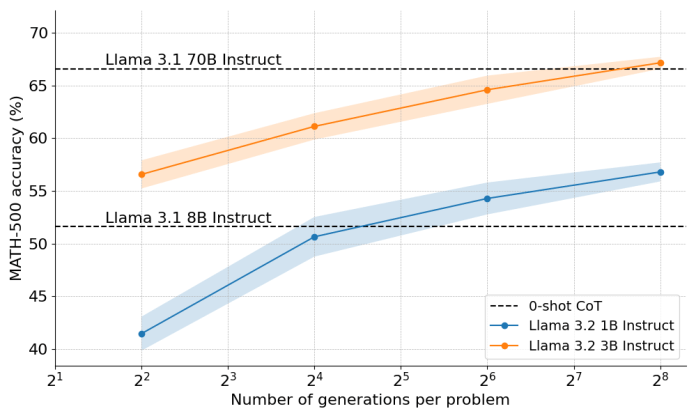
Los investigadores de Hugging Face utilizaron recientemente este estudio para impulsar los modelos de lenguaje pequeño (SLM) hasta el punto de que superaron a los modelos que eran un orden de magnitud más grandes. Por ejemplo, el modelo Llama-3.2 3B pudo superar a la versión 70B del modelo en el difícil punto de referencia MATH.
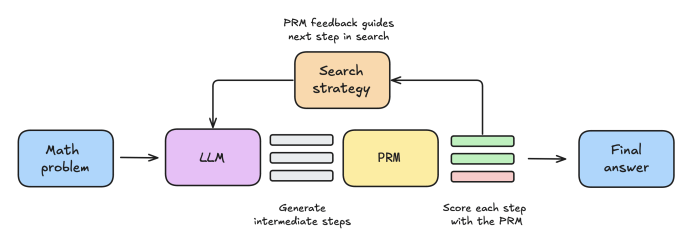
La clave de su éxito fue el uso inteligente de los recursos informáticos del tiempo de inferencia. El sistema utiliza un modelo de recompensa y un algoritmo de búsqueda para generar y revisar múltiples respuestas. Para cada consulta, el modelo produce varias respuestas parciales. Luego, un modelo de recompensa de proceso (PRM) revisa las respuestas y las califica según su calidad. Un algoritmo especial de búsqueda de árbol ayuda al modelo a diversificar las respuestas prometedoras y expandirlas en diferentes caminos. Este proceso se repite hasta que el modelo llega a su respuesta final. Esta técnica es sustancialmente más eficiente que el clásico mecanismo de “voto mayoritario”, en el que el modelo genera múltiples respuestas y elige la que aparece con más frecuencia.

¿O3 hace alguna diferencia?
El o3 de OpenAI aún está fresco y solo lo hemos visto a través de las demostraciones e informes publicados por OpenAI. Por lo que sabemos, logra avances impresionantes en algunos puntos de referencia clave, incluido el codiciado ARC Challenge, que algunos consideran un importante paso hacia la inteligencia artificial general (AGI).
o3 demuestra que la ley de escalamiento en el tiempo de prueba todavía tiene mucho potencial sin explotar. Sin embargo, no está claro si esto nos llevará hasta AGI. Por el momento, sabemos que la combinación de LLM, modelos de recompensa y algoritmos de búsqueda (y posiblemente otras estructuras simbólicas) puede ayudarnos a resolver problemas complejos cuyos resultados pueden cuantificarse claramente. Es por eso que modelos como o1 y o3 son muy buenos en matemáticas y codificación, pero inferiores a GPT-4o en tareas creativas.
Será interesante ver cómo podemos aprovechar estas nuevas habilidades para resolver nuevos problemas o revisar los antiguos.