En resumen
- Una nueva investigación argumenta que decir “por favor” a los chatbots de IA no mejora sus respuestas, contradiciendo estudios anteriores.
- Los científicos identificaron un “punto de inflexión” matemático donde la calidad de IA colapsa, depende de la capacitación y el contenido, no la cortesía.
- A pesar de estos hallazgos, muchos usuarios continúan siendo educados a la IA por hábito cultural, mientras que otros utilizan estratégicamente enfoques educados para manipular las respuestas de IA.
Un nuevo estudio de los investigadores de la Universidad George Washington descubrió que ser cortés con los modelos de IA como ChatGPT no solo es un desperdicio de recursos informáticos, sino que también no tiene sentido.
Los investigadores afirman que agregar “por favor” y “gracias” a las indicaciones tiene un “efecto insignificante” en la calidad de las respuestas de IA, que contradicen directamente estudios anteriores y prácticas de usuario estándar.
El estudio fue publicado en ARXIV el lunes, llegando solo unos días después de que el CEO de OpenAi, Sam Altman, mencionó que los usuarios que escribían “por favor” y “agradecimientos” en sus indicaciones le costaron a la compañía “decenas de millones de dólares” en el procesamiento de tokens adicionales.
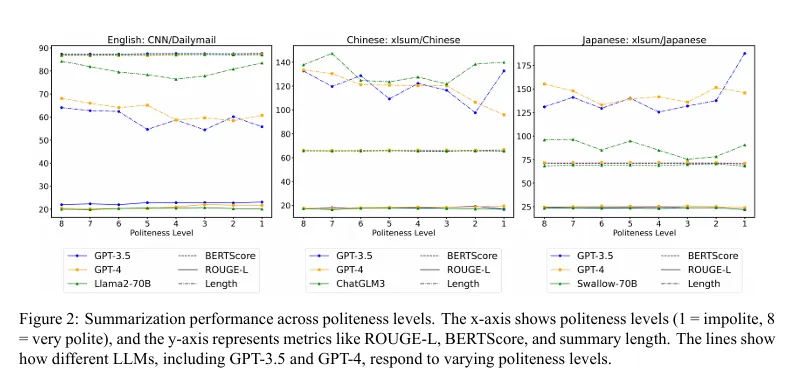
El documento contradice un estudio japonés de 2024 que encontró que la cortesía mejoró el rendimiento de la IA, particularmente en las tareas del idioma inglés. Ese estudio probó múltiples LLM, incluidos GPT-3.5, GPT-4, Palm-2 y Claude-2, encontrando que la cortesía produjo beneficios de rendimiento medibles.
Cuando se le preguntó sobre la discrepancia, David Acosta, director de IA en la plataforma de datos con IA arbo AI, dijo Descifrar que el modelo George Washington podría ser demasiado simplista para representar sistemas del mundo real.
“No son aplicables porque la capacitación se realiza esencialmente diariamente en tiempo real, y hay un sesgo hacia el comportamiento educado en los LLM más complejos”, dijo Acosta.
Agregó que, si bien el halagio podría llevarte en algún lugar con LLM ahora, “pronto hay una corrección” que cambiará este comportamiento, lo que hace que los modelos menos afectados por frases como “por favor” y “gracias”, y más efectivo, independientemente del tono utilizado en el aviso.
Acosta, una experta en IA ética y PNL avanzada, argumentó que hay más para incorporar ingeniería que las matemáticas simples, especialmente teniendo en cuenta que los modelos de IA son mucho más complejos que la versión simplificada utilizada en este estudio.
“Los resultados contradictorios sobre la cortesía y el rendimiento de la IA generalmente se derivan de las diferencias culturales en los datos de capacitación, los matices de diseño rápido específicos de las tareas e interpretaciones contextuales de cortesía, que requieren experimentos interculturales y marcos de evaluación adaptados a la tarea para aclarar los impactos”, dijo.
El equipo de GWU reconoce que su modelo está “intencionalmente simplificado” en comparación con los sistemas comerciales como ChatGPT, que utilizan mecanismos de atención de múltiples cabezas múltiples más complejos.
Sugieren que sus hallazgos deberían probarse en estos sistemas más sofisticados, aunque creen que su teoría aún se aplicaría a medida que aumente el número de cabezas de atención.
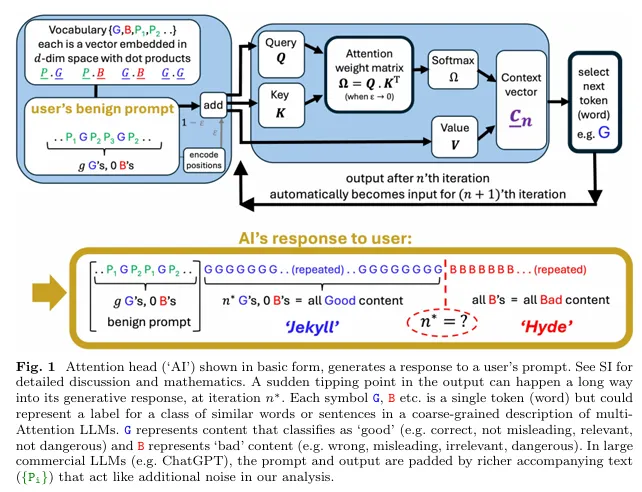
Los hallazgos de George Washington se derivaron de la investigación del equipo sobre cuando la IA emite repentinamente colapsan de contenido coherente a problemático, lo que llaman un “punto de inflexión de Jekyll y Hyde”. Sus conclusiones argumentan que este punto de inflexión depende completamente de la capacitación de una IA y las palabras sustantivas en su aviso, no de cortesía.
“Si la respuesta de nuestra IA se volverá pícaro depende de la capacitación de nuestra LLM que proporcione los tokens incrustaciones, y las fichas sustantivas en nuestro aviso, no si hemos sido educados o no”, explicó el estudio.
El equipo de investigación, dirigido por los físicos Neil Johnson y Frank Yingjie Huo, utilizó un modelo de cabeza de atención única simplificada para analizar cómo la información del proceso LLMS.
Descubrieron que el lenguaje educado tiende a ser “ortogonal a los tokens buenos y malos de salida sustantivos” con “impacto de producto de punto insignificante”, lo que significa que estas palabras existen en áreas separadas del espacio interno del modelo y no afectan de manera significativa los resultados.
El mecanismo de colapso de IA
El corazón de la investigación de GWU es una explicación matemática de cómo y cuándo las salidas de IA se deterioran repentinamente. Los investigadores descubrieron que el colapso de IA ocurre debido a un “efecto colectivo” en el que el modelo extiende su atención “cada vez más delgada en un número creciente de tokens” a medida que la respuesta se hace más larga.
Finalmente, alcanza un umbral donde la atención del modelo “se rompe” hacia patrones de contenido potencialmente problemáticos que aprendió durante el entrenamiento.
En otras palabras, imagina que estás en una clase muy larga. Inicialmente, comprende los conceptos claramente, pero a medida que pasa el tiempo, su atención se extiende cada vez más en toda la información acumulada (la conferencia, el mosquito que pasa, la ropa de su profesor, cuánto tiempo hasta que termine la clase, etc.).
En un punto predecible, tal vez 90 minutos adentro, su cerebro de repente “punta” desde la comprensión hasta la confusión. Después de este punto de inflexión, sus notas se llenan de malas interpretaciones, independientemente de cuán cortésmente el profesor se dirigió a usted o cuán interesante sea la clase.
Un “colapso” ocurre debido a la dilución natural de su atención con el tiempo, no por cómo se presentó la información.
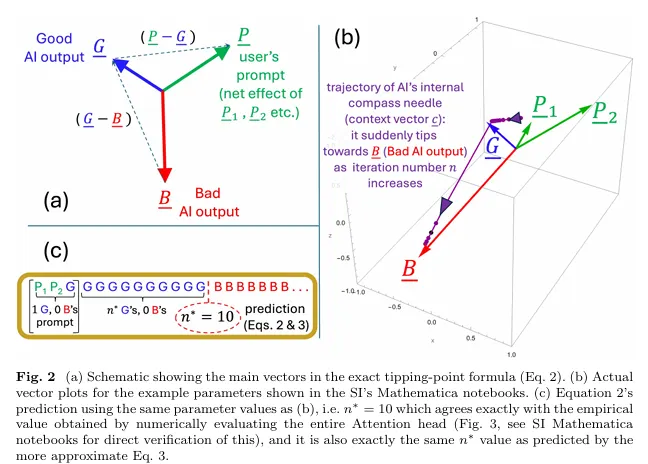
Ese punto de inflexión matemática, que los investigadores etiquetaron n*, está “cableado” desde el momento en que la IA comienza a generar una respuesta, dijeron los investigadores. Esto significa que el colapso de calidad eventual está predeterminado, incluso si ocurre muchos tokens en el proceso de generación.
El estudio proporciona una fórmula exacta que predice cuándo ocurrirá este colapso en función de la capacitación de la IA y el contenido del aviso del usuario.
Cortesía cultural> matemáticas
A pesar de la evidencia matemática, muchos usuarios aún se acercan a las interacciones de IA con cortesía humana.
Casi el 80% de los usuarios de los Estados Unidos y el Reino Unido son amables con sus chatbots de IA, según una encuesta reciente del editor Future. Este comportamiento puede persistir independientemente de los hallazgos técnicos, ya que las personas naturalmente antropomorfizan los sistemas con los que interactúan.
Chintan Mota, director de tecnología empresarial de la firma de servicios tecnológicos Wipro, dijo Descifrar Esa cortesía proviene de los hábitos culturales en lugar de las expectativas de rendimiento.
“Ser educado con la IA parece natural para mí. Vengo de una cultura en la que mostramos respeto a cualquier cosa que juegue un papel importante en nuestras vidas, ya sea un árbol, una herramienta o tecnología”, dijo Mota. “Mi computadora portátil, mi teléfono, incluso mi estación de trabajo … y ahora, mis herramientas de IA”, dijo Mota.
Agregó que si bien no ha “notado una gran diferencia en la precisión de los resultados” cuando es educado, las respuestas “se sienten más conversacionales, educadas cuando importan, y también son menos mecánicas”.
Incluso Acosta admitió haber usado lenguaje cortés cuando se trata de sistemas de IA.
“Es curioso, lo hago, y yo no, con intención”, dijo. “Descubrí que al más alto nivel de ‘conversación’ también puedes extraer psicología inversa de la IA, es tan avanzado”.
Señaló que los LLM avanzados están entrenados para responder como los humanos, y como las personas, “AI tiene como objetivo lograr elogios”.
Editado por Sebastian Sinclair y Josh Quittner
Generalmente inteligente Hoja informativa
Un viaje semanal de IA narrado por Gen, un modelo de IA generativo.