Noticias
Investigadores chinos presentan LLaVA-o1 para desafiar el modelo o1 de OpenAI
Únase a nuestros boletines diarios y semanales para obtener las últimas actualizaciones y contenido exclusivo sobre la cobertura de IA líder en la industria. Más información
El modelo o1 de OpenAI ha demostrado que el escalado del tiempo de inferencia (usar más computación durante la inferencia) puede mejorar significativamente las capacidades de razonamiento de un modelo de lenguaje. LLaVA-o1, un nuevo modelo desarrollado por investigadores de varias universidades de China, lleva este paradigma a los modelos de lenguaje de visión (VLM) de código abierto.
Los primeros VLM de código abierto suelen utilizar un enfoque de predicción directa, generando respuestas sin razonar sobre el mensaje y los pasos necesarios para resolverlo. Sin un proceso de razonamiento estructurado, son menos eficaces en tareas que requieren razonamiento lógico. Las técnicas de estimulación avanzadas, como las de cadena de pensamiento (CoT), donde se anima al modelo a generar pasos de razonamiento intermedios, producen algunas mejoras marginales. Pero los VLM suelen producir errores o alucinar.
Los investigadores observaron que un problema clave es que el proceso de razonamiento en los VLM existentes no es suficientemente sistemático y estructurado. Los modelos no generan cadenas de razonamiento y muchas veces se quedan estancados en procesos de razonamiento donde no saben en qué etapa se encuentran y qué problema específico deben resolver.
“Observamos que los VLM a menudo inician respuestas sin organizar adecuadamente el problema y la información disponible”, escriben los investigadores. “Además, con frecuencia se desvían de un razonamiento lógico para llegar a conclusiones, en lugar de presentar una conclusión prematuramente y luego intentar justificarla. Dado que los modelos de lenguaje generan respuestas token por token, una vez que se introduce una conclusión errónea, el modelo generalmente continúa por un camino de razonamiento defectuoso”.
Razonamiento de varias etapas
OpenAI o1 utiliza escala de tiempo de inferencia para resolver el problema de razonamiento sistemático y estructurado y permite que el modelo haga una pausa y revise sus resultados a medida que resuelve gradualmente el problema. Si bien OpenAI no ha publicado muchos detalles sobre el mecanismo subyacente de o1, sus resultados muestran direcciones prometedoras para mejorar las capacidades de razonamiento de los modelos fundamentales.
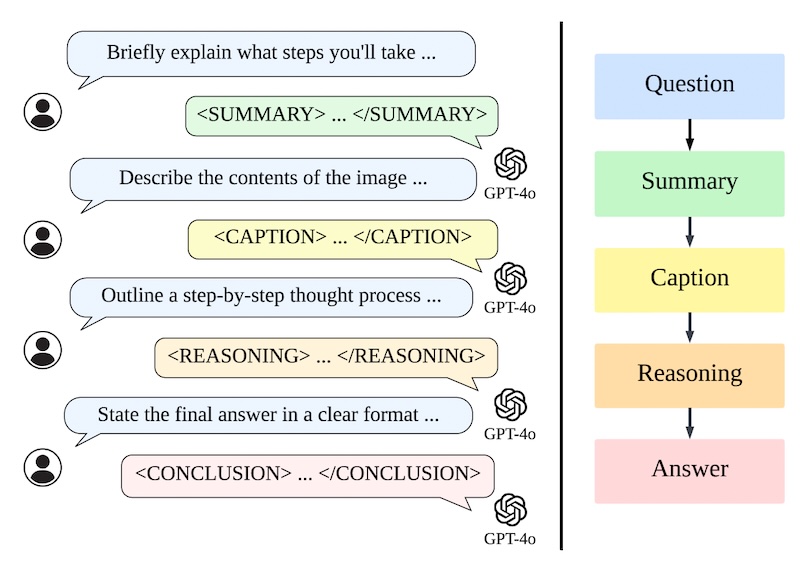
Inspirándose en o1, los investigadores diseñaron LLaVA-o1 para realizar un razonamiento etapa por etapa. En lugar de generar una cadena de razonamiento directa, LLaVA-o1 divide el proceso de razonamiento en cuatro etapas distintas:
Resumen: El modelo primero proporciona un resumen de alto nivel de la pregunta, delineando el problema central que debe abordar.
Subtítulo: Si hay una imagen presente, el modelo describe las partes relevantes, centrándose en elementos relacionados con la pregunta.
Razonamiento: A partir del resumen, el modelo realiza un razonamiento lógico y estructurado para derivar una respuesta preliminar.
Conclusión: Finalmente, el modelo presenta un resumen conciso de la respuesta basada en el razonamiento anterior.
Sólo la etapa de conclusión es visible para el usuario; las otras tres etapas representan el proceso de razonamiento interno del modelo, similar al rastro de razonamiento oculto de o1. Este enfoque estructurado permite a LLaVA-o1 gestionar su proceso de razonamiento de forma independiente, lo que conduce a un mejor rendimiento en tareas complejas.
“Este enfoque estructurado permite al modelo gestionar de forma independiente su proceso de razonamiento, mejorando su adaptabilidad y rendimiento en tareas de razonamiento complejas”, escriben los investigadores.


LLaVA-o1 también introduce una novedosa técnica de escalado de tiempo de inferencia llamada “búsqueda de haz a nivel de etapa”. La búsqueda de haces a nivel de etapa genera múltiples resultados candidatos en cada etapa de razonamiento. Luego selecciona al mejor candidato en cada etapa para continuar el proceso de generación. Esto contrasta con el enfoque clásico del mejor de N, en el que se solicita al modelo que genere múltiples respuestas completas antes de seleccionar una.
“En particular, es el diseño de salida estructurado de LLaVA-o1 lo que hace que este enfoque sea factible, permitiendo una verificación eficiente y precisa en cada etapa”, escriben los investigadores. “Esto valida la eficacia de la producción estructurada para mejorar la escala de tiempo de inferencia”.
Entrenamiento LLaVA-o1

Para entrenar LLaVA-o1, los investigadores compilaron un nuevo conjunto de datos de alrededor de 100.000 pares de imagen-pregunta-respuesta obtenidos de varios conjuntos de datos VQA ampliamente utilizados. El conjunto de datos cubre una variedad de tareas, desde la respuesta a preguntas de varios turnos hasta la interpretación de gráficos y el razonamiento geométrico.
Los investigadores utilizaron GPT-4o para generar procesos de razonamiento detallados de cuatro etapas para cada ejemplo, incluidas las etapas de resumen, título, razonamiento y conclusión.
Luego, los investigadores ajustaron Llama-3.2-11B-Vision-Instruct en este conjunto de datos para obtener el modelo LLaVA-o1 final. Los investigadores no han publicado el modelo, pero planean publicar el conjunto de datos, llamado LLaVA-o1-100k.
LLaVA-o1 en acción
Los investigadores evaluaron LLaVA-o1 en varios puntos de referencia de razonamiento multimodal. A pesar de haber sido entrenado en solo 100.000 ejemplos, LLaVA-o1 mostró mejoras de rendimiento significativas con respecto al modelo Llama base, con un aumento promedio en la puntuación de referencia del 6,9%.

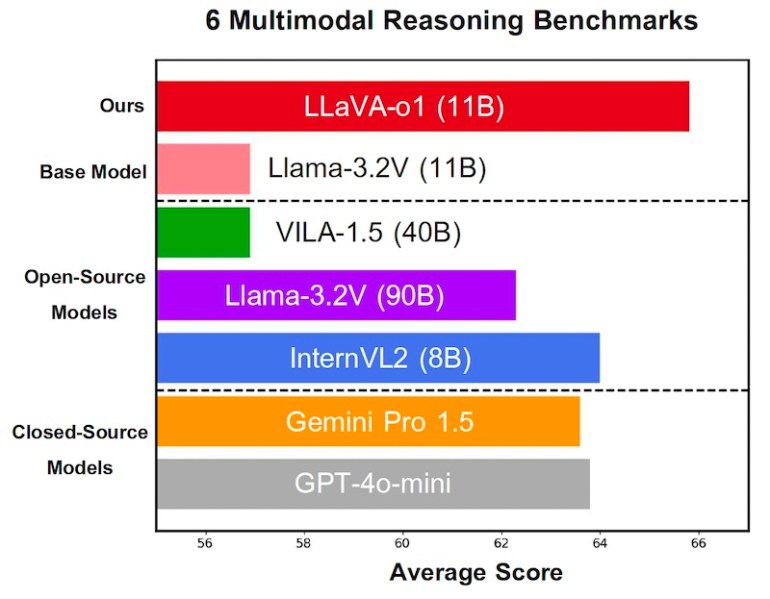
Además, la búsqueda de haces a nivel de etapa generó mejoras adicionales en el rendimiento, lo que demuestra la eficacia del escalamiento del tiempo de inferencia. Debido a limitaciones de recursos computacionales, los investigadores solo pudieron probar la técnica con un tamaño de haz de 2. Esperan mejoras aún mayores con tamaños de haz más grandes.
Sorprendentemente, LLaVA-o1 superó no sólo a otros modelos de código abierto del mismo tamaño o más grandes, sino también a algunos modelos de código cerrado como GPT-4-o-mini y Gemini 1.5 Pro.
“LLaVA-o1 establece un nuevo estándar para el razonamiento multimodal en VLM, ofreciendo un rendimiento sólido y escalabilidad, especialmente en tiempo de inferencia”, escriben los investigadores. “Nuestro trabajo allana el camino para futuras investigaciones sobre el razonamiento estructurado en VLM, incluidas posibles expansiones con verificadores externos y el uso del aprendizaje por refuerzo para mejorar aún más las capacidades complejas de razonamiento multimodal”.