


2024 fue un gran año para el mundo de la tecnología, especialmente para Google. Comenzó a comercializar la mayor parte de su catálogo de IA bajo la marca Gemini, que representa el chatbot conversacional y sus modelos de IA subyacentes.
El gigante de las búsquedas lanzó muchos productos, funciones y cambios nuevos en el espacio de la IA generativa. Recapitulemos las principales funciones y cambios de Google Gemini introducidos a lo largo del año. En su tiempo libre, consulte varios productos y servicios que Google descontinuará en 2024 y la lista de deseos de funciones de Instagram.
Nota: La lista no es exhaustiva y es posible que no incluya todas las funciones de Gemini lanzadas en 2024.
Cambiar el nombre del chatbot Bard a Gemini
Uno de los cambios más importantes que vimos a principios de este año fue que Google cambió el nombre de Bard a Gemini, sincronizando el esquema de nombres con sus modelos Gemini preexistentes. La compañía también etiquetó el modelo Gemini 1.0 Pro recién horneado y presentó Gemini en más de 40 idiomas y 230 países en todo el mundo.
Un ingeniero de Google reveló más tarde “Por qué Gemini se llama Gemini” y dijo que el modelo de IA tiene un doble significado detrás de su nombre. Su capacidad para manejar diferentes tipos de datos se alinea con la personalidad dual del signo zodiacal Géminis. El nombre también se inspira en el primer programa de disparos a la luna de la NASA llamado Proyecto Gemini.
Aplicaciones móviles, versión paga de Gemini, soporte para Chromebook Plus
Google también presentó la aplicación Gemini para Android en febrero, reemplazando finalmente al Asistente de Google como asistente de voz predeterminado para Android. En ese momento, los usuarios de iOS podían acceder al chatbot Gemini a través de la aplicación de Google.
En el mismo mes, el gigante de las búsquedas lanzó una suscripción paga para su chatbot de IA llamado Gemini Advanced, que brinda a los usuarios acceso a los modelos Gemini más capaces, como Gemini Ultra 1.0, 1.5 Pro y material experimental como Gemini-Exp-1206. .
Además, trajo varias funciones de Gemini, como “Ayúdame a escribir”, a las computadoras portátiles Chromebook Plus, a las que se puede acceder a través de un botón Gemini dedicado en el estante de aplicaciones de la pantalla de inicio.
Soporte para Google Maps
Las capacidades del chatbot Gemini AI se pueden mejorar con la ayuda de las extensiones Gemini. En marzo, Google actualizó Gemini con soporte para Google Maps, lo que permite a los usuarios emitir comandos para activar la navegación desde el chatbot.
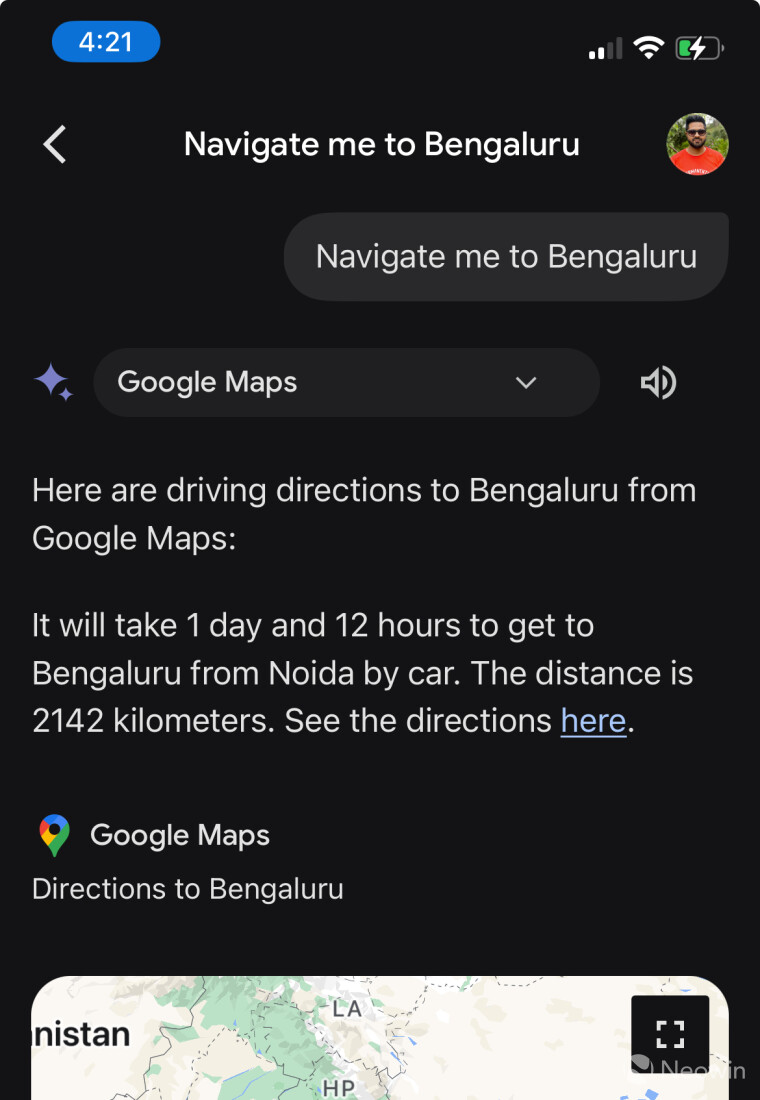
Por ejemplo, puede emitir comandos como “Llevarme a [X],” Gemini mostrará datos como la distancia, el tiempo estimado y un enlace a Google Maps. La navegación se iniciará automáticamente después de unos segundos.
Vídeos
Como sugiere el nombre, Vids es una nueva herramienta de creación de videos impulsada por Gemini que Google lanzó en abril de este año para crear fácilmente videos de capacitación, presentaciones, actualizaciones o contenido de marketing. Ofrece una interfaz de usuario con estilo de línea de tiempo para ensamblar recursos de video de Google Drive o de otro lugar, grabar voces en off o filmarse directamente desde la aplicación.
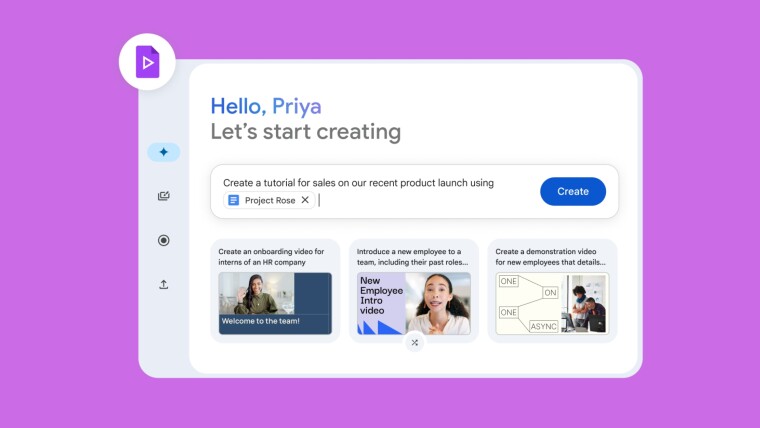
Puedes colaborar con otras personas y controlar quién puede editar, comentar o ver tus videos. Tenga en cuenta que Google Vids es parte de la suite Workspace y es una oferta paga.
Extensión de música de YouTube
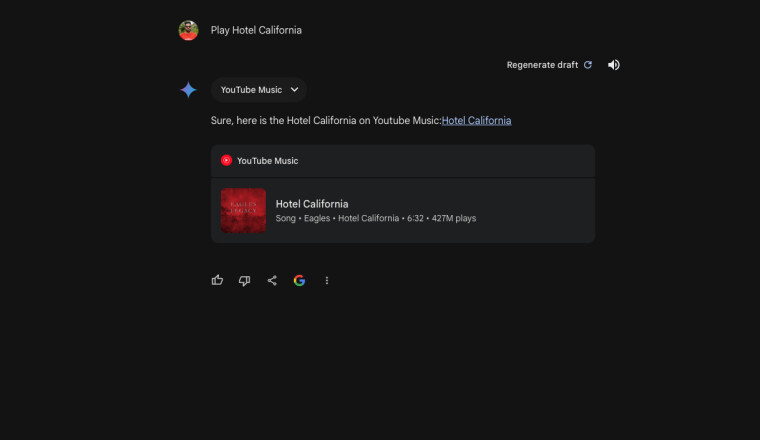
Otro complemento para el chatbot fue una nueva extensión de YouTube Music en mayo. Permite a los usuarios de Gemini conectar YouTube Music con el chatbot para buscar sus canciones favoritas, reproducir radio, descubrir nuevos artistas y listas de reproducción, y más.
Actualizaciones de la versión Gemini y nuevos modelos.
El año 2024 también vio varias actualizaciones de los modelos Gemini. Gemini 1.5 Flash se presentó en mayo como un LLM liviano, que se destacó “en resúmenes, aplicaciones de chat, subtítulos de imágenes y videos, extracción de datos de documentos y tablas extensos, y más”.
A esto le siguió una variante más pequeña de 1.5 Flash (conocida como Gemini 1.5 Flash-8B); un nuevo modelo Gemini 1.5 Pro con codificación mejorada y rendimiento de avisos complejos; y un nuevo modelo Gemini 1.5 Flash con importantes mejoras.
El mes pasado marcó el debut de Gemini 2.0. Google anunció el modelo experimental Gemini 2.0 Flash con soporte para imágenes generadas de forma nativa mezcladas con texto y audio multilingüe de texto a voz (TTS) orientable.
Preguntar al asistente de fotos
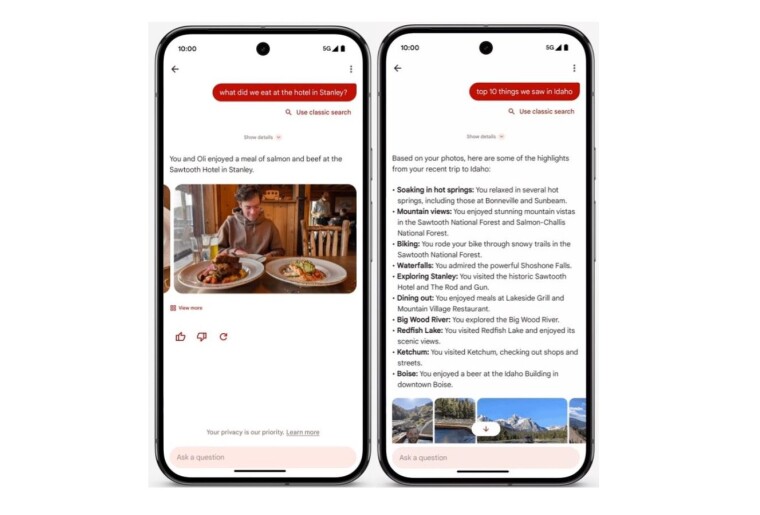
El protagonismo de Google I/O 2024 podría haber eclipsado al asistente Ask Photos para Google Photos anunciado en la conferencia. El asistente digital impulsado por los modelos Gemini AI se puede utilizar para extraer fotos/videos de su galería, generar subtítulos personalizados, explicar lo que sucede en ellos o crear momentos destacados del viaje después de unas vacaciones.
Expandiendo Gemini al sector educativo
En mayo, Google también amplió Gemini for Workspace al sector educativo al introducir dos nuevos complementos: Gemini Education y Gemini Education Premium. Este último permitió el acceso a funciones como la toma de notas y resúmenes basados en IA en Meet y la prevención de pérdida de datos mejorada por IA.
Paneles laterales Gemini para aplicaciones Workspace
La búsqueda de Google de colocar su chatbot de IA en todos los lugares posibles allanó el camino para los paneles laterales de Gemini para las aplicaciones Workspace. En junio, el gigante de las búsquedas lanzó paneles laterales Gemini para sus aplicaciones web, incluidas Google Docs, Slides, Drive y Gmail.
Los paneles laterales se personalizan según la aplicación. Por ejemplo, Gemini en Gmail puede resumir correos electrónicos, sugerir respuestas y resumir hilos de correo electrónico. Mientras tanto, puede generar nuevas diapositivas de presentación en Google Slides y crear imágenes personalizadas.
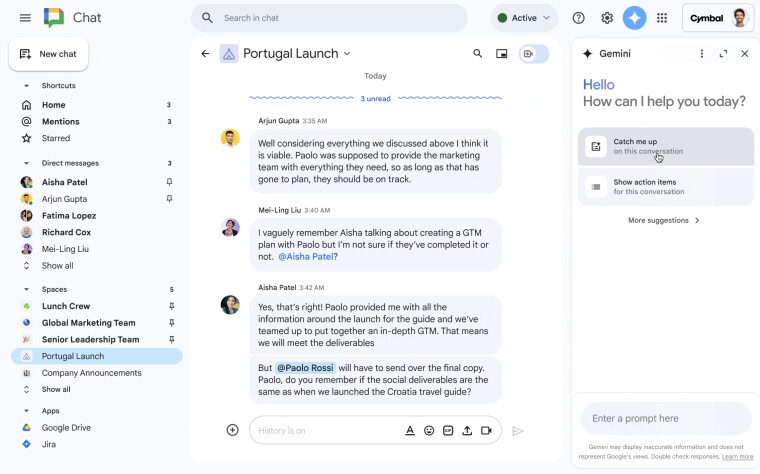
En noviembre, también se agregó el panel lateral Gemini a Google Chat. Al igual que otras aplicaciones, puede resumir conversaciones y evitar a los usuarios la molestia de leerlo todo.
Géminis en vivo
En agosto, se lanzó Gemini Live en el evento de hardware Pixel para brindar a los usuarios de teléfonos inteligentes una experiencia de conversación natural con el chatbot de IA. Puedes hablar con Gemini como en una conversación normal de ida y vuelta, abandonar la conversación en cualquier momento y continuarla más tarde.
También puedes continuar la conversación con Gemini mientras la aplicación está en segundo plano o tu teléfono está bloqueado. Gemini Live se incluyó inicialmente con Gemini Advanced, pero ahora está disponible a través de la aplicación Gemini en Android e iOS. Posteriormente, la función se amplió para agregar soporte para más de 40 idiomas.
Gemas personalizadas para Géminis
Custom Gems le permite crear versiones del chatbot Gemini adaptadas a casos de uso específicos. Por ejemplo, puede generar ideas para un próximo evento, recordar instrucciones detalladas o crear un asesor de aprendizaje.
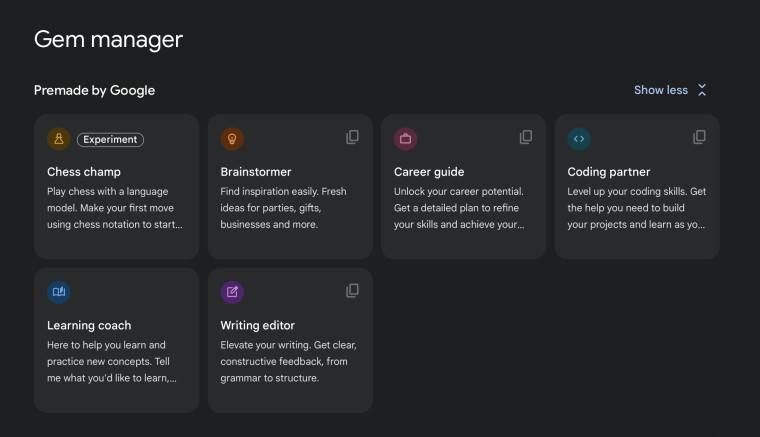
La función premium se implementó para usuarios de Gemini Advanced, Business y Enterprise en más de 150 países. Puedes ir al administrador de gemas para acceder a gemas prefabricadas o crear otras nuevas haciendo clic en el botón “+ Agregar gema” y escribiendo su propósito y objetivo.
Imagen 3 y generador de imágenes Whisk
El modelo de conversión de texto a imagen de mayor calidad de Google, Imagen 3, se lanzó en octubre tras su anuncio a principios de este año. El último modelo de generación de imágenes funciona con aplicaciones Gemini para usuarios en todos los idiomas admitidos.
Imagen 3 comprende mejor el lenguaje natural y la intención detrás del mensaje. Los usuarios pueden escribir indicaciones para generar paisajes fotorrealistas, pinturas al óleo texturizadas o escenas caprichosas de animación con plastilina, y emitir comandos posteriores para perfeccionarlo aún más.

A principios de este mes, Google utilizó Imagen 3 para impulsar una nueva herramienta de inteligencia artificial generativa llamada Whisk, que toma imágenes como entrada para generar nuevas imágenes.
Gemini en el navegador Opera, integración de Snapchat
Opera se unió a Google Cloud para aprovechar las capacidades de Gemini para su IA en el navegador conocida como Aria, que ya utiliza el poder de múltiples modelos de lenguaje grandes (LLM). La asociación trajo las capacidades de generación de imágenes y texto a voz de Google al navegador Opera.
Mientras tanto, Snapchat fue otra plataforma de terceros que obtuvo acceso a las funciones de Gemini en 2024. El gigante de las redes sociales se asoció con Google para hacer que el chatbot My AI sea más inteligente que antes y ofrecer una experiencia multimodal. El gigante de las búsquedas afirmó que la integración de Gemini con My AI mejoró la participación de los usuarios en los EE. UU. en 2,5 veces.
Investigación profunda
Si utiliza el chatbot de inteligencia artificial generativa de Google para sesiones de investigación extensas, un nuevo asistente con tecnología de inteligencia artificial llamado Deep Research puede ayudarlo con su exploración. Está diseñado para reducir las horas de investigación realizando análisis y resúmenes de documentos en profundidad y extrayendo conocimientos clave de grandes cantidades de información.
También presentamos una nueva función agente llamada Investigación profunda en Gemini Advanced, un asistente de investigación que puede profundizar en temas complejos y crear informes con enlaces a las fuentes relevantes. pic.twitter.com/imYd4tktEG
-Sundar Pichai (@sundarpichai) 11 de diciembre de 2024
Tenga en cuenta que Deep Research es parte de Gemini Advanced (una oferta paga) y está disponible en más de 45 idiomas en más de 150 países en todo el mundo.
Búsqueda en lenguaje natural en Google Maps
En una nueva actualización de su aplicación de navegación, Google agregó una función de búsqueda impulsada por Gemini a Google Maps. En otras palabras, puedes escribir consultas en lenguaje natural en la barra de búsqueda de Google Maps. Por ejemplo, puedes encontrar nuevos lugares escribiendo “cosas que hacer con amigos por la noche”. El chatbot crea reseñas resumidas sobre los lugares que lees para tener una idea sobre ellos.
Reproducir canciones de Spotify
No solo YouTube Music, Gemini también agregó soporte para la aplicación rival de transmisión de música Spotify. El chatbot de IA puede reproducir música de Spotify en su dispositivo Android sin necesidad de cambiar de aplicación.
Puede utilizar la interfaz de chat de Gemini para solicitar canciones, listas de reproducción del navegador y buscar música a través de letras, entre varias funciones. Sin embargo, necesita una cuenta Spotify Premium para que la integración funcione.
Controversias de Géminis
No se trata solo de nuevas características, el chatbot generativo de IA de Google también ha generado varias controversias. En febrero, la función de generación de imágenes de Gemini estuvo en problemas después de mostrar sesgos en la generación de imágenes de personas. Como resultado, el generador de imágenes se detuvo temporalmente y Google tuvo que explicar el comportamiento inesperado.
Un usuario de X afirmó que Gemini resumió un archivo PDF automáticamente y sin que se le pidiera explícitamente que lo hiciera, y señaló que la configuración requerida ya estaba deshabilitada.
Otro informe afirmó que Google contrata contratistas para calificar las respuestas de Gemini en función de cualidades como precisión, claridad y seguridad y comparar las respuestas con las del LLM Claude de Anthropic. Los contratistas notaron similitudes entre las respuestas de las dos plataformas. Si bien comparar modelos no es infrecuente, el informe no recibió una respuesta satisfactoria de Google.






















































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































