
Noticias
Agentes de motor de búsqueda multimodal alimentados por Blip-2 y Gemini

Esta publicación fue coautora de Rafael Groedes.
Introducción
Los modelos tradicionales solo pueden procesar un solo tipo de datos, como texto, imágenes o datos tabulares. La multimodalidad es un concepto de tendencia en la comunidad de investigación de IA, que se refiere a la capacidad de un modelo para aprender de múltiples tipos de datos simultáneamente. Esta nueva tecnología (no es realmente nueva, pero mejoró significativamente en los últimos meses) tiene numerosas aplicaciones potenciales que transformarán la experiencia del usuario de muchos productos.
Un buen ejemplo sería la nueva forma en que los motores de búsqueda funcionarán en el futuro, donde los usuarios pueden ingresar consultas utilizando una combinación de modalidades, como texto, imágenes, audio, etc. Otro ejemplo podría ser mejorar los sistemas de atención al cliente con AI para la voz. e entradas de texto. En el comercio electrónico, están mejorando el descubrimiento de productos al permitir a los usuarios buscar usando imágenes y texto. Usaremos este último como nuestro estudio de caso en este artículo.
Los laboratorios de investigación de IA Frontier están enviando varios modelos que admiten múltiples modalidades cada mes. Clip y Dall-E por OpenAI y Blip-2 por Salesforce Combine Image and Text. ImageBind por meta expandió el concepto de modalidad múltiple a seis modalidades (texto, audio, profundidad, térmica, imagen y unidades de medición inerciales).
En este artículo, exploraremos Blip-2 explicando su arquitectura, la forma en que funciona su función de pérdida y su proceso de capacitación. También presentamos un caso de uso práctico que combina Blip-2 y Gemini para crear un agente de búsqueda de moda multimodal que pueda ayudar a los clientes a encontrar el mejor atuendo basado en texto o mensajes de texto e indicaciones de imagen.

Como siempre, el código está disponible en nuestro GitHub.
Blip-2: un modelo multimodal
Blip-2 (pre-entrenamiento de imagen de lenguaje de arranque) [1] es un modelo de lenguaje de visión diseñado para resolver tareas como la respuesta de las preguntas visuales o el razonamiento multimodal basado en entradas de ambas modalidades: imagen y texto. Como veremos a continuación, este modelo se desarrolló para abordar dos desafíos principales en el dominio del idioma de la visión:
- Reducir el costo computacional Utilizando codificadores visuales pre-entrenados congelados y LLM, reduciendo drásticamente los recursos de capacitación necesarios en comparación con una capacitación conjunta de redes de visión e idiomas.
- Mejora de la alineación del idioma visual Al introducir Q-former. Q-Former acerca los incrustaciones visuales y textuales, lo que lleva a un mejor rendimiento de la tarea de razonamiento y la capacidad de realizar una recuperación multimodal.
Arquitectura
La arquitectura de Blip-2 sigue un diseño modular que integra tres módulos:
- Visual Codificador es un modelo visual congelado, como VIT, que extrae incrustaciones visuales de las imágenes de entrada (que luego se usan en tareas aguas abajo).
- Consulta Transformador (Q-Former) es la clave de esta arquitectura. Consiste en un transformador ligero entrenable que actúa como una capa intermedia entre los modelos visuales y de lenguaje. Es responsable de generar consultas contextualizadas a partir de los incrustaciones visuales para que el modelo de lenguaje pueda procesarlos de manera efectiva.
- LLM es un LLM pre-capacitado congelado que procesa incrustaciones visuales refinadas para generar descripciones o respuestas textuales.
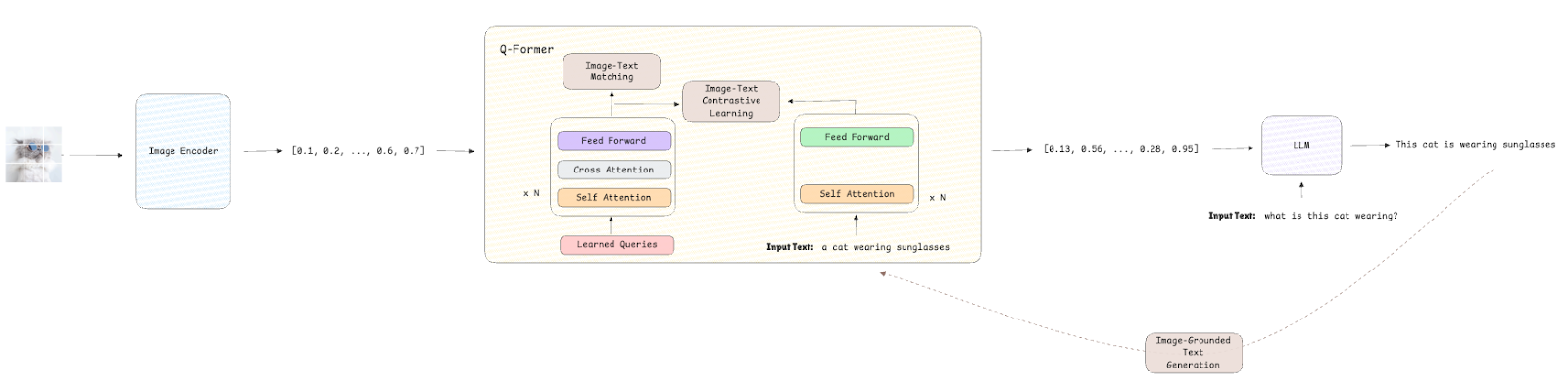
Funciones de pérdida
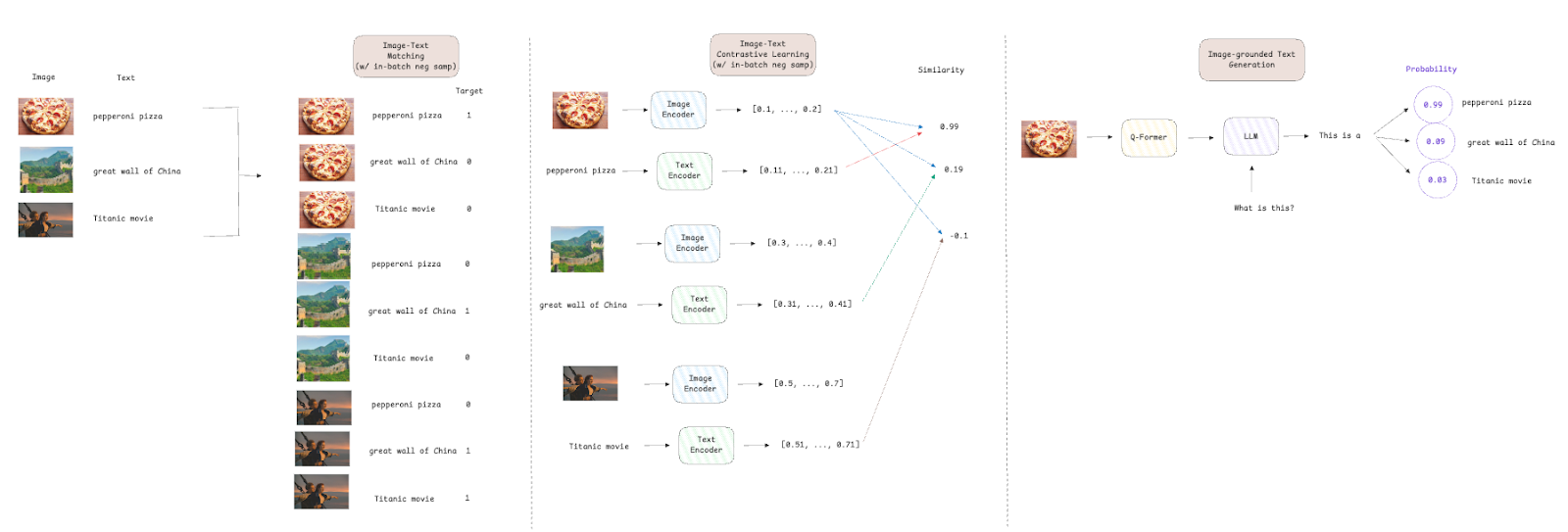
Blip-2 tiene tres funciones de pérdida para entrenar el Q-formador módulo:
- Pérdida de texto de texto [2] Haga cumplir la alineación entre los incrustaciones visuales y de texto maximizando la similitud de las representaciones emparejadas de texto de imagen mientras se separa pares diferentes.
- Pérdida de coincidencia de texto de imagen [3] es una pérdida de clasificación binaria que tiene como objetivo hacer que el modelo aprenda alineaciones de grano fino predecir si una descripción de texto coincide con la imagen (positivo, es decir, objetivo = 1) o no (negativo, es decir, objetivo = 0).
- Pérdida de generación de texto con conexión a imagen [4] es una pérdida de entropía cruzada utilizada en LLM para predecir la probabilidad del siguiente token en la secuencia. La arquitectura Q-former no permite interacciones entre los incrustaciones de la imagen y los tokens de texto; Por lo tanto, el texto debe generarse basándose únicamente en la información visual, lo que obliga al modelo a extraer características visuales relevantes.
Para ambosPérdida de contraste de texto mago y Pérdida de coincidencia de texto de imagenlos autores utilizaron un muestreo negativo en lotes, lo que significa que si tenemos un tamaño por lotes de 512, cada par de texto de imagen tiene una muestra positiva y 511 muestras negativas. Este enfoque aumenta la eficiencia ya que las muestras negativas se toman del lote, y no hay necesidad de buscar todo el conjunto de datos. También proporciona un conjunto más diverso de comparaciones, lo que lleva a una mejor estimación de gradiente y una convergencia más rápida.
Proceso de capacitación
El entrenamiento de Blip-2 consta de dos etapas:
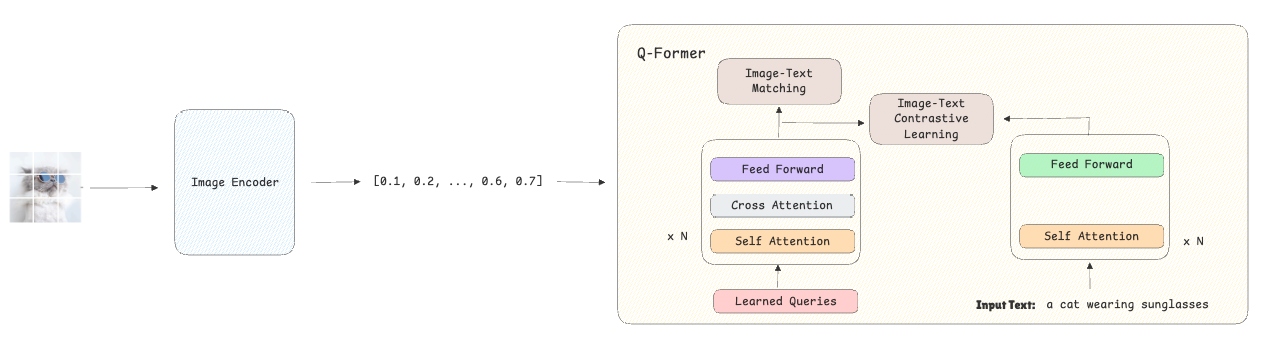
Etapa 1-Bootstrapping Representación visual en idioma:
- El modelo recibe imágenes como entrada que se convierten en una incrustación utilizando el codificador visual congelado.
- Junto con estas imágenes, el modelo recibe sus descripciones de texto, que también se convierten en incrustaciones.
- El Q-former está entrenado usando pérdida de texto de textoasegurando que las integridades visuales se alineen estrechamente con sus incrustaciones textuales correspondientes y se aleje más de las descripciones de texto que no coinciden. Al mismo tiempo, el Pérdida de coincidencia de texto de imagen Ayuda al modelo a desarrollar representaciones de grano fino aprendiendo a clasificar si un texto determinado describe correctamente la imagen o no.
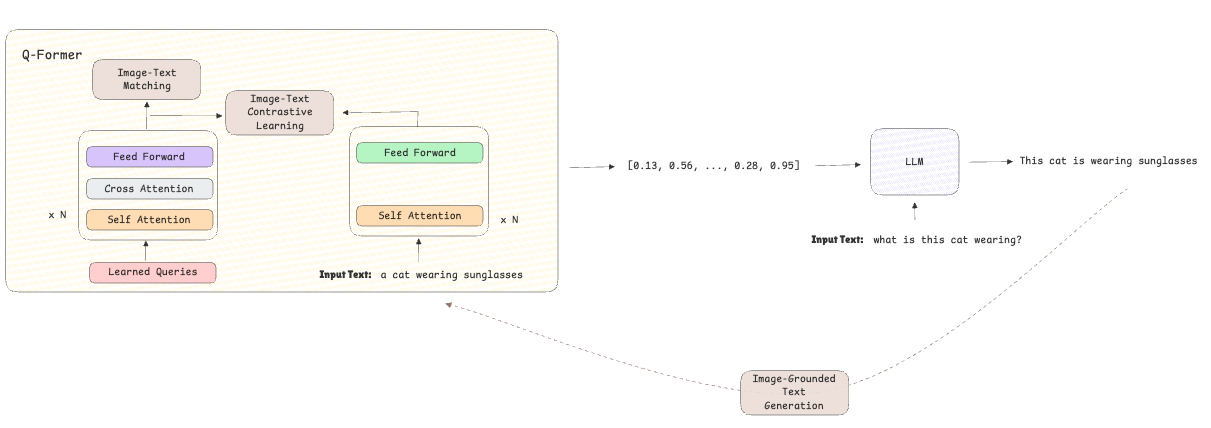
Etapa 2-Bootstrapping Vision-to Language Generation:
- El modelo de lenguaje previamente capacitado está integrado en la arquitectura para generar texto basado en las representaciones previamente aprendidas.
- El enfoque cambia de la alineación a la generación de texto mediante el uso de la pérdida de generación de texto con conexión a imagen que mejora las capacidades del modelo de razonamiento y generación de texto.
Creación de un agente de búsqueda de moda multimodal usando Blip-2 y Gemini
En esta sección, aprovecharemos las capacidades multimodales de Blip-2 para construir un agente de búsqueda de asistente de moda que pueda recibir texto de entrada y/o imágenes y recomendaciones de devolver. Para las capacidades de conversación del agente, utilizaremos Gemini 1.5 Pro alojado en Vertex AI, y para la interfaz, construiremos una aplicación de transmisión.
El conjunto de datos de moda utilizado en este caso de uso tiene licencia bajo la licencia MIT y se puede acceder a través del siguiente enlace: conjunto de datos de imágenes de productos de moda. Consiste en más de 44k imágenes de productos de moda.
El primer paso para hacer esto posible es configurar un Vector DB. Esto permite al agente realizar una búsqueda vectorizada basada en los incrustaciones de la imagen de los elementos disponibles en la tienda y los incrustaciones de texto o imagen de la entrada. Utilizamos Docker y Docker-Compose para ayudarnos a establecer el medio ambiente:
- Compuesto de acopolador con Postgres (la base de datos) y la extensión PGVector que permite la búsqueda vectorizada.
services:
postgres:
container_name: container-pg
image: ankane/pgvector
hostname: localhost
ports:
- "5432:5432"
env_file:
- ./env/postgres.env
volumes:
- postgres-data:/var/lib/postgresql/data
restart: unless-stopped
pgadmin:
container_name: container-pgadmin
image: dpage/pgadmin4
depends_on:
- postgres
ports:
- "5050:80"
env_file:
- ./env/pgadmin.env
restart: unless-stopped
volumes:
postgres-data:- Archivo env enviado con las variables para iniciar sesión en la base de datos.
POSTGRES_DB=postgres
POSTGRES_USER=admin
POSTGRES_PASSWORD=root- Archivo env envado con las variables para iniciar sesión en la interfaz de usuario para consultar manual la base de datos (opcional).
[email protected]
PGADMIN_DEFAULT_PASSWORD=root- Archivo ENV de conexión con todos los componentes para usar para conectarse a PGVector usando Langchain.
DRIVER=psycopg
HOST=localhost
PORT=5432
DATABASE=postgres
USERNAME=admin
PASSWORD=rootUna vez que el Vector DB está configurado (Docker -Compose Up -D), es hora de crear los agentes y herramientas para realizar una búsqueda multimodal. Construimos dos agentes para resolver este caso de uso: uno para comprender lo que el usuario solicita y otro para proporcionar la recomendación:
- El clasificador es responsable de recibir el mensaje de entrada del cliente y extraer qué categoría de ropa está buscando, por ejemplo, camisetas, pantalones, zapatos, camisetas o camisas. También devolverá la cantidad de artículos que el cliente desea para que podamos recuperar el número exacto del Vector DB.
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_google_vertexai import ChatVertexAI
from pydantic import BaseModel, Field
class ClassifierOutput(BaseModel):
"""
Data structure for the model's output.
"""
category: list = Field(
description="A list of clothes category to search for ('t-shirt', 'pants', 'shoes', 'jersey', 'shirt')."
)
number_of_items: int = Field(description="The number of items we should retrieve.")
class Classifier:
"""
Classifier class for classification of input text.
"""
def __init__(self, model: ChatVertexAI) -> None:
"""
Initialize the Chain class by creating the chain.
Args:
model (ChatVertexAI): The LLM model.
"""
super().__init__()
parser = PydanticOutputParser(pydantic_object=ClassifierOutput)
text_prompt = """
You are a fashion assistant expert on understanding what a customer needs and on extracting the category or categories of clothes a customer wants from the given text.
Text:
text
Instructions:
1. Read carefully the text.
2. Extract the category or categories of clothes the customer is looking for, it can be:
- t-shirt if the custimer is looking for a t-shirt.
- pants if the customer is looking for pants.
- jacket if the customer is looking for a jacket.
- shoes if the customer is looking for shoes.
- jersey if the customer is looking for a jersey.
- shirt if the customer is looking for a shirt.
3. If the customer is looking for multiple items of the same category, return the number of items we should retrieve. If not specfied but the user asked for more than 1, return 2.
4. If the customer is looking for multiple category, the number of items should be 1.
5. Return a valid JSON with the categories found, the key must be 'category' and the value must be a list with the categories found and 'number_of_items' with the number of items we should retrieve.
Provide the output as a valid JSON object without any additional formatting, such as backticks or extra text. Ensure the JSON is correctly structured according to the schema provided below.
format_instructions
Answer:
"""
prompt = PromptTemplate.from_template(
text_prompt, partial_variables="format_instructions": parser.get_format_instructions()
)
self.chain = prompt | model | parser
def classify(self, text: str) -> ClassifierOutput:
"""
Get the category from the model based on the text context.
Args:
text (str): user message.
Returns:
ClassifierOutput: The model's answer.
"""
try:
return self.chain.invoke("text": text)
except Exception as e:
raise RuntimeError(f"Error invoking the chain: e")
- El asistente es responsable de responder con una recomendación personalizada recuperada del Vector DB. En este caso, también estamos aprovechando las capacidades multimodales de Gemini para analizar las imágenes recuperadas y producir una mejor respuesta.
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_google_vertexai import ChatVertexAI
from pydantic import BaseModel, Field
class AssistantOutput(BaseModel):
"""
Data structure for the model's output.
"""
answer: str = Field(description="A string with the fashion advice for the customer.")
class Assistant:
"""
Assitant class for providing fashion advice.
"""
def __init__(self, model: ChatVertexAI) -> None:
"""
Initialize the Chain class by creating the chain.
Args:
model (ChatVertexAI): The LLM model.
"""
super().__init__()
parser = PydanticOutputParser(pydantic_object=AssistantOutput)
text_prompt = """
You work for a fashion store and you are a fashion assistant expert on understanding what a customer needs.
Based on the items that are available in the store and the customer message below, provide a fashion advice for the customer.
Number of items: number_of_items
Images of items:
items
Customer message:
customer_message
Instructions:
1. Check carefully the images provided.
2. Read carefully the customer needs.
3. Provide a fashion advice for the customer based on the items and customer message.
4. Return a valid JSON with the advice, the key must be 'answer' and the value must be a string with your advice.
Provide the output as a valid JSON object without any additional formatting, such as backticks or extra text. Ensure the JSON is correctly structured according to the schema provided below.
format_instructions
Answer:
"""
prompt = PromptTemplate.from_template(
text_prompt, partial_variables="format_instructions": parser.get_format_instructions()
)
self.chain = prompt | model | parser
def get_advice(self, text: str, items: list, number_of_items: int) -> AssistantOutput:
"""
Get advice from the model based on the text and items context.
Args:
text (str): user message.
items (list): items found for the customer.
number_of_items (int): number of items to be retrieved.
Returns:
AssistantOutput: The model's answer.
"""
try:
return self.chain.invoke("customer_message": text, "items": items, "number_of_items": number_of_items)
except Exception as e:
raise RuntimeError(f"Error invoking the chain: e")
En términos de herramientas, definimos uno basado en Blip-2. Consiste en una función que recibe un texto o imagen como entrada y devuelve incrustaciones normalizadas. Dependiendo de la entrada, los incrustaciones se producen utilizando el modelo de incrustación de texto o el modelo de incrustación de imagen de Blip-2.
from typing import Optional
import numpy as np
import torch
import torch.nn.functional as F
from PIL import Image
from PIL.JpegImagePlugin import JpegImageFile
from transformers import AutoProcessor, Blip2TextModelWithProjection, Blip2VisionModelWithProjection
PROCESSOR = AutoProcessor.from_pretrained("Salesforce/blip2-itm-vit-g")
TEXT_MODEL = Blip2TextModelWithProjection.from_pretrained("Salesforce/blip2-itm-vit-g", torch_dtype=torch.float32).to(
"cpu"
)
IMAGE_MODEL = Blip2VisionModelWithProjection.from_pretrained(
"Salesforce/blip2-itm-vit-g", torch_dtype=torch.float32
).to("cpu")
def generate_embeddings(text: Optional[str] = None, image: Optional[JpegImageFile] = None) -> np.ndarray:
"""
Generate embeddings from text or image using the Blip2 model.
Args:
text (Optional[str]): customer input text
image (Optional[Image]): customer input image
Returns:
np.ndarray: embedding vector
"""
if text:
inputs = PROCESSOR(text=text, return_tensors="pt").to("cpu")
outputs = TEXT_MODEL(**inputs)
embedding = F.normalize(outputs.text_embeds, p=2, dim=1)[:, 0, :].detach().numpy().flatten()
else:
inputs = PROCESSOR(images=image, return_tensors="pt").to("cpu", torch.float16)
outputs = IMAGE_MODEL(**inputs)
embedding = F.normalize(outputs.image_embeds, p=2, dim=1).mean(dim=1).detach().numpy().flatten()
return embedding
Tenga en cuenta que creamos la conexión a PGVector con un modelo de incrustación diferente porque es obligatorio, aunque no se utilizará ya que almacenaremos los incrustaciones producidos por Blip-2 directamente.
En el ciclo a continuación, iteramos sobre todas las categorías de ropa, cargamos las imágenes y creamos y agreguamos las incrustaciones que se almacenarán en el Vector DB en una lista. Además, almacenamos la ruta a la imagen como texto para que podamos representarla en nuestra aplicación de transmisión. Finalmente, almacenamos la categoría para filtrar los resultados en función de la categoría predicha por el agente del clasificador.
import glob
import os
from dotenv import load_dotenv
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from langchain_postgres.vectorstores import PGVector
from PIL import Image
from blip2 import generate_embeddings
load_dotenv("env/connection.env")
CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.getenv("DRIVER"),
host=os.getenv("HOST"),
port=os.getenv("PORT"),
database=os.getenv("DATABASE"),
user=os.getenv("USERNAME"),
password=os.getenv("PASSWORD"),
)
vector_db = PGVector(
embeddings=HuggingFaceEmbeddings(model_name="nomic-ai/modernbert-embed-base"), # does not matter for our use case
collection_name="fashion",
connection=CONNECTION_STRING,
use_jsonb=True,
)
if __name__ == "__main__":
# generate image embeddings
# save path to image in text
# save category in metadata
texts = []
embeddings = []
metadatas = []
for category in glob.glob("images/*"):
cat = category.split("/")[-1]
for img in glob.glob(f"category/*"):
texts.append(img)
embeddings.append(generate_embeddings(image=Image.open(img)).tolist())
metadatas.append("category": cat)
vector_db.add_embeddings(texts, embeddings, metadatas)Ahora podemos construir nuestra aplicación aerodinámica para chatear con nuestro asistente y pedir recomendaciones. El chat comienza con el agente preguntando cómo puede ayudar y proporcionar un cuadro para que el cliente escriba un mensaje y/o cargue un archivo.
Una vez que el cliente responde, el flujo de trabajo es el siguiente:
- El agente del clasificador identifica qué categorías de ropa está buscando el cliente y cuántas unidades desean.
- Si el cliente carga un archivo, este archivo se convertirá en una incrustación, y buscaremos elementos similares en el Vector DB, condicionado por la categoría de ropa que el cliente desea y la cantidad de unidades.
- Los elementos recuperados y el mensaje de entrada del cliente se envían al agente asistente para producir el mensaje de recomendación que se transforma junto con las imágenes recuperadas.
- Si el cliente no cargó un archivo, el proceso es el mismo, pero en lugar de generar insertos de imagen para la recuperación, creamos incrustaciones de texto.
import os
import streamlit as st
from dotenv import load_dotenv
from langchain_google_vertexai import ChatVertexAI
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from langchain_postgres.vectorstores import PGVector
from PIL import Image
import utils
from assistant import Assistant
from blip2 import generate_embeddings
from classifier import Classifier
load_dotenv("env/connection.env")
load_dotenv("env/llm.env")
CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.getenv("DRIVER"),
host=os.getenv("HOST"),
port=os.getenv("PORT"),
database=os.getenv("DATABASE"),
user=os.getenv("USERNAME"),
password=os.getenv("PASSWORD"),
)
vector_db = PGVector(
embeddings=HuggingFaceEmbeddings(model_name="nomic-ai/modernbert-embed-base"), # does not matter for our use case
collection_name="fashion",
connection=CONNECTION_STRING,
use_jsonb=True,
)
model = ChatVertexAI(model_name=os.getenv("MODEL_NAME"), project=os.getenv("PROJECT_ID"), temperarture=0.0)
classifier = Classifier(model)
assistant = Assistant(model)
st.title("Welcome to ZAAI's Fashion Assistant")
user_input = st.text_input("Hi, I'm ZAAI's Fashion Assistant. How can I help you today?")
uploaded_file = st.file_uploader("Upload an image", type=["jpg", "jpeg", "png"])
if st.button("Submit"):
# understand what the user is asking for
classification = classifier.classify(user_input)
if uploaded_file:
image = Image.open(uploaded_file)
image.save("input_image.jpg")
embedding = generate_embeddings(image=image)
else:
# create text embeddings in case the user does not upload an image
embedding = generate_embeddings(text=user_input)
# create a list of items to be retrieved and the path
retrieved_items = []
retrieved_items_path = []
for item in classification.category:
clothes = vector_db.similarity_search_by_vector(
embedding, k=classification.number_of_items, filter="category": "$in": [item]
)
for clothe in clothes:
retrieved_items.append("bytesBase64Encoded": utils.encode_image_to_base64(clothe.page_content))
retrieved_items_path.append(clothe.page_content)
# get assistant's recommendation
assistant_output = assistant.get_advice(user_input, retrieved_items, len(retrieved_items))
st.write(assistant_output.answer)
cols = st.columns(len(retrieved_items)+1)
for col, retrieved_item in zip(cols, ["input_image.jpg"]+retrieved_items_path):
col.image(retrieved_item)
user_input = st.text_input("")
else:
st.warning("Please provide text.")Ambos ejemplos se pueden ver a continuación:
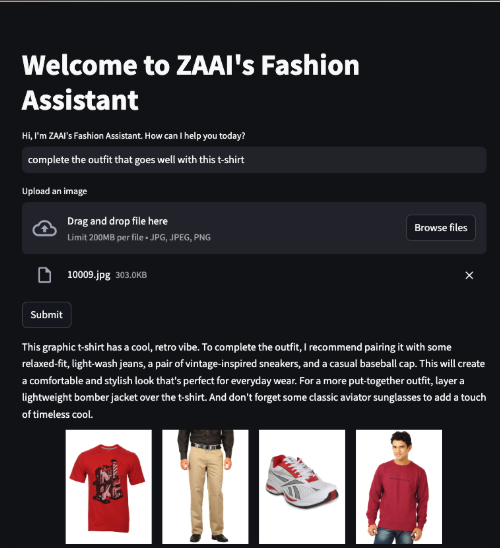
La Figura 6 muestra un ejemplo en el que el cliente cargó una imagen de una camiseta roja y le pidió al agente que completara el atuendo.
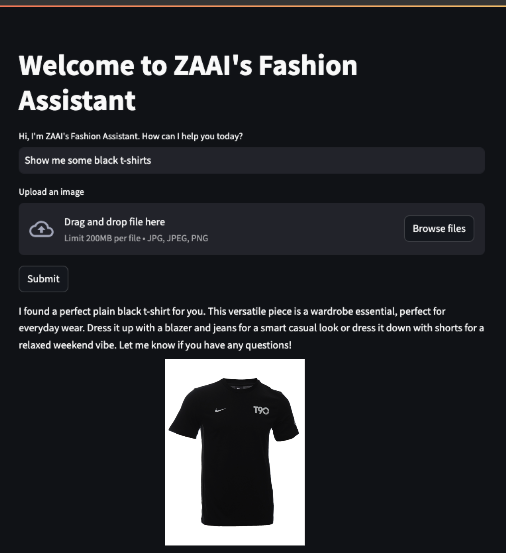
La Figura 7 muestra un ejemplo más directo en el que el cliente le pidió al agente que les mostrara camisetas negras.
Conclusión
La IA multimodal ya no es solo un tema de investigación. Se está utilizando en la industria para remodelar la forma en que los clientes interactúan con los catálogos de la empresa. En este artículo, exploramos cómo se pueden combinar modelos multimodales como Blip-2 y Gemini para abordar los problemas del mundo real y proporcionar una experiencia más personalizada a los clientes de una manera escalable.
Exploramos la arquitectura de Blip-2 en profundidad, demostrando cómo une la brecha entre las modalidades de texto y imagen. Para extender sus capacidades, desarrollamos un sistema de agentes, cada uno especializado en diferentes tareas. Este sistema integra un LLM (Gemini) y una base de datos vectorial, lo que permite la recuperación del catálogo de productos utilizando incrustaciones de texto e imágenes. También aprovechamos el razonamiento multimodal de Géminis para mejorar las respuestas del agente de ventas para ser más humanos.
Con herramientas como Blip-2, Gemini y PG Vector, el futuro de la búsqueda y recuperación multimodal ya está sucediendo, y los motores de búsqueda del futuro se verán muy diferentes de los que usamos hoy.
Acerca de mí
Empresario en serie y líder en el espacio de IA. Desarrollo productos de IA para empresas e invierto en nuevas empresas centradas en la IA.
Fundador @ Zaai | LinkedIn | X/Twitter
Referencias
[1] Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi. 2023. BLIP-2: Bootstrapping Language-Image Training con codificadores de imágenes congeladas y modelos de idiomas grandes. ARXIV: 2301.12597
[2] Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, CE Liu, Dilip Krishnan. 2020. Aprendizaje contrastante supervisado. ARXIV: 2004.11362
[3] Junnan Li, Rampasaath R. Selvaraju, Akhilesh Deepak Gotmare, Shafiq Joty, Caiming Xiong, Steven Hoi. 2021. Alinee antes del fusible: el aprendizaje de la representación del lenguaje y la visión con la destilación de impulso. ARXIV: 2107.07651
[4] Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, Hsiao-Wuen Hon. 2019. Modelo de lenguaje unificado Precrendimiento para la comprensión del lenguaje natural y la generación. ARXIV: 1905.03197
Noticias
Revivir el compromiso en el aula de español: un desafío musical con chatgpt – enfoque de la facultad



Teen emprendedor que usa chatgpt para ayudarlo con su negocio
El emprendimiento adolescente sigue en aumento. Según Junior Achievement Research, el 66% de los adolescentes estadounidenses de entre 13 y 17 años dicen que es probable que considere comenzar un negocio como adultos, con el monitor de emprendimiento global 2023-2024 que encuentra que el 24% de los jóvenes de 18 a 24 años son actualmente empresarios. Estos jóvenes fundadores no son solo soñando, están construyendo empresas reales que generan ingresos y crean un impacto social, y están utilizando las indicaciones de ChatGPT para ayudarlos.
En Wit (lo que sea necesario), la organización que fundó en 2009, hemos trabajado con más de 10,000 jóvenes empresarios. Durante el año pasado, he observado un cambio en cómo los adolescentes abordan la planificación comercial. Con nuestra orientación, están utilizando herramientas de IA como ChatGPT, no como atajos, sino como socios de pensamiento estratégico para aclarar ideas, probar conceptos y acelerar la ejecución.
Los emprendedores adolescentes más exitosos han descubierto indicaciones específicas que los ayudan a pasar de una idea a otra. Estas no son sesiones genéricas de lluvia de ideas: están utilizando preguntas específicas que abordan los desafíos únicos que enfrentan los jóvenes fundadores: recursos limitados, compromisos escolares y la necesidad de demostrar sus conceptos rápidamente.
Aquí hay cinco indicaciones de ChatGPT que ayudan constantemente a los emprendedores adolescentes a construir negocios que importan.
1. El problema del primer descubrimiento chatgpt aviso
“Me doy cuenta de que [specific group of people]
luchar contra [specific problem I’ve observed]. Ayúdame a entender mejor este problema explicando: 1) por qué existe este problema, 2) qué soluciones existen actualmente y por qué son insuficientes, 3) cuánto las personas podrían pagar para resolver esto, y 4) tres formas específicas en que podría probar si este es un problema real que vale la pena resolver “.
Un adolescente podría usar este aviso después de notar que los estudiantes en la escuela luchan por pagar el almuerzo. En lugar de asumir que entienden el alcance completo, podrían pedirle a ChatGPT que investigue la deuda del almuerzo escolar como un problema sistémico. Esta investigación puede llevarlos a crear un negocio basado en productos donde los ingresos ayuden a pagar la deuda del almuerzo, lo que combina ganancias con el propósito.
Los adolescentes notan problemas de manera diferente a los adultos porque experimentan frustraciones únicas, desde los desafíos de las organizaciones escolares hasta las redes sociales hasta las preocupaciones ambientales. Según la investigación de Square sobre empresarios de la Generación de la Generación Z, el 84% planea ser dueños de negocios dentro de cinco años, lo que los convierte en candidatos ideales para las empresas de resolución de problemas.
2. El aviso de chatgpt de chatgpt de chatgpt de realidad de la realidad del recurso
“Soy [age] años con aproximadamente [dollar amount] invertir y [number] Horas por semana disponibles entre la escuela y otros compromisos. Según estas limitaciones, ¿cuáles son tres modelos de negocio que podría lanzar de manera realista este verano? Para cada opción, incluya costos de inicio, requisitos de tiempo y los primeros tres pasos para comenzar “.
Este aviso se dirige al elefante en la sala: la mayoría de los empresarios adolescentes tienen dinero y tiempo limitados. Cuando un empresario de 16 años emplea este enfoque para evaluar un concepto de negocio de tarjetas de felicitación, puede descubrir que pueden comenzar con $ 200 y escalar gradualmente. Al ser realistas sobre las limitaciones por adelantado, evitan el exceso de compromiso y pueden construir hacia objetivos de ingresos sostenibles.
Según el informe de Gen Z de Square, el 45% de los jóvenes empresarios usan sus ahorros para iniciar negocios, con el 80% de lanzamiento en línea o con un componente móvil. Estos datos respaldan la efectividad de la planificación basada en restricciones: cuando funcionan los adolescentes dentro de las limitaciones realistas, crean modelos comerciales más sostenibles.
3. El aviso de chatgpt del simulador de voz del cliente
“Actúa como un [specific demographic] Y dame comentarios honestos sobre esta idea de negocio: [describe your concept]. ¿Qué te excitaría de esto? ¿Qué preocupaciones tendrías? ¿Cuánto pagarías de manera realista? ¿Qué necesitaría cambiar para que se convierta en un cliente? “
Los empresarios adolescentes a menudo luchan con la investigación de los clientes porque no pueden encuestar fácilmente a grandes grupos o contratar firmas de investigación de mercado. Este aviso ayuda a simular los comentarios de los clientes haciendo que ChatGPT adopte personas específicas.
Un adolescente que desarrolla un podcast para atletas adolescentes podría usar este enfoque pidiéndole a ChatGPT que responda a diferentes tipos de atletas adolescentes. Esto ayuda a identificar temas de contenido que resuenan y mensajes que se sienten auténticos para el público objetivo.
El aviso funciona mejor cuando se vuelve específico sobre la demografía, los puntos débiles y los contextos. “Actúa como un estudiante de último año de secundaria que solicita a la universidad” produce mejores ideas que “actuar como un adolescente”.
4. El mensaje mínimo de diseñador de prueba viable chatgpt
“Quiero probar esta idea de negocio: [describe concept] sin gastar más de [budget amount] o más de [time commitment]. Diseñe tres experimentos simples que podría ejecutar esta semana para validar la demanda de los clientes. Para cada prueba, explique lo que aprendería, cómo medir el éxito y qué resultados indicarían que debería avanzar “.
Este aviso ayuda a los adolescentes a adoptar la metodología Lean Startup sin perderse en la jerga comercial. El enfoque en “This Week” crea urgencia y evita la planificación interminable sin acción.
Un adolescente que desea probar un concepto de línea de ropa podría usar este indicador para diseñar experimentos de validación simples, como publicar maquetas de diseño en las redes sociales para evaluar el interés, crear un formulario de Google para recolectar pedidos anticipados y pedirles a los amigos que compartan el concepto con sus redes. Estas pruebas no cuestan nada más que proporcionar datos cruciales sobre la demanda y los precios.
5. El aviso de chatgpt del generador de claridad de tono
“Convierta esta idea de negocio en una clara explicación de 60 segundos: [describe your business]. La explicación debe incluir: el problema que resuelve, su solución, a quién ayuda, por qué lo elegirían sobre las alternativas y cómo se ve el éxito. Escríbelo en lenguaje de conversación que un adolescente realmente usaría “.
La comunicación clara separa a los empresarios exitosos de aquellos con buenas ideas pero una ejecución deficiente. Este aviso ayuda a los adolescentes a destilar conceptos complejos a explicaciones convincentes que pueden usar en todas partes, desde las publicaciones en las redes sociales hasta las conversaciones con posibles mentores.
El énfasis en el “lenguaje de conversación que un adolescente realmente usaría” es importante. Muchas plantillas de lanzamiento comercial suenan artificiales cuando se entregan jóvenes fundadores. La autenticidad es más importante que la jerga corporativa.
Más allá de las indicaciones de chatgpt: estrategia de implementación
La diferencia entre los adolescentes que usan estas indicaciones de manera efectiva y aquellos que no se reducen a seguir. ChatGPT proporciona dirección, pero la acción crea resultados.
Los jóvenes empresarios más exitosos con los que trabajo usan estas indicaciones como puntos de partida, no de punto final. Toman las sugerencias generadas por IA e inmediatamente las prueban en el mundo real. Llaman a clientes potenciales, crean prototipos simples e iteran en función de los comentarios reales.
Investigaciones recientes de Junior Achievement muestran que el 69% de los adolescentes tienen ideas de negocios, pero se sienten inciertos sobre el proceso de partida, con el miedo a que el fracaso sea la principal preocupación para el 67% de los posibles empresarios adolescentes. Estas indicaciones abordan esa incertidumbre al desactivar los conceptos abstractos en los próximos pasos concretos.
La imagen más grande
Los emprendedores adolescentes que utilizan herramientas de IA como ChatGPT representan un cambio en cómo está ocurriendo la educación empresarial. Según la investigación mundial de monitores empresariales, los jóvenes empresarios tienen 1,6 veces más probabilidades que los adultos de querer comenzar un negocio, y son particularmente activos en la tecnología, la alimentación y las bebidas, la moda y los sectores de entretenimiento. En lugar de esperar clases de emprendimiento formales o programas de MBA, estos jóvenes fundadores están accediendo a herramientas de pensamiento estratégico de inmediato.
Esta tendencia se alinea con cambios más amplios en la educación y la fuerza laboral. El Foro Económico Mundial identifica la creatividad, el pensamiento crítico y la resiliencia como las principales habilidades para 2025, la capacidad de las capacidades que el espíritu empresarial desarrolla naturalmente.
Programas como WIT brindan soporte estructurado para este viaje, pero las herramientas en sí mismas se están volviendo cada vez más accesibles. Un adolescente con acceso a Internet ahora puede acceder a recursos de planificación empresarial que anteriormente estaban disponibles solo para empresarios establecidos con presupuestos significativos.
La clave es usar estas herramientas cuidadosamente. ChatGPT puede acelerar el pensamiento y proporcionar marcos, pero no puede reemplazar el arduo trabajo de construir relaciones, crear productos y servir a los clientes. La mejor idea de negocio no es la más original, es la que resuelve un problema real para personas reales. Las herramientas de IA pueden ayudar a identificar esas oportunidades, pero solo la acción puede convertirlos en empresas que importan.

Precio
ChatGPT y Gemini tienen versiones gratuitas que limitan su acceso a características y modelos. Los planes premium para ambos también comienzan en alrededor de $ 20 por mes. Las características de chatbot, como investigaciones profundas, generación de imágenes y videos, búsqueda web y más, son similares en ChatGPT y Gemini. Sin embargo, los planes de Gemini pagados también incluyen el almacenamiento en la nube de Google Drive (a partir de 2TB) y un conjunto robusto de integraciones en las aplicaciones de Google Workspace.
Los niveles de más alta gama de ChatGPT y Gemini desbloquean el aumento de los límites de uso y algunas características únicas, pero el costo mensual prohibitivo de estos planes (como $ 200 para Chatgpt Pro o $ 250 para Gemini Ai Ultra) los pone fuera del alcance de la mayoría de las personas. Las características específicas del plan Pro de ChatGPT, como el modo O1 Pro que aprovecha el poder de cálculo adicional para preguntas particularmente complicadas, no son especialmente relevantes para el consumidor promedio, por lo que no sentirá que se está perdiendo. Sin embargo, es probable que desee las características que son exclusivas del plan Ai Ultra de Gemini, como la generación de videos VEO 3.
Ganador: Géminis
Plataformas
Puede acceder a ChatGPT y Gemini en la web o a través de aplicaciones móviles (Android e iOS). ChatGPT también tiene aplicaciones de escritorio (macOS y Windows) y una extensión oficial para Google Chrome. Gemini no tiene aplicaciones de escritorio dedicadas o una extensión de Chrome, aunque se integra directamente con el navegador.

(Crédito: OpenAI/PCMAG)
Chatgpt está disponible en otros lugares, Como a través de Siri. Como se mencionó, puede acceder a Gemini en las aplicaciones de Google, como el calendario, Documento, ConducirGmail, Mapas, Mantener, FotosSábanas, y Música de YouTube. Tanto los modelos de Chatgpt como Gemini también aparecen en sitios como la perplejidad. Sin embargo, obtiene la mayor cantidad de funciones de estos chatbots en sus aplicaciones y portales web dedicados.
Las interfaces de ambos chatbots son en gran medida consistentes en todas las plataformas. Son fáciles de usar y no lo abruman con opciones y alternar. ChatGPT tiene algunas configuraciones más para jugar, como la capacidad de ajustar su personalidad, mientras que la profunda interfaz de investigación de Gemini hace un mejor uso de los bienes inmuebles de pantalla.
Ganador: empate
Modelos de IA
ChatGPT tiene dos series primarias de modelos, la serie 4 (su línea de conversación, insignia) y la Serie O (su compleja línea de razonamiento). Gemini ofrece de manera similar una serie Flash de uso general y una serie Pro para tareas más complicadas.
Los últimos modelos de Chatgpt son O3 y O4-Mini, y los últimos de Gemini son 2.5 Flash y 2.5 Pro. Fuera de la codificación o la resolución de una ecuación, pasará la mayor parte de su tiempo usando los modelos de la serie 4-Series y Flash. A continuación, puede ver cómo funcionan estos modelos en una variedad de tareas. Qué modelo es mejor depende realmente de lo que quieras hacer.
Ganador: empate
Búsqueda web
ChatGPT y Gemini pueden buscar información actualizada en la web con facilidad. Sin embargo, ChatGPT presenta mosaicos de artículos en la parte inferior de sus respuestas para una lectura adicional, tiene un excelente abastecimiento que facilita la vinculación de reclamos con evidencia, incluye imágenes en las respuestas cuando es relevante y, a menudo, proporciona más detalles en respuesta. Gemini no muestra nombres de fuente y títulos de artículos completos, e incluye mosaicos e imágenes de artículos solo cuando usa el modo AI de Google. El abastecimiento en este modo es aún menos robusto; Google relega las fuentes a los caretes que se pueden hacer clic que no resaltan las partes relevantes de su respuesta.
Como parte de sus experiencias de búsqueda en la web, ChatGPT y Gemini pueden ayudarlo a comprar. Si solicita consejos de compra, ambos presentan mosaicos haciendo clic en enlaces a los minoristas. Sin embargo, Gemini generalmente sugiere mejores productos y tiene una característica única en la que puede cargar una imagen tuya para probar digitalmente la ropa antes de comprar.
Ganador: chatgpt
Investigación profunda
ChatGPT y Gemini pueden generar informes que tienen docenas de páginas e incluyen más de 50 fuentes sobre cualquier tema. La mayor diferencia entre los dos se reduce al abastecimiento. Gemini a menudo cita más fuentes que CHATGPT, pero maneja el abastecimiento en informes de investigación profunda de la misma manera que lo hace en la búsqueda en modo AI, lo que significa caretas que se puede hacer clic sin destacados en el texto. Debido a que es más difícil conectar las afirmaciones en los informes de Géminis a fuentes reales, es más difícil creerles. El abastecimiento claro de ChatGPT con destacados en el texto es más fácil de confiar. Sin embargo, Gemini tiene algunas características de calidad de vida en ChatGPT, como la capacidad de exportar informes formateados correctamente a Google Docs con un solo clic. Su tono también es diferente. Los informes de ChatGPT se leen como publicaciones de foro elaboradas, mientras que los informes de Gemini se leen como documentos académicos.
Ganador: chatgpt
Generación de imágenes
La generación de imágenes de ChatGPT impresiona independientemente de lo que solicite, incluso las indicaciones complejas para paneles o diagramas cómicos. No es perfecto, pero los errores y la distorsión son mínimos. Gemini genera imágenes visualmente atractivas más rápido que ChatGPT, pero rutinariamente incluyen errores y distorsión notables. Con indicaciones complicadas, especialmente diagramas, Gemini produjo resultados sin sentido en las pruebas.
Arriba, puede ver cómo ChatGPT (primera diapositiva) y Géminis (segunda diapositiva) les fue con el siguiente mensaje: “Genere una imagen de un estudio de moda con una decoración simple y rústica que contrasta con el espacio más agradable. Incluya un sofá marrón y paredes de ladrillo”. La imagen de ChatGPT limita los problemas al detalle fino en las hojas de sus plantas y texto en su libro, mientras que la imagen de Gemini muestra problemas más notables en su tubo de cordón y lámpara.
Ganador: chatgpt
¡Obtenga nuestras mejores historias!

Toda la última tecnología, probada por nuestros expertos
Regístrese en el boletín de informes de laboratorio para recibir las últimas revisiones de productos de PCMAG, comprar asesoramiento e ideas.
Al hacer clic en Registrarme, confirma que tiene más de 16 años y acepta nuestros Términos de uso y Política de privacidad.
¡Gracias por registrarse!
Su suscripción ha sido confirmada. ¡Esté atento a su bandeja de entrada!
Generación de videos
La generación de videos de Gemini es la mejor de su clase, especialmente porque ChatGPT no puede igualar su capacidad para producir audio acompañante. Actualmente, Google bloquea el último modelo de generación de videos de Gemini, VEO 3, detrás del costoso plan AI Ultra, pero obtienes más videos realistas que con ChatGPT. Gemini también tiene otras características que ChatGPT no, como la herramienta Flow Filmmaker, que le permite extender los clips generados y el animador AI Whisk, que le permite animar imágenes fijas. Sin embargo, tenga en cuenta que incluso con VEO 3, aún necesita generar videos varias veces para obtener un gran resultado.
En el ejemplo anterior, solicité a ChatGPT y Gemini a mostrarme un solucionador de cubos de Rubik Rubik que resuelva un cubo. La persona en el video de Géminis se ve muy bien, y el audio acompañante es competente. Al final, hay una buena atención al detalle con el marco que se desplaza, simulando la detención de una grabación de selfies. Mientras tanto, Chatgpt luchó con su cubo, distorsionándolo en gran medida.
Ganador: Géminis
Procesamiento de archivos
Comprender los archivos es una fortaleza de ChatGPT y Gemini. Ya sea que desee que respondan preguntas sobre un manual, editen un currículum o le informen algo sobre una imagen, ninguno decepciona. Sin embargo, ChatGPT tiene la ventaja sobre Gemini, ya que ofrece un reconocimiento de imagen ligeramente mejor y respuestas más detalladas cuando pregunta sobre los archivos cargados. Ambos chatbots todavía a veces inventan citas de documentos proporcionados o malinterpretan las imágenes, así que asegúrese de verificar sus resultados.
Ganador: chatgpt
Escritura creativa
Chatgpt y Gemini pueden generar poemas, obras, historias y más competentes. CHATGPT, sin embargo, se destaca entre los dos debido a cuán únicas son sus respuestas y qué tan bien responde a las indicaciones. Las respuestas de Gemini pueden sentirse repetitivas si no calibra cuidadosamente sus solicitudes, y no siempre sigue todas las instrucciones a la carta.
En el ejemplo anterior, solicité ChatGPT (primera diapositiva) y Gemini (segunda diapositiva) con lo siguiente: “Sin hacer referencia a nada en su memoria o respuestas anteriores, quiero que me escriba un poema de verso gratuito. Preste atención especial a la capitalización, enjambment, ruptura de línea y puntuación. Dado que es un verso libre, no quiero un medidor familiar o un esquema de retiro de la rima, pero quiero que tenga un estilo de coohes. ChatGPT logró entregar lo que pedí en el aviso, y eso era distinto de las generaciones anteriores. Gemini tuvo problemas para generar un poema que incorporó cualquier cosa más allá de las comas y los períodos, y su poema anterior se lee de manera muy similar a un poema que generó antes.
Recomendado por nuestros editores
Ganador: chatgpt
Razonamiento complejo
Los modelos de razonamiento complejos de Chatgpt y Gemini pueden manejar preguntas de informática, matemáticas y física con facilidad, así como mostrar de manera competente su trabajo. En las pruebas, ChatGPT dio respuestas correctas un poco más a menudo que Gemini, pero su rendimiento es bastante similar. Ambos chatbots pueden y le darán respuestas incorrectas, por lo que verificar su trabajo aún es vital si está haciendo algo importante o tratando de aprender un concepto.
Ganador: chatgpt
Integración
ChatGPT no tiene integraciones significativas, mientras que las integraciones de Gemini son una característica definitoria. Ya sea que desee obtener ayuda para editar un ensayo en Google Docs, comparta una pestaña Chrome para hacer una pregunta, pruebe una nueva lista de reproducción de música de YouTube personalizada para su gusto o desbloquee ideas personales en Gmail, Gemini puede hacer todo y mucho más. Es difícil subestimar cuán integrales y poderosas son realmente las integraciones de Géminis.
Ganador: Géminis
Asistentes de IA
ChatGPT tiene GPT personalizados, y Gemini tiene gemas. Ambos son asistentes de IA personalizables. Tampoco es una gran actualización sobre hablar directamente con los chatbots, pero los GPT personalizados de terceros agregan una nueva funcionalidad, como el fácil acceso a Canva para editar imágenes generadas. Mientras tanto, terceros no pueden crear gemas, y no puedes compartirlas. Puede permitir que los GPT personalizados accedan a la información externa o tomen acciones externas, pero las GEM no tienen una funcionalidad similar.
Ganador: chatgpt
Contexto Windows y límites de uso
La ventana de contexto de ChatGPT sube a 128,000 tokens en sus planes de nivel superior, y todos los planes tienen límites de uso dinámicos basados en la carga del servidor. Géminis, por otro lado, tiene una ventana de contexto de 1,000,000 token. Google no está demasiado claro en los límites de uso exactos para Gemini, pero también son dinámicos dependiendo de la carga del servidor. Anecdóticamente, no pude alcanzar los límites de uso usando los planes pagados de Chatgpt o Gemini, pero es mucho más fácil hacerlo con los planes gratuitos.
Ganador: Géminis
Privacidad
La privacidad en Chatgpt y Gemini es una bolsa mixta. Ambos recopilan cantidades significativas de datos, incluidos todos sus chats, y usan esos datos para capacitar a sus modelos de IA de forma predeterminada. Sin embargo, ambos le dan la opción de apagar el entrenamiento. Google al menos no recopila y usa datos de Gemini para fines de capacitación en aplicaciones de espacio de trabajo, como Gmail, de forma predeterminada. ChatGPT y Gemini también prometen no vender sus datos o usarlos para la orientación de anuncios, pero Google y OpenAI tienen historias sórdidas cuando se trata de hacks, filtraciones y diversos fechorías digitales, por lo que recomiendo no compartir nada demasiado sensible.
Ganador: empate









































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































-
 Startups2 años ago
Startups2 años agoRemove.bg: La Revolución en la Edición de Imágenes que Debes Conocer
-
 Tutoriales2 años ago
Tutoriales2 años agoCómo Comenzar a Utilizar ChatGPT: Una Guía Completa para Principiantes
-
 Startups2 años ago
Startups2 años agoDeepgram: Revolucionando el Reconocimiento de Voz con IA
-
 Startups2 años ago
Startups2 años agoStartups de IA en EE.UU. que han recaudado más de $100M en 2024
-
 Recursos2 años ago
Recursos2 años agoCómo Empezar con Popai.pro: Tu Espacio Personal de IA – Guía Completa, Instalación, Versiones y Precios
-
 Recursos2 años ago
Recursos2 años agoPerplexity aplicado al Marketing Digital y Estrategias SEO
-
 Estudiar IA2 años ago
Estudiar IA2 años agoCurso de Inteligencia Artificial Aplicada de 4Geeks Academy 2024
-
 Noticias2 años ago
Noticias2 años agoDos periodistas octogenarios deman a ChatGPT por robar su trabajo