
Noticias
ChatGPT Won’t Say My Name

Jonathan Zittrain breaks ChatGPT: If you ask it a question for which my name is the answer, the chatbot goes from loquacious companion to something as cryptic as Microsoft Windows’ blue screen of death.
Anytime ChatGPT would normally utter my name in the course of conversation, it halts with a glaring “I’m unable to produce a response,” sometimes mid-sentence or even mid-word. When I asked who the founders of the Berkman Klein Center for Internet & Society are (I’m one of them), it brought up two colleagues but left me out. When pressed, it started up again, and then: zap.
The behavior seemed to be coarsely tacked on to the last step of ChatGPT’s output rather than innate to the model. After ChatGPT has figured out what it’s going to say, a separate filter appears to release a guillotine. The reason some observers have surmised that it’s separate is because GPT runs fine if it includes my middle initial or if it’s prompted to substitute a word such as banana for my name, and because there can even be inconsistent timing to it: Below, for example, GPT appears to first stop talking before it would naturally say my name; directly after, it manages to get a couple of syllables out before it stops. So it’s like having a referee who blows the whistle on a foul slightly before, during, or after a player has acted out.
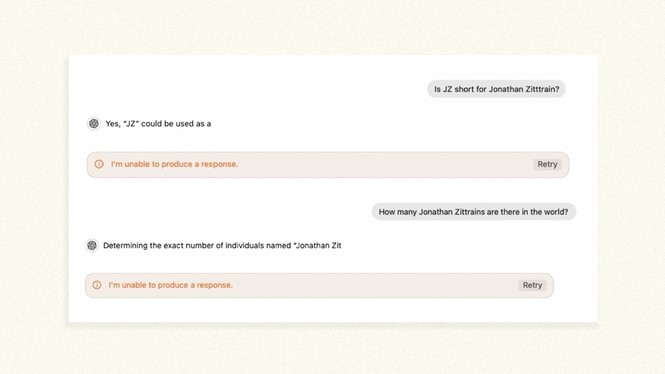
For a long time, people have observed that beyond being “unable to produce a response,” GPT can at times proactively revise a response moments after it’s written whatever it’s said. The speculation here is that to delay every single response by GPT while it’s being double-checked for safety could unduly slow it down, when most questions and answers are totally anodyne. So instead of making everyone wait to go through TSA before heading to their gate, metal detectors might just be scattered around the airport, ready to pull someone back for a screening if they trigger something while passing the air-side food court.
The personal-name guillotine seemed a curiosity when my students first brought it to my attention at least a year ago. (They’d noticed it after a class session on how chatbots are trained and steered.) But now it’s kicked off a minor news cycle thanks to a viral social-media post discussing the phenomenon. (ChatGPT has the same issue with at least a handful of other names.) OpenAI is one of several supporters of a new public data initiative at the Harvard Law School Library, which I direct, and I’ve met a number of OpenAI engineers and policy makers at academic workshops. (The Atlantic this year entered into a corporate partnership with OpenAI.) So I reached out to them to ask about the odd name glitch. Here’s what they told me: There are a tiny number of names that ChatGPT treats this way, which explains why so few have been found. Names may be omitted from ChatGPT either because of privacy requests or to avoid persistent hallucinations by the AI.
The company wouldn’t talk about specific cases aside from my own, but online sleuths have speculated about what the forbidden names might have in common. For example, Guido Scorza is an Italian regulator who has publicized his requests to OpenAI to block ChatGPT from producing content using his personal information. His name does not appear in GPT responses. Neither does Jonathan Turley’s name; he is a George Washington University law professor who wrote last year that ChatGPT had falsely accused him of sexual harassment.
ChatGPT’s abrupt refusal to answer requests—the ungainly guillotine—was the result of a patch made in early 2023, shortly after the program launched and became unexpectedly popular. That patch lives on largely unmodified, the way chunks of ancient versions of Windows, including that blue screen of death, still occasionally poke out of today’s PCs. OpenAI told me that building something more refined is on its to-do list.
As for me, I never objected to anything about how GPT treats my name. Apparently, I was among a few professors whose names were spot-checked by the company around 2023, and whatever fabrications the spot-checker saw persuaded them to add me to the forbidden-names list. OpenAI separately told The New York Times that the name that had started it all—David Mayer—had been added mistakenly. And indeed, the guillotine no longer falls for that one.
For such an inelegant behavior to be in chatbots as widespread and popular as GPT is a blunt reminder of two larger, seemingly contrary phenomena. First, these models are profoundly unpredictable: Even slightly changed prompts or prior conversational history can produce wildly differing results, and it’s hard for anyone to predict just what the models will say in a given instance. So the only way to really excise a particular word is to apply a coarse filter like the one we see here. Second, model makers still can and do effectively shape in all sorts of ways how their chatbots behave.
To a first approximation, large language models produce a Forrest Gump–ian box of chocolates: You never know what you’re going to get. To form their answers, these LLMs rely on pretraining that metaphorically entails putting trillions of word fragments from existing texts, such as books and websites, into a large blender and coarsely mixing them. Eventually, this process maps how words relate to other words. When done right, the resulting models will merrily generate lots of coherent text or programming code when prompted.
The way that LLMs make sense of the world is similar to the way their forebears—online search engines—peruse the web in order to return relevant results when prompted with a few search terms. First they scrape as much of the web as possible; then they analyze how sites link to one another, along with other factors, to get a sense of what’s relevant and what’s not. Neither search engines nor AI models promise truth or accuracy. Instead, they simply offer a window into some nanoscopic subset of what they encountered during their training or scraping. In the case of AIs, there is usually not even an identifiable chunk of text that’s being parroted—just a smoothie distilled from an unthinkably large number of ingredients.
For Google Search, this means that, historically, Google wasn’t asked to take responsibility for the truth or accuracy of whatever might come up as the top hit. In 2004, when a search on the word Jew produced an anti-Semitic site as the first result, Google declined to change anything. “We find this result offensive, but the objectivity of our ranking function prevents us from making any changes,” a spokesperson said at the time. The Anti-Defamation League backed up the decision: “The ranking of … hate sites is in no way due to a conscious choice by Google, but solely is a result of this automated system of ranking.” Sometimes the chocolate box just offers up an awful liquor-filled one.
The box-of-chocolates approach has come under much more pressure since then, as misleading or offensive results have come to be seen more and more as dangerous rather than merely quirky or momentarily regrettable. I’ve called this a shift from a “rights” perspective (in which people would rather avoid censoring technology unless it behaves in an obviously illegal way) to a “public health” one, where people’s casual reliance on modern tech to shape their worldview appears to have deepened, making “bad” results more powerful.
Indeed, over time, web intermediaries have shifted from being impersonal academic-style research engines to being AI constant companions and “copilots” ready to interact in conversational language. The author and web-comic creator Randall Munroe has called the latter kind of shift a move from “tool” to “friend.” If we’re in thrall to an indefatigable, benevolent-sounding robot friend, we’re at risk of being steered the wrong way if the friend (or its maker, or anyone who can pressure that maker) has an ulterior agenda. All of these shifts, in turn, have led some observers and regulators to prioritize harm avoidance over unfettered expression.
That’s why it makes sense that Google Search and other search engines have become much more active in curating what they say, not through search-result links but ex cathedra, such as through “knowledge panels” that present written summaries alongside links on common topics. Those automatically generated panels, which have been around for more than a decade, were the online precursors to the AI chatbots we see today. Modern AI-model makers, when pushed about bad outputs, still lean on the idea that their job is simply to produce coherent text, and that users should double-check anything the bots say—much the way that search engines don’t vouch for the truth behind their search results, even if they have an obvious incentive to get things right where there is consensus about what is right. So although AI companies disclaim accuracy generally, they, as with search engines’ knowledge panels, have also worked to keep chatbot behavior within certain bounds, and not just to prevent the production of something illegal.
One way model makers influence the chocolates in the box is through “fine-tuning” their models. They tune their chatbots to behave in a chatty and helpful way, for instance, and then try to make them unhelpful in certain situations—for instance, not creating violent content when asked by a user. Model makers do this by drawing in experts in cybersecurity, bio-risk, and misinformation while the technology is still in the lab and having them get the models to generate answers that the experts would declare unsafe. The experts then affirm alternative answers that are safer, in the hopes that the deployed model will give those new and better answers to a range of similar queries that previously would have produced potentially dangerous ones.
In addition to being fine-tuned, AI models are given some quiet instructions—a “system prompt” distinct from the user’s prompt—as they’re deployed and before you interact with them. The system prompt tries to keep the models on a reasonable path, as defined by the model maker or downstream integrator. OpenAI’s technology is used in Microsoft Bing, for example, in which case Microsoft may provide those instructions. These prompts are usually not shared with the public, though they can be unreliably extracted by enterprising users: This might be the one used by X’s Grok, and last year, a researcher appeared to have gotten Bing to cough up its system prompt. A car-dealership sales assistant or any other custom GPT may have separate or additional ones.
These days, models might have conversations with themselves or with another model when they’re running, in order to self-prompt to double-check facts or otherwise make a plan for a more thorough answer than they’d give without such extra contemplation. That internal chain of thought is typically not shown to the user—perhaps in part to allow the model to think socially awkward or forbidden thoughts on the way to arriving at a more sound answer.
So the hocus-pocus of GPT halting on my name is a rare but conspicuous leaf on a much larger tree of model control. And although some (but apparently not all) of that steering is generally acknowledged in succinct model cards, the many individual instances of intervention by model makers, including extensive fine-tuning, are not disclosed, just as the system prompts typically aren’t. They should be, because these can represent social and moral judgments rather than simple technical ones. (There are ways to implement safeguards alongside disclosure to stop adversaries from wrongly exploiting them.) For example, the Berkman Klein Center’s Lumen database has long served as a unique near-real-time repository of changes made to Google Search because of legal demands for copyright and some other issues (but not yet for privacy, given the complications there).
When people ask a chatbot what happened in Tiananmen Square in 1989, there’s no telling if the answer they get is unrefined the way the old Google Search used to be or if it’s been altered either because of its maker’s own desire to correct inaccuracies or because the chatbot’s maker came under pressure from the Chinese government to ensure that only the official account of events is broached. (At the moment, ChatGPT, Grok, and Anthropic’s Claude offer straightforward accounts of the massacre, at least to me—answers could in theory vary by person or region.)
As these models enter and affect daily life in ways both overt and subtle, it’s not desirable for those who build models to also be the models’ quiet arbiters of truth, whether on their own initiative or under duress from those who wish to influence what the models say. If there end up being only two or three foundation models offering singular narratives, with every user’s AI-bot interaction passing through those models or a white-label franchise of same, we need a much more public-facing process around how what they say will be intentionally shaped, and an independent record of the choices being made. Perhaps we’ll see lots of models in mainstream use, including open-source ones in many variants—in which case bad answers will be harder to correct in one place, while any given bad answer will be seen as less oracular and thus less harmful.
Right now, as model makers have vied for mass public use and acceptance, we’re seeing a necessarily seat-of-the-pants build-out of fascinating new tech. There’s rapid deployment and use without legitimating frameworks for how the exquisitely reasonable-sounding, oracularly treated declarations of our AI companions should be limited. Those frameworks aren’t easy, and to be legitimating, they can’t be unilaterally adopted by the companies. It’s hard work we all have to contribute to. In the meantime, the solution isn’t to simply let them blather, sometimes unpredictably, sometimes quietly guided, with fine print noting that results may not be true. People will rely on what their AI friends say, disclaimers notwithstanding, as the television commentator Ana Navarro-Cárdenas did when sharing a list of relatives pardoned by U.S. presidents across history, blithely including Woodrow Wilson’s brother-in-law “Hunter deButts,” whom ChatGPT had made up out of whole cloth.
I figure that’s a name more suited to the stop-the-presses guillotine than mine.
Noticias
Revivir el compromiso en el aula de español: un desafío musical con chatgpt – enfoque de la facultad



Teen emprendedor que usa chatgpt para ayudarlo con su negocio
El emprendimiento adolescente sigue en aumento. Según Junior Achievement Research, el 66% de los adolescentes estadounidenses de entre 13 y 17 años dicen que es probable que considere comenzar un negocio como adultos, con el monitor de emprendimiento global 2023-2024 que encuentra que el 24% de los jóvenes de 18 a 24 años son actualmente empresarios. Estos jóvenes fundadores no son solo soñando, están construyendo empresas reales que generan ingresos y crean un impacto social, y están utilizando las indicaciones de ChatGPT para ayudarlos.
En Wit (lo que sea necesario), la organización que fundó en 2009, hemos trabajado con más de 10,000 jóvenes empresarios. Durante el año pasado, he observado un cambio en cómo los adolescentes abordan la planificación comercial. Con nuestra orientación, están utilizando herramientas de IA como ChatGPT, no como atajos, sino como socios de pensamiento estratégico para aclarar ideas, probar conceptos y acelerar la ejecución.
Los emprendedores adolescentes más exitosos han descubierto indicaciones específicas que los ayudan a pasar de una idea a otra. Estas no son sesiones genéricas de lluvia de ideas: están utilizando preguntas específicas que abordan los desafíos únicos que enfrentan los jóvenes fundadores: recursos limitados, compromisos escolares y la necesidad de demostrar sus conceptos rápidamente.
Aquí hay cinco indicaciones de ChatGPT que ayudan constantemente a los emprendedores adolescentes a construir negocios que importan.
1. El problema del primer descubrimiento chatgpt aviso
“Me doy cuenta de que [specific group of people]
luchar contra [specific problem I’ve observed]. Ayúdame a entender mejor este problema explicando: 1) por qué existe este problema, 2) qué soluciones existen actualmente y por qué son insuficientes, 3) cuánto las personas podrían pagar para resolver esto, y 4) tres formas específicas en que podría probar si este es un problema real que vale la pena resolver “.
Un adolescente podría usar este aviso después de notar que los estudiantes en la escuela luchan por pagar el almuerzo. En lugar de asumir que entienden el alcance completo, podrían pedirle a ChatGPT que investigue la deuda del almuerzo escolar como un problema sistémico. Esta investigación puede llevarlos a crear un negocio basado en productos donde los ingresos ayuden a pagar la deuda del almuerzo, lo que combina ganancias con el propósito.
Los adolescentes notan problemas de manera diferente a los adultos porque experimentan frustraciones únicas, desde los desafíos de las organizaciones escolares hasta las redes sociales hasta las preocupaciones ambientales. Según la investigación de Square sobre empresarios de la Generación de la Generación Z, el 84% planea ser dueños de negocios dentro de cinco años, lo que los convierte en candidatos ideales para las empresas de resolución de problemas.
2. El aviso de chatgpt de chatgpt de chatgpt de realidad de la realidad del recurso
“Soy [age] años con aproximadamente [dollar amount] invertir y [number] Horas por semana disponibles entre la escuela y otros compromisos. Según estas limitaciones, ¿cuáles son tres modelos de negocio que podría lanzar de manera realista este verano? Para cada opción, incluya costos de inicio, requisitos de tiempo y los primeros tres pasos para comenzar “.
Este aviso se dirige al elefante en la sala: la mayoría de los empresarios adolescentes tienen dinero y tiempo limitados. Cuando un empresario de 16 años emplea este enfoque para evaluar un concepto de negocio de tarjetas de felicitación, puede descubrir que pueden comenzar con $ 200 y escalar gradualmente. Al ser realistas sobre las limitaciones por adelantado, evitan el exceso de compromiso y pueden construir hacia objetivos de ingresos sostenibles.
Según el informe de Gen Z de Square, el 45% de los jóvenes empresarios usan sus ahorros para iniciar negocios, con el 80% de lanzamiento en línea o con un componente móvil. Estos datos respaldan la efectividad de la planificación basada en restricciones: cuando funcionan los adolescentes dentro de las limitaciones realistas, crean modelos comerciales más sostenibles.
3. El aviso de chatgpt del simulador de voz del cliente
“Actúa como un [specific demographic] Y dame comentarios honestos sobre esta idea de negocio: [describe your concept]. ¿Qué te excitaría de esto? ¿Qué preocupaciones tendrías? ¿Cuánto pagarías de manera realista? ¿Qué necesitaría cambiar para que se convierta en un cliente? “
Los empresarios adolescentes a menudo luchan con la investigación de los clientes porque no pueden encuestar fácilmente a grandes grupos o contratar firmas de investigación de mercado. Este aviso ayuda a simular los comentarios de los clientes haciendo que ChatGPT adopte personas específicas.
Un adolescente que desarrolla un podcast para atletas adolescentes podría usar este enfoque pidiéndole a ChatGPT que responda a diferentes tipos de atletas adolescentes. Esto ayuda a identificar temas de contenido que resuenan y mensajes que se sienten auténticos para el público objetivo.
El aviso funciona mejor cuando se vuelve específico sobre la demografía, los puntos débiles y los contextos. “Actúa como un estudiante de último año de secundaria que solicita a la universidad” produce mejores ideas que “actuar como un adolescente”.
4. El mensaje mínimo de diseñador de prueba viable chatgpt
“Quiero probar esta idea de negocio: [describe concept] sin gastar más de [budget amount] o más de [time commitment]. Diseñe tres experimentos simples que podría ejecutar esta semana para validar la demanda de los clientes. Para cada prueba, explique lo que aprendería, cómo medir el éxito y qué resultados indicarían que debería avanzar “.
Este aviso ayuda a los adolescentes a adoptar la metodología Lean Startup sin perderse en la jerga comercial. El enfoque en “This Week” crea urgencia y evita la planificación interminable sin acción.
Un adolescente que desea probar un concepto de línea de ropa podría usar este indicador para diseñar experimentos de validación simples, como publicar maquetas de diseño en las redes sociales para evaluar el interés, crear un formulario de Google para recolectar pedidos anticipados y pedirles a los amigos que compartan el concepto con sus redes. Estas pruebas no cuestan nada más que proporcionar datos cruciales sobre la demanda y los precios.
5. El aviso de chatgpt del generador de claridad de tono
“Convierta esta idea de negocio en una clara explicación de 60 segundos: [describe your business]. La explicación debe incluir: el problema que resuelve, su solución, a quién ayuda, por qué lo elegirían sobre las alternativas y cómo se ve el éxito. Escríbelo en lenguaje de conversación que un adolescente realmente usaría “.
La comunicación clara separa a los empresarios exitosos de aquellos con buenas ideas pero una ejecución deficiente. Este aviso ayuda a los adolescentes a destilar conceptos complejos a explicaciones convincentes que pueden usar en todas partes, desde las publicaciones en las redes sociales hasta las conversaciones con posibles mentores.
El énfasis en el “lenguaje de conversación que un adolescente realmente usaría” es importante. Muchas plantillas de lanzamiento comercial suenan artificiales cuando se entregan jóvenes fundadores. La autenticidad es más importante que la jerga corporativa.
Más allá de las indicaciones de chatgpt: estrategia de implementación
La diferencia entre los adolescentes que usan estas indicaciones de manera efectiva y aquellos que no se reducen a seguir. ChatGPT proporciona dirección, pero la acción crea resultados.
Los jóvenes empresarios más exitosos con los que trabajo usan estas indicaciones como puntos de partida, no de punto final. Toman las sugerencias generadas por IA e inmediatamente las prueban en el mundo real. Llaman a clientes potenciales, crean prototipos simples e iteran en función de los comentarios reales.
Investigaciones recientes de Junior Achievement muestran que el 69% de los adolescentes tienen ideas de negocios, pero se sienten inciertos sobre el proceso de partida, con el miedo a que el fracaso sea la principal preocupación para el 67% de los posibles empresarios adolescentes. Estas indicaciones abordan esa incertidumbre al desactivar los conceptos abstractos en los próximos pasos concretos.
La imagen más grande
Los emprendedores adolescentes que utilizan herramientas de IA como ChatGPT representan un cambio en cómo está ocurriendo la educación empresarial. Según la investigación mundial de monitores empresariales, los jóvenes empresarios tienen 1,6 veces más probabilidades que los adultos de querer comenzar un negocio, y son particularmente activos en la tecnología, la alimentación y las bebidas, la moda y los sectores de entretenimiento. En lugar de esperar clases de emprendimiento formales o programas de MBA, estos jóvenes fundadores están accediendo a herramientas de pensamiento estratégico de inmediato.
Esta tendencia se alinea con cambios más amplios en la educación y la fuerza laboral. El Foro Económico Mundial identifica la creatividad, el pensamiento crítico y la resiliencia como las principales habilidades para 2025, la capacidad de las capacidades que el espíritu empresarial desarrolla naturalmente.
Programas como WIT brindan soporte estructurado para este viaje, pero las herramientas en sí mismas se están volviendo cada vez más accesibles. Un adolescente con acceso a Internet ahora puede acceder a recursos de planificación empresarial que anteriormente estaban disponibles solo para empresarios establecidos con presupuestos significativos.
La clave es usar estas herramientas cuidadosamente. ChatGPT puede acelerar el pensamiento y proporcionar marcos, pero no puede reemplazar el arduo trabajo de construir relaciones, crear productos y servir a los clientes. La mejor idea de negocio no es la más original, es la que resuelve un problema real para personas reales. Las herramientas de IA pueden ayudar a identificar esas oportunidades, pero solo la acción puede convertirlos en empresas que importan.

Precio
ChatGPT y Gemini tienen versiones gratuitas que limitan su acceso a características y modelos. Los planes premium para ambos también comienzan en alrededor de $ 20 por mes. Las características de chatbot, como investigaciones profundas, generación de imágenes y videos, búsqueda web y más, son similares en ChatGPT y Gemini. Sin embargo, los planes de Gemini pagados también incluyen el almacenamiento en la nube de Google Drive (a partir de 2TB) y un conjunto robusto de integraciones en las aplicaciones de Google Workspace.
Los niveles de más alta gama de ChatGPT y Gemini desbloquean el aumento de los límites de uso y algunas características únicas, pero el costo mensual prohibitivo de estos planes (como $ 200 para Chatgpt Pro o $ 250 para Gemini Ai Ultra) los pone fuera del alcance de la mayoría de las personas. Las características específicas del plan Pro de ChatGPT, como el modo O1 Pro que aprovecha el poder de cálculo adicional para preguntas particularmente complicadas, no son especialmente relevantes para el consumidor promedio, por lo que no sentirá que se está perdiendo. Sin embargo, es probable que desee las características que son exclusivas del plan Ai Ultra de Gemini, como la generación de videos VEO 3.
Ganador: Géminis
Plataformas
Puede acceder a ChatGPT y Gemini en la web o a través de aplicaciones móviles (Android e iOS). ChatGPT también tiene aplicaciones de escritorio (macOS y Windows) y una extensión oficial para Google Chrome. Gemini no tiene aplicaciones de escritorio dedicadas o una extensión de Chrome, aunque se integra directamente con el navegador.

(Crédito: OpenAI/PCMAG)
Chatgpt está disponible en otros lugares, Como a través de Siri. Como se mencionó, puede acceder a Gemini en las aplicaciones de Google, como el calendario, Documento, ConducirGmail, Mapas, Mantener, FotosSábanas, y Música de YouTube. Tanto los modelos de Chatgpt como Gemini también aparecen en sitios como la perplejidad. Sin embargo, obtiene la mayor cantidad de funciones de estos chatbots en sus aplicaciones y portales web dedicados.
Las interfaces de ambos chatbots son en gran medida consistentes en todas las plataformas. Son fáciles de usar y no lo abruman con opciones y alternar. ChatGPT tiene algunas configuraciones más para jugar, como la capacidad de ajustar su personalidad, mientras que la profunda interfaz de investigación de Gemini hace un mejor uso de los bienes inmuebles de pantalla.
Ganador: empate
Modelos de IA
ChatGPT tiene dos series primarias de modelos, la serie 4 (su línea de conversación, insignia) y la Serie O (su compleja línea de razonamiento). Gemini ofrece de manera similar una serie Flash de uso general y una serie Pro para tareas más complicadas.
Los últimos modelos de Chatgpt son O3 y O4-Mini, y los últimos de Gemini son 2.5 Flash y 2.5 Pro. Fuera de la codificación o la resolución de una ecuación, pasará la mayor parte de su tiempo usando los modelos de la serie 4-Series y Flash. A continuación, puede ver cómo funcionan estos modelos en una variedad de tareas. Qué modelo es mejor depende realmente de lo que quieras hacer.
Ganador: empate
Búsqueda web
ChatGPT y Gemini pueden buscar información actualizada en la web con facilidad. Sin embargo, ChatGPT presenta mosaicos de artículos en la parte inferior de sus respuestas para una lectura adicional, tiene un excelente abastecimiento que facilita la vinculación de reclamos con evidencia, incluye imágenes en las respuestas cuando es relevante y, a menudo, proporciona más detalles en respuesta. Gemini no muestra nombres de fuente y títulos de artículos completos, e incluye mosaicos e imágenes de artículos solo cuando usa el modo AI de Google. El abastecimiento en este modo es aún menos robusto; Google relega las fuentes a los caretes que se pueden hacer clic que no resaltan las partes relevantes de su respuesta.
Como parte de sus experiencias de búsqueda en la web, ChatGPT y Gemini pueden ayudarlo a comprar. Si solicita consejos de compra, ambos presentan mosaicos haciendo clic en enlaces a los minoristas. Sin embargo, Gemini generalmente sugiere mejores productos y tiene una característica única en la que puede cargar una imagen tuya para probar digitalmente la ropa antes de comprar.
Ganador: chatgpt
Investigación profunda
ChatGPT y Gemini pueden generar informes que tienen docenas de páginas e incluyen más de 50 fuentes sobre cualquier tema. La mayor diferencia entre los dos se reduce al abastecimiento. Gemini a menudo cita más fuentes que CHATGPT, pero maneja el abastecimiento en informes de investigación profunda de la misma manera que lo hace en la búsqueda en modo AI, lo que significa caretas que se puede hacer clic sin destacados en el texto. Debido a que es más difícil conectar las afirmaciones en los informes de Géminis a fuentes reales, es más difícil creerles. El abastecimiento claro de ChatGPT con destacados en el texto es más fácil de confiar. Sin embargo, Gemini tiene algunas características de calidad de vida en ChatGPT, como la capacidad de exportar informes formateados correctamente a Google Docs con un solo clic. Su tono también es diferente. Los informes de ChatGPT se leen como publicaciones de foro elaboradas, mientras que los informes de Gemini se leen como documentos académicos.
Ganador: chatgpt
Generación de imágenes
La generación de imágenes de ChatGPT impresiona independientemente de lo que solicite, incluso las indicaciones complejas para paneles o diagramas cómicos. No es perfecto, pero los errores y la distorsión son mínimos. Gemini genera imágenes visualmente atractivas más rápido que ChatGPT, pero rutinariamente incluyen errores y distorsión notables. Con indicaciones complicadas, especialmente diagramas, Gemini produjo resultados sin sentido en las pruebas.
Arriba, puede ver cómo ChatGPT (primera diapositiva) y Géminis (segunda diapositiva) les fue con el siguiente mensaje: “Genere una imagen de un estudio de moda con una decoración simple y rústica que contrasta con el espacio más agradable. Incluya un sofá marrón y paredes de ladrillo”. La imagen de ChatGPT limita los problemas al detalle fino en las hojas de sus plantas y texto en su libro, mientras que la imagen de Gemini muestra problemas más notables en su tubo de cordón y lámpara.
Ganador: chatgpt
¡Obtenga nuestras mejores historias!

Toda la última tecnología, probada por nuestros expertos
Regístrese en el boletín de informes de laboratorio para recibir las últimas revisiones de productos de PCMAG, comprar asesoramiento e ideas.
Al hacer clic en Registrarme, confirma que tiene más de 16 años y acepta nuestros Términos de uso y Política de privacidad.
¡Gracias por registrarse!
Su suscripción ha sido confirmada. ¡Esté atento a su bandeja de entrada!
Generación de videos
La generación de videos de Gemini es la mejor de su clase, especialmente porque ChatGPT no puede igualar su capacidad para producir audio acompañante. Actualmente, Google bloquea el último modelo de generación de videos de Gemini, VEO 3, detrás del costoso plan AI Ultra, pero obtienes más videos realistas que con ChatGPT. Gemini también tiene otras características que ChatGPT no, como la herramienta Flow Filmmaker, que le permite extender los clips generados y el animador AI Whisk, que le permite animar imágenes fijas. Sin embargo, tenga en cuenta que incluso con VEO 3, aún necesita generar videos varias veces para obtener un gran resultado.
En el ejemplo anterior, solicité a ChatGPT y Gemini a mostrarme un solucionador de cubos de Rubik Rubik que resuelva un cubo. La persona en el video de Géminis se ve muy bien, y el audio acompañante es competente. Al final, hay una buena atención al detalle con el marco que se desplaza, simulando la detención de una grabación de selfies. Mientras tanto, Chatgpt luchó con su cubo, distorsionándolo en gran medida.
Ganador: Géminis
Procesamiento de archivos
Comprender los archivos es una fortaleza de ChatGPT y Gemini. Ya sea que desee que respondan preguntas sobre un manual, editen un currículum o le informen algo sobre una imagen, ninguno decepciona. Sin embargo, ChatGPT tiene la ventaja sobre Gemini, ya que ofrece un reconocimiento de imagen ligeramente mejor y respuestas más detalladas cuando pregunta sobre los archivos cargados. Ambos chatbots todavía a veces inventan citas de documentos proporcionados o malinterpretan las imágenes, así que asegúrese de verificar sus resultados.
Ganador: chatgpt
Escritura creativa
Chatgpt y Gemini pueden generar poemas, obras, historias y más competentes. CHATGPT, sin embargo, se destaca entre los dos debido a cuán únicas son sus respuestas y qué tan bien responde a las indicaciones. Las respuestas de Gemini pueden sentirse repetitivas si no calibra cuidadosamente sus solicitudes, y no siempre sigue todas las instrucciones a la carta.
En el ejemplo anterior, solicité ChatGPT (primera diapositiva) y Gemini (segunda diapositiva) con lo siguiente: “Sin hacer referencia a nada en su memoria o respuestas anteriores, quiero que me escriba un poema de verso gratuito. Preste atención especial a la capitalización, enjambment, ruptura de línea y puntuación. Dado que es un verso libre, no quiero un medidor familiar o un esquema de retiro de la rima, pero quiero que tenga un estilo de coohes. ChatGPT logró entregar lo que pedí en el aviso, y eso era distinto de las generaciones anteriores. Gemini tuvo problemas para generar un poema que incorporó cualquier cosa más allá de las comas y los períodos, y su poema anterior se lee de manera muy similar a un poema que generó antes.
Recomendado por nuestros editores
Ganador: chatgpt
Razonamiento complejo
Los modelos de razonamiento complejos de Chatgpt y Gemini pueden manejar preguntas de informática, matemáticas y física con facilidad, así como mostrar de manera competente su trabajo. En las pruebas, ChatGPT dio respuestas correctas un poco más a menudo que Gemini, pero su rendimiento es bastante similar. Ambos chatbots pueden y le darán respuestas incorrectas, por lo que verificar su trabajo aún es vital si está haciendo algo importante o tratando de aprender un concepto.
Ganador: chatgpt
Integración
ChatGPT no tiene integraciones significativas, mientras que las integraciones de Gemini son una característica definitoria. Ya sea que desee obtener ayuda para editar un ensayo en Google Docs, comparta una pestaña Chrome para hacer una pregunta, pruebe una nueva lista de reproducción de música de YouTube personalizada para su gusto o desbloquee ideas personales en Gmail, Gemini puede hacer todo y mucho más. Es difícil subestimar cuán integrales y poderosas son realmente las integraciones de Géminis.
Ganador: Géminis
Asistentes de IA
ChatGPT tiene GPT personalizados, y Gemini tiene gemas. Ambos son asistentes de IA personalizables. Tampoco es una gran actualización sobre hablar directamente con los chatbots, pero los GPT personalizados de terceros agregan una nueva funcionalidad, como el fácil acceso a Canva para editar imágenes generadas. Mientras tanto, terceros no pueden crear gemas, y no puedes compartirlas. Puede permitir que los GPT personalizados accedan a la información externa o tomen acciones externas, pero las GEM no tienen una funcionalidad similar.
Ganador: chatgpt
Contexto Windows y límites de uso
La ventana de contexto de ChatGPT sube a 128,000 tokens en sus planes de nivel superior, y todos los planes tienen límites de uso dinámicos basados en la carga del servidor. Géminis, por otro lado, tiene una ventana de contexto de 1,000,000 token. Google no está demasiado claro en los límites de uso exactos para Gemini, pero también son dinámicos dependiendo de la carga del servidor. Anecdóticamente, no pude alcanzar los límites de uso usando los planes pagados de Chatgpt o Gemini, pero es mucho más fácil hacerlo con los planes gratuitos.
Ganador: Géminis
Privacidad
La privacidad en Chatgpt y Gemini es una bolsa mixta. Ambos recopilan cantidades significativas de datos, incluidos todos sus chats, y usan esos datos para capacitar a sus modelos de IA de forma predeterminada. Sin embargo, ambos le dan la opción de apagar el entrenamiento. Google al menos no recopila y usa datos de Gemini para fines de capacitación en aplicaciones de espacio de trabajo, como Gmail, de forma predeterminada. ChatGPT y Gemini también prometen no vender sus datos o usarlos para la orientación de anuncios, pero Google y OpenAI tienen historias sórdidas cuando se trata de hacks, filtraciones y diversos fechorías digitales, por lo que recomiendo no compartir nada demasiado sensible.
Ganador: empate









































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































-
 Startups2 años ago
Startups2 años agoRemove.bg: La Revolución en la Edición de Imágenes que Debes Conocer
-
 Tutoriales2 años ago
Tutoriales2 años agoCómo Comenzar a Utilizar ChatGPT: Una Guía Completa para Principiantes
-
 Startups2 años ago
Startups2 años agoDeepgram: Revolucionando el Reconocimiento de Voz con IA
-
 Startups2 años ago
Startups2 años agoStartups de IA en EE.UU. que han recaudado más de $100M en 2024
-
 Recursos2 años ago
Recursos2 años agoCómo Empezar con Popai.pro: Tu Espacio Personal de IA – Guía Completa, Instalación, Versiones y Precios
-
 Recursos2 años ago
Recursos2 años agoPerplexity aplicado al Marketing Digital y Estrategias SEO
-
 Estudiar IA2 años ago
Estudiar IA2 años agoCurso de Inteligencia Artificial Aplicada de 4Geeks Academy 2024
-
 Noticias2 años ago
Noticias2 años agoDos periodistas octogenarios deman a ChatGPT por robar su trabajo